
mysql 5.7 代价模型浅析
代价精度提升为浮点型 jion计算时不仅要考虑condition,还要考虑condition上的filter,具体参见参数condition_fanout_filter
5.7 在代价类型上分为io,cpu和memory, 5.7的代价模型还在完善中,memory的代价虽然已经收集了,但还没有没有计算在最终的代价中。
5.7 在源码上对代价模型进行了大量重构,代价分为server层和engine层。server层主要是cpu的代价,而engine层主要是io的代价。
5.7 引入了两个系统表mysql.server_cost和mysql.engine_cost来分别配置这两个层的代价。
计算符合条件的行的代价,行数越多,此项代价越大 memory_temptable_create_cost (default 2.0)
内存临时表的创建代价 memory_temptable_row_cost (default 0.2)
内存临时表的行代价 key_compare_cost (default 0.1)
键比较的代价,例如排序 disk_temptable_create_cost (default 40.0)
内部myisam或innodb临时表的创建代价 disk_temptable_row_cost (default 1.0)
内部myisam或innodb临时表的行代价
由上可以看出创建临时表的代价是很高的,尤其是内部的myisam或innodb临时表。
engine_cost io_block_read_cost (default 1.0)从磁盘读数据的代价,对innodb来说,表示从磁盘读一个page的代价 memory_block_read_cost (default 1.0)
从内存读数据的代价,对innodb来说,表示从buffer pool读一个page的代价
目前io_block_read_cost和memory_block_read_cost默认值均为1,实际生产中建议酌情调大memory_block_read_cost,特别是对普通硬盘的场景。
cost参数可以通过修改mysql.server_cost和mysql.engine_cost来实现。初始这两个表中的记录cost_value项均为NULL, 代价值都取上两节介绍的初始值。
当修改cost_value为非NULL时,代价值按设定的值计算。修改方法如下:
# 修改io_block_read_cost值为2 UPDATE mysql.engine_cost SET cost_value = 2.0 WHERE cost_name = io_block_read_cost; #FLUSH OPTIMIZER_COSTS 生效,只对新连接有效,老连接无效。 FLUSH OPTIMIZER_COSTS;
另外,在主备环境下,修改cost参数时主备都要修改。因为mysql.server_cost和mysql.engine_cost的更新不会参与复制。
代价分析示例初始化数据
create table t1(c1 int primary key, c2 int unique,c3 int) engine=innodb; let $loop=100; while($loop) eval insert into t1(c1,c2,c3) values($loop, $loop+1, $loop+2); dec $loop; set optimizer_trace = "enabled=on";
cost参数都取默认值,以下示例中会用到row_evaluate_cost(0.2),io_block_read_cost(1.0),io_block_read_cost(1.0),memory_block_read_cost(1.0)
以下语句选择覆盖索引c2
explain select c1,c2 from t1 where c2 id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE t1 NULL range c2 c2 5 NULL 91 100.00 Using where; Using index
查看optimizer_trace, 可以看出全表扫描代价为23.1,通过c2上的索引扫描代价为19.309, 最后选择c2上的索引扫描。
"rows_estimation": [
"table": "`t1`",
"range_analysis": {
"table_scan": {
"rows": 100,
"cost": 23.1
"potential_range_indexes": [
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
"index": "c2",
"usable": true,
"key_parts": [
"c2"
"best_covering_index_scan": {
"index": "c2",
"cost": 21.109,
"chosen": true
"setup_range_conditions": [
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
"analyzing_range_alternatives": {
"range_scan_alternatives": [
"index": "c2",
"ranges": [
"10 c2"
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": true,
"rows": 91,
"cost": 19.309,
"chosen": true
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "c2",
"rows": 91,
"ranges": [
"10 c2"
"rows_for_plan": 91,
"cost_for_plan": 19.309,
"chosen": true
"considered_execution_plans": [
"plan_prefix": [
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [
"rows_to_scan": 91,
"access_type": "range",
"range_details": {
"used_index": "c2"
"resulting_rows": 91,
"cost": 37.509,
"chosen": true
"condition_filtering_pct": 100,
"rows_for_plan": 91,
"cost_for_plan": 37.509,
"chosen": true
]
全表扫描的代价23.1
包括io和cpu的代价
test_quick_select: double scan_time= cost_model- row_evaluate_cost(static_cast double (records)) + 1; Cost_estimate cost_est= head- file- table_scan_cost(); cost_est.add_io(1.1);//这里加1.1应该是个调节值 cost_est.add_cpu(scan_time);
其中io代价table_scan_cost会根据buffer pool大小和索引大小来估算page in memory和in disk的比例,分别算出代价。
handler::table_scan_cost() ha_innobase::scan_time()*table- cost_model()- page_read_cost(1.0);//1*1=1 //其中scan_time计算数据所占page数,
page_read_cost计算读取单个page的代价
buffer_block_read_cost(pages_in_mem) + io_block_read_cost(pages_on_disk);
io代价为1+1.1=2.1
cpu代价为row_evaluate_cost
double row_evaluate_cost(double rows) const DBUG_ASSERT(m_initialized); DBUG_ASSERT(rows = 0.0); return rows * m_server_cost_constants- row_evaluate_cost(); // 100 * 0.2(row_evaluate_cost)=20; }
cpu代价为20+1=21;
最终代价为2.1+21=23.1
c2索引扫描代价19.309
同样也分为io和cpu代价
multi_range_read_info_const: *cost= index_scan_cost(keyno, static_cast double (n_ranges), static_cast double (total_rows)); cost- add_cpu(cost_model- row_evaluate_cost(static_cast double (total_rows)) + 0.01);
io代价 1.0987925356750823*1=1.0987925356750823
index_scan_cost: const double io_cost= index_only_read_time(index, rows) * //估算index占page个数 = 1.0987925356750823 table- cost_model()- page_read_cost_index(index, 1.0); //根据buffer pool大小和索引大小来估算page in memory和in disk的比例,计算读一个page的代价。 = 1
cpu代价91*0.2+0.01=18.21
cost- add_cpu(cost_model- row_evaluate_cost( static_cast double (total_rows)) + 0.01); //这里根据过滤条件算出的total_rows为91
最终代价1.0987925356750823+18.21=19.309
以下语句选择了全表扫描
explain select * from t1 where c2 id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE t1 NULL ALL c2 NULL NULL NULL 100 91.00 Using where
查看optimizer_trace, 可以看出全表扫描代价为23.1,通过c2上的索引扫描代价为110.21, 最后选择全表扫描。
"rows_estimation": [
"table": "`t1`",
"range_analysis": {
"table_scan": {
"rows": 100,
"cost": 23.1
"potential_range_indexes": [
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
"index": "c2",
"usable": true,
"key_parts": [
"c2"
"setup_range_conditions": [
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
"analyzing_range_alternatives": {
"range_scan_alternatives": [
"index": "c2",
"ranges": [
"10 c2"
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 91,
"cost": 110.21,
"chosen": false,
"cause": "cost"
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
"considered_execution_plans": [
"plan_prefix": [
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [
"rows_to_scan": 100,
"access_type": "scan",
"resulting_rows": 91,
"cost": 21,
"chosen": true
"condition_filtering_pct": 100,
"rows_for_plan": 91,
"cost_for_plan": 21,
"chosen": true
},
全表扫描代价23.1
同上一节分析
c2索引扫描代价为110.21
上一节通过c2索引扫描代价为19.309,因为是覆盖索引不需要回表,所以代价较少。而此例是需要回表的。
multi_range_read_info_const: *cost= read_cost(keyno, static_cast double (n_ranges), static_cast double (total_rows)); cost- add_cpu(cost_model- row_evaluate_cost( static_cast double (total_rows)) + 0.01);
io代价需回表
read_cost: //92*1=92
const double io_cost= read_time(index, static_cast uint (ranges)
static_cast ha_rows (rows)) *
table- cost_model()- page_read_cost(1.0);
read_time: //91+1=92
virtual double read_time(uint index, uint ranges, ha_rows rows)
{ return rows2double(ranges+rows); }
这里回表时计算代价为每行代价为1,默认认为回表时每行都对于聚集索引的一个page.
io代价为92
cpu代价为91*0.2+0.01=18.21
cost- add_cpu(cost_model- row_evaluate_cost( static_cast double (total_rows)) + 0.01);
最后代价为92+18.21=110.21
5.7 代价模型优化还在持续改进中,相信后续的版本会越来越好。代价的参数的配置需谨慎,需要大量的测试和验证。
MySQL 数据库 Schema 设计的性能优化①:高效的模型设计 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区。真正影响性能最大的部分是在设计中就已经产生了的,后期的优化很多时候所能够带来的改善都只是在解决前妻设计所遗留下来的一些问题而已,而且能够解决的问题通常也比较有限。 博主将就如何在 MySQL 数据库 Schema 设计的时候保证尽可能的高效,尽可能减少后期的烦恼会分3篇文章来进行详细介绍!
Mysql 索引模型 B+ 树详解 首先,在了解 mysql 中的 B+ 树之前,我们需要搞懂什么是二叉树。二叉树是一种常见的非线形数据结构,数据是以一对多的形态组织起来的
MySQL 8.0 新的火山模型执行器 # MySQL的总体架构 通常我们认为MySQL的整体架构如下, 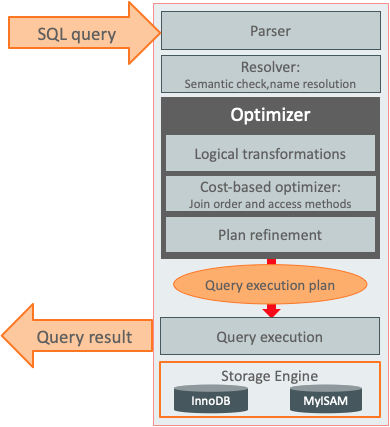 官方10年前开始就一直在致力于优化器代码的重构工作,目的是能确保在SQL的执行过程中有清晰的阶段,包括分离Parse和Resol
从MySQL源码看其网络IO模型 从MySQL源码看其网络IO模型 MySQL是当今最流行的开源数据库,阅读其源码是一件大有裨益的事情(虽然其代码感觉比较凌乱)。而笔者阅读一个Server源码的习惯就是先从其网络IO模型看起。于是,便有了本篇博客。
python的Web框架,Django的ORM,模型基础,MySQL连接配置及增删改查 python的Web框架,Django的ORM,模型基础,MySQL连接配置及增删改查 Django中的ORM简介 ORM概念:对象关系映射(Object Relational Mapping,简称ORM): 用面向对象的方式描述数据库,去操作数据库,甚至可以达到不用编写SQL语句就能够对数据库进行增删改查,进行各种操作。
相关文章
- 【MySQL高级】MySql中常用工具及Mysql 日志
- MySQL数据库表单:浅析其优势(mysql数据库表单)
- 载MySQL数据库安装步骤:快速下载安装(mysql下)
- Mysql:一步一步指导MySQL安装版:一步一步指引安装(mysql安装版安装)
- 浅析MySQL中删除某条数据的方法(mysql删除某条数据)
- MySQL灾难恢复:重获数据库完整性(mysql灾难恢复)
- 极速搭建MySQL:阿里云带你走(阿里云搭建mysql)
- MySQL模型:开发表格结构的核心(mysql模型)
- 构建MySQL数据库模型来增强数据存储性能(数据库建模mysql)
- MySQL远程使用:掌握基础知识,远程操作Mysql数据库。(mysql远程使用)
- MySQL使用详解:全面学习MYSQL技术(mysql大全)
- 教你轻松修改MySQL引擎快速实现数据库性能优化(mysql中修改引擎)
- MySQL中SYNC数据同步的重要性与方法浅析(mysql中sync)
- 深入解析MySQL中的Models模型(mysql中models)
- MySQL如何进行两表相连查询(mysql 两表相连查询)
- 如何从命令行启动MySQL(cmd里面启动mysql)
- MySQL在Beedb中的应用(beedb mysql)
- MySQL中查询BAT工具的使用(bat mysql 查询)
- MySQL创建表示例快速掌握MYSQL基础操作(mysql中创建表的例子)
- MySQL删除三种技巧浅析(mysql 三种删除方式)
- 基于MySQL的主从复制原理进行Redis的数据备份(主从复制到redis)
- GET MYSQL 免费下载并破解MySQL数据库软件(mysql下载和破解)
- MySQL如何创建用户(mysql下怎么建立用户)
- 易受攻击MySQL 安全问题无密码访问问题浅析(mysql不用密码就访问)
- MySQL轻松应对一万条记录的管理(mysql一万条记录)