
【目标检测】48、YOLOv5 | 可方便工程部署的 YOLO 网络
文章目录
论文:暂无
代码:https://github.com/ultralytics/yolov5
官方介绍:https://docs.ultralytics.com/
出处:ultralytics 公司
时间:2020.05
YOLOv5 是基于 YOLOv3 改进而来,体积小,YOLOv5 s的权重文件为27MB。
YOLOv4(Darknet架构)的权重文件为244MB。YOLOv5比YOLOv4小近90%。这意味着YOLOv5可以更轻松地部署到嵌入式设备。
此外,因为YOLOv5 是在 PyTorch 中实现的,所以它受益于已建立的 PyTorch 生态系统
YOLOv5 还可以轻松地编译为 ONNX 和 CoreML,因此这也使得部署到移动设备的过程更加简单。
YOLOv5 家族:
- YOLOv5x(最大的模型)
- YOLOv5l
- YOLOv5m
- YOLOv5s(最小的模型)
YOLOv5 优势:
- 使用PyTorch进行编写。
- 可以轻松编译成ONNX和CoreML。
- 速度极快,每秒140FPS。
- 精度超高,可以达到0.895mAP。
- 体积很小:27M。
- 集成了YOLOv3-spp和YOLOv4部分特性
一、数据准备
1.1 YOLOv5 的数据格式
可以下载 coco8 来查看 YOLOv5 需要的具体格式
- images
- train
- img1.jpg
- val
- img2.jpg
- labels
- train
- img1.txt
- val
- img2.txt
- README.txt
- coco8.yaml
其中,labels 中的 txt 内容示例如下:
类别 x_center y_center width height
45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.0969375
49 0.773148 0.129802 0.0907344 0.0972292
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.0792187 0.148063 0.148062
上面的 5 列数据分别表示框的类别编号(coco 中的类别编号)、框中心点 x 坐标,框中心点 y 坐标,框宽度 w,框高度 h
框的坐标参数如何从 COCO 格式 (x_min, y_min, w, h) 转换为 YOLO 可用的格式 (x_center, y_center, w, h):
- YOLO 中的所有坐标参数都要归一化到 (0, 1) 之间,如下图所示
x_center和width如何从坐标点转换为 0~1 的参数:x_center = x_coco/img_witdh,width = width_coco/img_widthy_center和height如何从坐标点转换为 0~1 的参数:y_center = y_coco/img_height,height = height_coco/img_height

coco8.yaml 内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
...
77: teddy bear
78: hair drier
79: toothbrush
下面展示一个方便展示的 coco6 来看看具体形式:
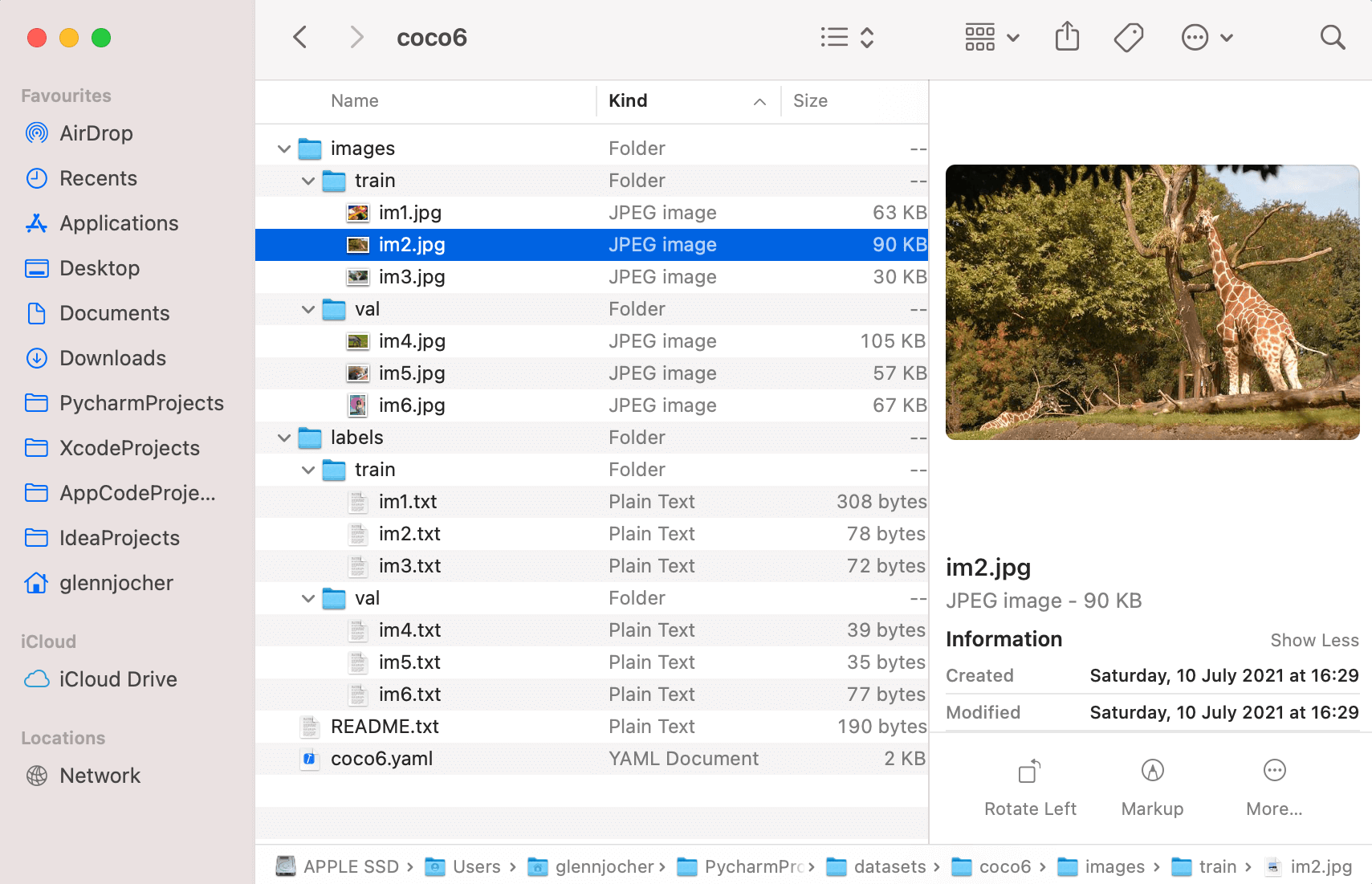
1.2 COCO 的数据格式
coco 的数据标注格式如下:
其中 bbox 对应的四个值分别为: [x_min, y_min, w, h],即左上角点和宽高
{
'segmentation': [[510.66, 423.01, 511.72, 420.03, 510.45, 416.0, 510.34, 413.02, 510.77, 410.26, 510.77, 407.5, 510.34, 405.16, 511.51, 402.83, 511.41, 400.49, 510.24, 398.16, 509.39, 397.31, 504.61, 399.22, 502.17, 399.64, 500.89, 401.66, 500.47, 402.08, 499.09, 401.87, 495.79, 401.98, 490.59, 401.77, 488.79, 401.77, 485.39, 398.58, 483.9, 397.31, 481.56, 396.35, 478.48, 395.93, 476.68, 396.03, 475.4, 396.77, 473.92, 398.79, 473.28, 399.96, 473.49, 401.87, 474.56, 403.47, 473.07, 405.59, 473.39, 407.71, 476.68, 409.41, 479.23, 409.73, 481.56, 410.69, 480.4, 411.85, 481.35, 414.93, 479.86, 418.65, 477.32, 420.03, 476.04, 422.58, 479.02, 422.58, 480.29, 423.01, 483.79, 419.93, 486.66, 416.21, 490.06, 415.57, 492.18, 416.85, 491.65, 420.24, 492.82, 422.9, 493.56, 424.39, 496.43, 424.6, 498.02, 423.01, 498.13, 421.31, 497.07, 420.03, 497.07, 415.15, 496.33, 414.51, 501.1, 411.96, 502.06, 411.32, 503.02, 415.04, 503.33, 418.12, 501.1, 420.24, 498.98, 421.63, 500.47, 424.39, 505.03, 423.32, 506.2, 421.31, 507.69, 419.5, 506.31, 423.32, 510.03, 423.01, 510.45, 423.01]],
'area': 702.1057499999998,
'iscrowd': 0,
'image_id': 289343,
'bbox': [473.07, 395.93, 38.65, 28.67],
'category_id': 18,
'id': 1768
}
下面的代码可以实现将 COCO 数据标注格式转换为 YOLOv5 需要的训练格式:
import os
import json
from pathlib import Path
def coco2yolov5(coco_json_path, yolo_txt_path):
with open(coco_json_path, 'r') as f:
info = json.load(f)
coco_anno = info["annotations"]
coco_images = info["images"]
for img in coco_images:
img_info = {
"file_name": img["file_name"],
"img_id": img["id"],
"img_width": img["width"],
"img_height": img["height"]
}
for anno in coco_anno:
image_id = anno["image_id"]
category_id = anno["category_id"]
bbox = anno["bbox"]
line = str(category_id - 1)
if image_id == img_info["img_id"]:
txt_name = Path(img_info["file_name"]).name.split('.')[0]
yolo_txt = yolo_txt_path + '{}.txt'.format(txt_name)
with open(yolo_txt, 'a') as wf:
# coco: [x_min, y_min, w, h]
yolo_bbox = []
yolo_bbox.append(round((bbox[0] + bbox[2]) / img_info["img_width"], 6))
yolo_bbox.append(round((bbox[1] + bbox[3]) / img_info["img_height"], 6))
yolo_bbox.append(round(bbox[2] / img_info["img_width"], 6))
yolo_bbox.append(round(bbox[3] / img_info["img_height"], 6))
for bbox in yolo_bbox:
line += ' ' + str(bbox)
line += '\n'
wf.writelines(line)
if __name__ == "__main__":
coco_json_path = "part1_all_coco.json"
yolo_txt_path = "val/"
if not os.path.exists(yolo_txt_path):
os.makedirs(yolo_txt_path)
coco2yolov5(coco_json_path, yolo_txt_path)
二、YOLOv5 结构介绍
此处所说 YOLOv5 为 v6.0 版本,没有 Focus 了,替换成 conv 了,使用 SPPF 代替了 SPP
YOLOv5 模型一共有 4 个版本,分别为:
- YOLOv5s:depth_factor:0.33,widen_factor:0.50 (深度、宽度最小,后面的逐渐加大)
- YOLOv5m:depth_factor:0.67,widen_factor:0.75
- YOLOv5l:depth_factor:1,widen_factor:1
- YOLOv5x:depth_factor:1.33,widen_factor:1.25

- deepen_factor:主要控制 stage 的个数
- widen_factor:主要控制输入输出 channel 的个数
# 下面的 layer 是 csp_darknet 中摘出的一部分代码,主要可以看看 deepen_factor 和 widen_factor 在哪里用到了
def build_stage_layer(self, stage_idx: int, setting: list) -> list:
"""Build a stage layer.
Args:
stage_idx (int): The index of a stage layer.
setting (list): The architecture setting of a stage layer.
"""
in_channels, out_channels, num_blocks, add_identity, use_spp = setting
in_channels = make_divisible(in_channels, self.widen_factor)
out_channels = make_divisible(out_channels, self.widen_factor)
num_blocks = make_round(num_blocks, self.deepen_factor)
stage = []
conv_layer = ConvModule(
in_channels,
out_channels,
kernel_size=3,
stride=2,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
stage.append(conv_layer)
csp_layer = CSPLayer(
out_channels,
out_channels,
num_blocks=num_blocks,
add_identity=add_identity,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
stage.append(csp_layer)
if use_spp:
spp = SPPFBottleneck(
out_channels,
out_channels,
kernel_sizes=5,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
stage.append(spp)
return stage
YOLOv5 的框架结构如下:
- Bckbone:CSPDarkNet
- Neck:PA-FPN
- Head:三种尺度,每个尺度的每个特征点上放置 3 种 anchor
下图为原创,如有引用请注明出处。
YOLOv5 模型框架如下:
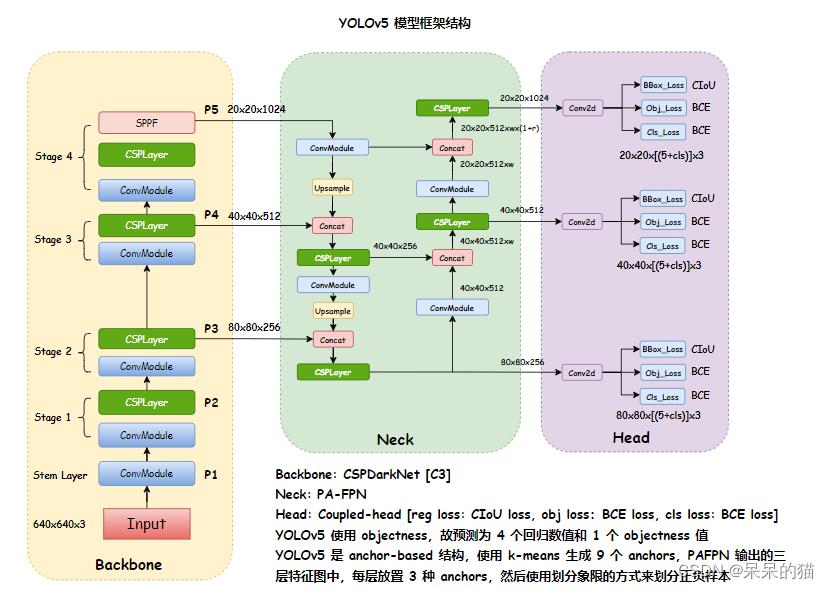
YOLOv5 模块细节如下:
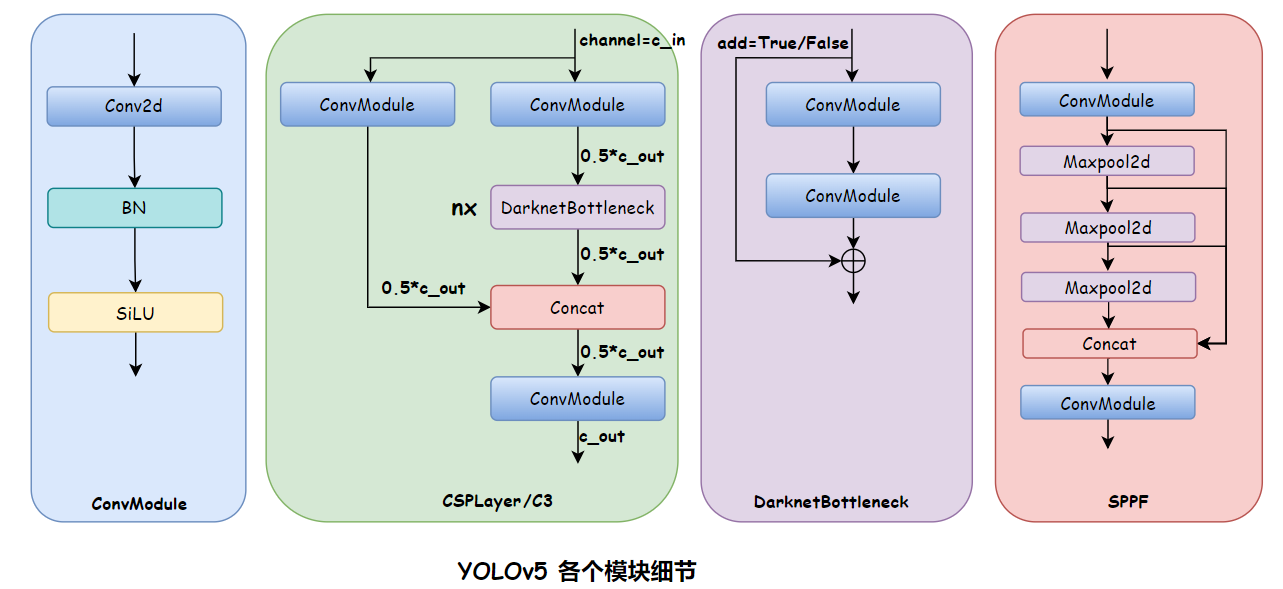
2.1 Backbone
CSPDarkNet
下面代码均出自 MMYOLO
YOLOv5-s 的 config 的 model 内容如下:
deepen_factor = 0.33
widen_factor = 0.5
model = dict(
type='YOLODetector',
data_preprocessor=dict(
type='mmdet.DetDataPreprocessor',
mean=[0., 0., 0.],
std=[255., 255., 255.],
bgr_to_rgb=True),
backbone=dict(
type='YOLOv5CSPDarknet',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=[256, 512, 1024],
out_channels=[256, 512, 1024],
num_csp_blocks=3,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
num_classes=num_classes,
in_channels=[256, 512, 1024],
widen_factor=widen_factor,
featmap_strides=strides,
num_base_priors=3),
prior_generator=dict(
type='mmdet.YOLOAnchorGenerator',
base_sizes=anchors,
strides=strides),
# scaled based on number of detection layers
loss_cls=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=0.5 * (num_classes / 80 * 3 / num_det_layers)),
loss_bbox=dict(
type='IoULoss',
iou_mode='ciou',
bbox_format='xywh',
eps=1e-7,
reduction='mean',
loss_weight=0.05 * (3 / num_det_layers),
return_iou=True),
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=1.0 * ((img_scale[0] / 640)**2 * 3 / num_det_layers)),
prior_match_thr=4.,
obj_level_weights=[4., 1., 0.4]),
test_cfg=dict(
multi_label=True,
nms_pre=30000,
score_thr=0.001,
nms=dict(type='nms', iou_threshold=0.65),
max_per_img=300))
YOLOv5 框架结构:
如何查看模型结构呢:
在 tools/train.py 的 line 109 后面打上断点:
else:
# build customized runner from the registry
# if 'runner_type' is set in the cfg
runner = RUNNERS.build(cfg)
import pdb; pdb.set_trace()
# start training
runner.train()
然后在终端输入 runner.model 即可拿到模型的结构,由于模型过长,这里简洁整理:
YOLODetector(
(data_preprocessor): YOLOv5DetDataPreprocessor()
(backbone): YOLOv5CSPDarknet()
(neck): YOLOv5PAFPN()
(bbox_head): YOLOv5Head()
)
Backbone 如下:
(backbone): YOLOv5CSPDarknet(
(stem): conv(in=3, out=32, size=6x6, s=2, pading=2) + BN + SiLU
(stage1): conv(in=32, out=64, size=3X3, s=2, pading=1) + BN + SiLU
CSPLayer:conv(in=64, out=32, size=1x1, s=1) + BN + SiLU
conv(in=64, out=32, size=1x1, s=1) + BN + SiLU
conv(in=64, out=64, size=1x1, s=1) + BN + SiLU
DarknetBottleNeck0:conv(in=32, out=32, size=1x1, s=1) + BN + SiLU
conv(in=32, out=32, size=3x3, s=1, padding=1) + BN + SiLU
(stage2): conv(in=64, out=128, size=3X3, s=2, pading=1) + BN + SiLU
CSPLayer:conv(in=128, out=64, size=1x1, s=1) + BN + SiLU
conv(in=128, out=64, size=1x1, s=1) + BN + SiLU
conv(in=128, out=128, size=1x1, s=1) + BN + SiLU
DarknetBottleNeck0:conv(in=64, out=64, size=1x1, s=1) + BN + SiLU
conv(in=64, out=64, size=3x3, s=1, padding=1) + BN + SiLU
DarknetBottleNeck1:conv(in=64, out=64, size=1x1, s=1) + BN + SiLU
conv(in=64, out=64, size=3x3, s=1, padding=1) + BN + SiLU
(stage3): conv(in=128, out=256, size=3X3, s=2, pading=1) + BN + SiLU
CSPLayer:conv(in=256, out=128, size=1x1, s=1) + BN + SiLU
conv(in=256, out=128, size=1x1, s=1) + BN + SiLU
conv(in=256, out=128, size=1x1, s=1) + BN + SiLU
DarknetBottleNeck0:conv(in=128, out=128, size=1x1, s=1) + BN + SiLU
conv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU
DarknetBottleNeck1:conv(in=128, out=128, size=1x1, s=1) + BN + SiLU
conv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU
DarknetBottleNeck2:conv(in=128, out=128, size=1x1, s=1) + BN + SiLU
conv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU
(stage4): conv(in=256, out=512, size=3X3, s=2, pading=1) + BN + SiLU
CSPLayer:conv(in=512, out=256, size=1x1, s=1) + BN + SiLU
conv(in=512, out=256, size=1x1, s=1) + BN + SiLU
conv(in=512, out=512, size=1x1, s=1) + BN + SiLU
DarknetBottleNeck0:conv(in=256, out=256, size=1x1, s=1) + BN + SiLU
conv(in=256, out=256, size=3x3, s=1, padding=1) + BN + SiLU
SPPF:conv(in=512, out=256, size=1x1, s=1) + BN + SiLU
maxpooling(size=5x5, s=1, padding=2, dilation=1)
conv(in=1024, out=512, size=1x1, s=1, padding=1) + BN + SiLU
整个模型框架结构如下:
(backbone): YOLOv5CSPDarknet(
(stem): ConvModule(
(conv): Conv2d(3, 32, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(stage1): Sequential(
(0): ConvModule(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
)
(stage2): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(1): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
)
(stage3): Sequential(
(0): ConvModule(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(1): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(2): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
)
(stage4): Sequential(
(0): ConvModule(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
(2): SPPFBottleneck(
(conv1): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(poolings): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
(conv2): ConvModule(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
(neck): YOLOv5PAFPN(
(reduce_layers): ModuleList(
(0): Identity()
(1): Identity()
(2): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(upsample_layers): ModuleList(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): Upsample(scale_factor=2.0, mode=nearest)
)
(top_down_layers): ModuleList(
(0): Sequential(
(0): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
(1): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
)
(downsample_layers): ModuleList(
(0): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
(bottom_up_layers): ModuleList(
(0): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
(1): CSPLayer(
(main_conv): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(short_conv): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(final_conv): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(blocks): Sequential(
(0): DarknetBottleneck(
(conv1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
(conv2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(activate): SiLU(inplace=True)
)
)
)
)
)
(out_layers): ModuleList(
(0): Identity()
(1): Identity()
(2): Identity()
)
)
(bbox_head): YOLOv5Head(
(head_module): YOLOv5HeadModule(
(convs_pred): ModuleList(
(0): Conv2d(128, 18, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 18, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 18, kernel_size=(1, 1), stride=(1, 1))
)
)
(loss_cls): CrossEntropyLoss(avg_non_ignore=False)
(loss_bbox): IoULoss()
(loss_obj): CrossEntropyLoss(avg_non_ignore=False)
)
)
2.2 Neck
CSP-PAFPN
SPP 和 SPPF:
- SPP:Spatial Pyramid Poolig,是空间金字塔池化,并行的使用不同大小的池化方式,然后将得到的 maxpooling 输出特征图 concat 起来
- SPPF:Spatial Pyramid Poolig Fast,是空间金字塔池化的快速版本,计算量变小的,使用串行的方式,下一个 maxpooling 接收的是上一个 maxpooling 的输出,然后将所有 maxpooling 的输出 concat 起来
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
2.3 Head
YOLOv5 的输出如下:
- 80x80x((5+Ncls)x3):每个特征点上都有 4 个 reg、1 个 置信度、Ncls 个类别得分
- 40x40x((5+Ncls)x3)
- 20x20x((5+Ncls)x3)
YOLOv5 中的 anchor:
# coco 初始设定 anchor 的宽高如下,每个尺度的 head 上放置 3 种 anchor
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
如何放置 anchor:
- 在 8 倍下采样特征图上(80x80)的每个特征点,分别放置宽高为 (10, 13)、(16, 30)、(33,23) 的 3 种 anchors
- 在 16 倍下采样特征图上(40x40)的每个特征点,分别放置宽高为 (30, 61)、(62, 45)、(59, 119) 的 3 种 anchors
- 在 32 倍下采样特征图上(20x20)的每个特征点,分别放置宽高为 (116, 90)、(156, 198)、(373,326) 的 3 种 anchors
如何进行 anchor 正负的分配:
YOLOv5 是 anchor-based ,一个 gt 由多个特征层中的多个 grid 来负责(一个 gt 可以有 [0, 27] 个 anchors 负责)
- YOLOv5 没有使用 IoU 匹配原则,而是采用了 anchor 和 gt 的宽高比匹配度作为划分规则,同时引入跨邻域网格策略来增加正样本。YOLOv5 不限制每个 gt 只能由某一层的特征图来负责,只要宽高比满足阈值的 anchor,都可以对该 gt 负责。也就是说,YOLOv5 中,一个 gt 可以由多层特征和多个网格来负责,一个 gt 可以对应 [0, 27] 个 anchors。
- 主要包括如下两个核心步骤:
- 首先,统计这些比例和它们倒数之间的最大值,这里可以理解成计算 gt 和 anchor 分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小),宽度比例计算如下的值,如果
r
m
a
x
<
a
n
c
h
o
r
t
h
r
r^{max} < anchor_{thr}
rmax<anchorthr(默认
a
n
c
h
o
r
t
h
r
anchor_{thr}
anchorthr 为 4),则判定为正样本,即符合宽高比阈值条件的 anchor 判定为该 gt 的正样本,不符合条件的 anchor 判定为该 gt 的负样本。
- r w = w g t / w a n c h o r r_w = w_{gt} / w_{anchor} rw=wgt/wanchor, r h = h g t / h a n c h o r r_h = h_{gt} / h_{anchor} rh=hgt/hanchor
- r w m a x = m a x { r w , 1 / r w } r_w^{max} = max\{r_w, 1/r_w\} rwmax=max{rw,1/rw}, r h m a x = m a x { r h , 1 / r h } r_h^{max} = max\{r_h, 1/r_h\} rhmax=max{rh,1/rh}
- r m a x = m a x ( r w m a x , r h m a x ) r^{max} = max(r_w^{max}, r_h^{max}) rmax=max(rwmax,rhmax)
- 然后,如果 gt 的中心点落入了某个 grid 的第三象限(grid 是投影到原图中来看的,所以是一个图像块,而非输出 head 特征图上的一个点),则该 grid 的右边和下边的 grid 中,和第一步匹配到的 anchor 的长宽相同的 anchors 也作为正样本。其他三个象限同理,一象限对应左和上,二象限对应上和右,三象限对应右和下,四象限对应左和下。
- 首先,统计这些比例和它们倒数之间的最大值,这里可以理解成计算 gt 和 anchor 分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小),宽度比例计算如下的值,如果
r
m
a
x
<
a
n
c
h
o
r
t
h
r
r^{max} < anchor_{thr}
rmax<anchorthr(默认
a
n
c
h
o
r
t
h
r
anchor_{thr}
anchorthr 为 4),则判定为正样本,即符合宽高比阈值条件的 anchor 判定为该 gt 的正样本,不符合条件的 anchor 判定为该 gt 的负样本。

三、YOLOv5 的训练过程
训练过程:
- 输入图像经过 backbone+neck+head,输出三种不同尺度的 head 特征图(80x80,40x40,20x20)
- 在这三种不同尺度的特征图上分别布置三个不同宽高比的 anchor(由 k-means 得到的 anchors)
- 对每个 gt,根据正负样本分配规则来分配 anchors
- 对正样本,计算分类、回归、obj loss
YOLOv5 的 loss 总共包含 3 个,分别为:
- Classes loss:使用的是 BCE loss,计算所有正负样本的分类损失
- Objectness loss:使用的是 BCE loss,计算所有正负样本的 obj 损失,注意这里的 obj 指的是网络预测的目标边界框与 GT Box 的 CIoU
- Location loss:使用的是 CIoU loss,只计算正样本的定位损失
三个 loss 按照一定比例汇总: L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss=\lambda_1L_{cls}+\lambda_2L_{obj}+\lambda_3L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
P3、P4、P5 层对应的 Objectness loss 按照不同权重进行相加:
L
o
b
j
=
4.0
⋅
L
o
b
j
s
m
a
l
l
+
1.0
⋅
L
o
b
j
m
e
d
i
u
m
+
0.4
⋅
L
o
b
j
l
a
r
g
e
L_{obj}=4.0\cdot L_{obj}^{small}+1.0\cdot L_{obj}^{medium}+0.4\cdot L_{obj}^{large}
Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
四、YOLOv5 的预测过程
-
将输入图像经过 backbone+neck+head,输出三种不同尺度的 head 特征图(80x80,40x40,20x20)
-
第一次阈值过滤:用 score_thr 对类别预测分值进行阈值过滤,去掉低于 score_thr 的预测结果
-
第二次阈值过滤: 将 obj 预测分值和过滤后的类别预测分值相乘,然后依然采用 score_thr 进行阈值过滤
-
还原到原图尺度并进行 NMS: 将前面两次过滤后剩下的检测框还原到网络输出前的原图尺度,然后进行 NMS 即可。这里的 NMS 可以使用普通 NMS,也可以使用 DIoU-NMS,同时考虑 IoU 和两框中心点的距离,能保留更多 IoU 大但中心点距离远的情况,有助于遮挡漏检问题的缓解。
四、如何在 YOLOv5 官方代码(非 MMYOLO)中添加 Swin 作为 backbone
1、修改 yolox.yaml 为 yolox_swin_transformer.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3STR, [128]], # 注意📢,yaml 主要就将 C3 修改为 C3STR
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3STR, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3STR, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3STR, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2、在 models/common.py 中添加 swin transformer 模块
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class SwinTransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
#print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SwinTransformerLayer(nn.Module):
def __init__(self, dim, num_heads, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size!=0 or W_ % self.window_size!=0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
class C3STR(C3):
# C3 module with SwinTransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
3、修改 models/yolo.py 的 parse_model 函数
添加 C3STR
相关文章
- VirtualBox安装Proxmox VE之后与宿主机之间的网络配置示例
- SAN(存储区域网络),WWN, WWPN,WWNN区别
- packetfence 7.2网络准入部署(一)
- packetfence 7.2网络准入部署(二)
- 设置网络优先级
- 小脚本一则---CDH的批量部署中,如果是从ESXI的VCENTER的模板生成的虚拟机,如何快速搞定网络网络卡配置?
- vmware centos7 网络配置
- 《android开发进阶从小工到专家》读书笔记--HTTP网络请求
- python_网络编程初探(cs架构+TCP协议)
- VXLAN配置实例(四)——VXLAN多租户网络隔离
- Ubuntu安装好后,没有网络怎么办?
- Interview:算法岗位面试—10.24下午—上海某软件公司(机器学习,上市)电话面试—考察SVM、逻辑回归、降低过拟合、卷积网络基础等
- 《跟唐老师学习云网络》 - ip命令
- 无法设置 / 添加网络打印机?报错 无法保持设置?
- 【C++进阶】详解C++开源网络传输库libcurl的编译过程
- 理解dropout——本质是通过阻止特征检测器的共同作用来防止过拟合 Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
- 思科网络部署,(0基础)入门实验,超详细
- 使用生成对抗网络进行端到端中国山水画创作(SAPGAN)
- 基于深度学习的三维重建网络PatchMatchNet(一):PatchMatchNet论文解读及传统方法介绍