
【项目实战】并发编程之线程池(ExecutorService接口与Executors)入门介绍
一、Java线程池
1.1 Java线程池是什么?
在Java中,线程池是一种常见的并发编程模型
Java线程池是Java应用程序中管理线程的强大工具。
1.2 使用Java线程池的好处
- 可以重复利用已经创建的线程,避免了线程的创建和销毁的开销
- 控制线程的数量,避免了线程数量过多导致的系统资源浪费和性能下降。
- 可以提高程序的性能和可伸缩性。
- 提供了一种重用线程和限制创建的线程数量的方法,可以提高性能并减少资源使用。
二、Executor接口
Executor是Java中用于管理线程池的框架。
它提供了一种简单的方式来管理线程池,从而使并发编程更加容易。
使用Executor,您可以将任务提交到线程池中,线程池会自动分配线程来执行这些任务。这样,您就可以避免手动创建和管理线程,从而简化了并发编程的复杂性。
三、ExecutorService接口
ExecutorService是Executor的子接口,它提供了更多的方法来管理线程池。
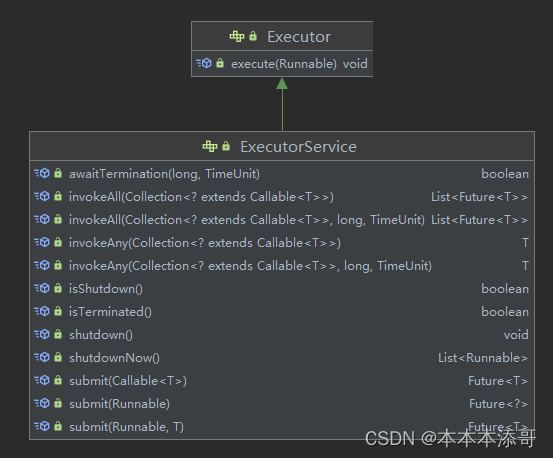
在Java中,线程池由ExecutorService接口表示,它是Java中用于管理线程池的接口。
该接口提供了一种提交任务到线程池并管理用于执行这些任务的线程的方法。
它提供了一种简单的方式来管理线程池,可以方便地创建、启动和停止线程池中的线程。
2.1 ExecutorService接口的核心API
ExecutorService接口提供了以下几个方法:
- submit(Runnable task):提交一个Runnable任务给线程池执行,并返回一个Future对象,可以用来获取任务的执行结果;
- submit(Callable> task):提交一个Callable任务给线程池执行,并返回一个Future对象,可以用来获取任务的执行结果;
- shutdown():停止线程池,等待所有任务执行完毕后关闭线程池;
- shutdownNow():立即停止线程池,尝试中断所有正在执行的任务,并返回未执行的任务列表。
2.2 使用ExecutorService接口的基本步骤
以下是使用ExecutorService接口的基本步骤:
- 创建一个ExecutorService对象。
- 创建一个Runnable对象,该对象表示要执行的任务。
- 将Runnable对象提交到ExecutorService中。
- 当任务完成时,ExecutorService会自动将线程返回到线程池中。
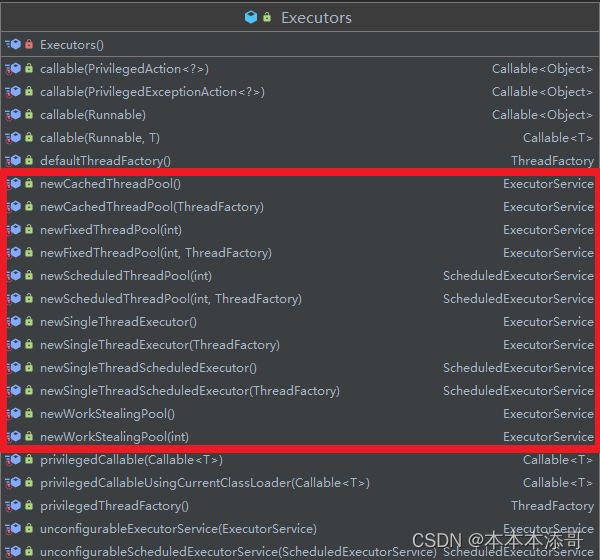
三、Executors类
要创建线程池,可以使用Executors类,该类提供了几个工厂方法来创建不同类型的线程池。
3.1 创建不同类型的线程池
四、线程池示例代码 - 创建一个最大为10个线程的固定大小线程池
例如,要创建一个最大为10个线程的固定大小线程池,可以使用以下代码:
ExecutorService executor = Executors.newFixedThreadPool(10);
完整代码如下
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 100; i++) {
executorService.submit(new Task(i));
}
executorService.shutdown();
}
static class Task implements Runnable {
private int taskId;
public Task(int taskId) {
this.taskId = taskId;
}
@Override
public void run() {
System.out.println("Task " + taskId + " is running.");
}
}
}
在上面的代码中,
使用Executors.newFixedThreadPool(10)创建了一个固定大小为10的线程池
然后提交了100个任务给线程池执行。
每个任务都是一个Task对象,实现了Runnable接口,当任务执行时,会输出一条日志。
五、项目实战
5.1 计算整数数组总和
Lambda表达式也可以与java.util.concurrent包一起使用,以创建可以并行执行的任务。
例如,可以使用lambda表达式创建Callable或Runnable任务,并将其提交给ExecutorService以进行执行。
以下是使用lambda表达式创建计算整数数组总和的Callable任务的示例:
int[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
Callable<Integer> task = () -> {
int sum = 0;
for (int i : array) {
sum += i;
}
return sum;
};
ExecutorService executor = Executors.newFixedThreadPool(1);
Future<Integer> future = executor.submit(task);
int result = future.get();
System.out.println(result); // 输出55
在此示例中,使用lambda表达式创建了一个Callable任务,该任务计算array变量中元素的总和。
然后使用ExecutorService将任务提交进行执行,并使用Future接口检索任务的结果。
5.2 提交给情景处理线程池处理
定时任务到时间到,提交给情景处理线程池处理
@Getter
@Component
public class ServiceFactory {
// 处理推送场景的线程池
private ExecutorService threadPool = Executors.newFixedThreadPool(30);
}
@KafkaListener(topics = { Const.INTERNAL_TOPIC_DEV_BOOT }, groupId = "blue-birthdaycare-1")
public void listenBirthdayCare(ConsumerRecord<?, String> record) {
String bootInfo = record.value();
log.info("生日关怀推送{},收到开机上传信息:{}", Const.INTERNAL_TOPIC_DEV_BOOT, bootInfo);
// 推送逻辑
serviceFactory.getThreadPool().submit(() -> process(bootInfo));
}
@KafkaListener(topics = {Const.INTERNAL_TOPIC_ENDURANCE}, groupId = "blue-endurancealert-strategy")
public void enduranceAlertStrategy(ConsumerRecord<?, String> record) {
String value = record.value();
log.debug("剩余续航里程提示场景,收到剩余续航里程数据信息=[{}]", value);
serviceFactory.getThreadPool().submit(() -> enduranceAlertProcess(value, null));
}
@KafkaListener(topics = {Const.INTERNAL_TOPIC_HIGHSPEED}, groupId = "blue-highspeed-strategy")
public void highspeedStrategy(ConsumerRecord<?, String> record) {
String value = record.value();
log.debug("当前高速模式场景,收到车速信息=[{}]", value);
serviceFactory.getThreadPool().submit(() -> highspeedProcess(value, null));
}
@KafkaListener(topics = {Const.INTERNAL_TOPIC_GPSINFO}, groupId = "blue-destination-scenery")
public void targetSceneryStrategy(ConsumerRecord<?, String> record) {
String value = record.value();
log.debug("目的地景点推荐场景,收到GPS位置信息=[{}]", value);
serviceFactory.getThreadPool().submit(() -> targetSceneryProcess(value, null));
}
@KafkaListener(topics = { Const.INTERNAL_TOPIC_GPSINFO }, groupId = "blue-vehiclefault-strategy")
public void currentPositionStrategy(ConsumerRecord<?, String> record) {
String value = record.value();
log.debug("车身故障场景,收到GPS位置信息=[{}]", value);
serviceFactory.getThreadPool().submit(() -> sceneProcess(value, null));
}
@KafkaListener(topics = {Const.WEATHER_ALERT_TOPIC}, groupId = "blue-weather-alert")
public void listenWeatherAlert(ConsumerRecord<?, String> record) {
String value = record.value();
log.info("恶劣天气{}:收到天气预警:{}", Const.WEATHER_ALERT_TOPIC, value);
WeatherAlertPushReq.WeatherAlertPushReqBody alertInfo = JSONUtil.toBean(value, WeatherAlertPushReq.WeatherAlertPushReqBody.class);
Runnable process = () -> processByAlertInfo(alertInfo);
serviceFactory.getThreadPool().submit(SvFunctionUtil.wrapperFunction(process, "恶劣天气预警(墨迹推送)"));
}
5.3 异步执行,否则超时会有重复消费的风险
@Component
@Slf4j
public class DevInfoMonitor {
@Autowired
private ServiceFactory serviceFactory;
private ExecutorService fixedThreadPool = Executors.newFixedThreadPool(4);
@KafkaListener(topics = Const.INTERNAL_TOPIC_GPSINFO, groupId = "monitor-3")
public void gpsInfoMonitor(ConsumerRecord<?, String> record) {
String gpsInfo = record.value();
log.debug("gpsInfoMonitor gps上报信息{}", gpsInfo);
Runnable process = () -> {
JSONObject object = new JSONObject(gpsInfo);
String deviceId = object.getStr("deviceId");
String lon = object.getStr("lon");
String lat = object.getStr("lat");
if (StrUtil.isBlank(deviceId) || StrUtil.isBlank(lon) || StrUtil.isBlank(lat)) {
log.error("上传的gps信息不完整,至少缺少deviceId和坐标{}", object.toString());
return;
}
// 维护开机下线信息
serviceFactory.getSceneCommonService().checkOfflineAndRepairInfo(deviceId, object.getDate("logTime"));
// 维护开机上线信息
serviceFactory.getSceneCommonService().setOnlineVehicleInfo(deviceId, String.format("%s_%s", lon, lat));
};
// 异步执行,否则超时会有重复消费的风险
fixedThreadPool.submit(SvFunctionUtil.wrapperFunction(process, "检查关机数据&维护车机上线状态"));
}
@KafkaListener(topics = Const.INTERNAL_TOPIC_DEV_BOOT, groupId = "monitor-1")
public void bootInfoMonitor(ConsumerRecord<?, String> record) {
String bootInfo = record.value();
log.debug("bootInfoMonitor 收到开/关机信息{}", bootInfo);
// 异步执行,否则超时会有重复消费的风险
Runnable process = () -> {
serviceFactory.getTripSceneReadyService().reset(ParseUtil.getDeviceId(bootInfo));
serviceFactory.getSceneCommonService().reportBootInfo(bootInfo);
};
fixedThreadPool.submit(SvFunctionUtil.wrapperFunction(process, "上报开机信息"));
}
}
5.4 分片导出数据到Excel,避免一次性数据过大,产生OOM
public class ExportUtil<X> {
private Log logger = LogFactory.get();
private JpaSpecificationExecutor<X> jpaSpecificationExecutor;
private Specification<X> spec;
private EntityManager em;
private String sql;
private String sheetName;
Map<String, Object> sqlParams;
private final static int BATCH_SIZE = 2000;
private final static int SHEET_SIZE = 50000;
private final AtomicInteger currentLine = new AtomicInteger(0);
private final ExecutorService executorService = Executors.newCachedThreadPool();
private final static int defaultThreadNum = 2;
private final static int maxThreadNum = 4;
// Excel自动适应宽度比较耗时,因此在数据量大于这个阀值时,不保证所有的单元格都自动适应大小
private final static int autoSizeThresholdNum = SHEET_SIZE;
// 每个线程处理的记录数
private final static int perThreadRow = 10000;
/**
* 通过JPA的方式将查询到的结果导出到Excel
*/
public ExportUtil(@NotNull JpaSpecificationExecutor<X> jpaSpecificationExecutor, @NotNull Specification<X> spec) {
this.jpaSpecificationExecutor = jpaSpecificationExecutor;
this.spec = spec;
}
/**
* 通过写SQL语句的方式将结果导出到Excel
* @param em EntityManager
* @param sql sql语句必须匹配:"SELECT .* FROM .*",且不能以limit子句结尾
* @deprecated 建议使用JPA的方式导出数据
*/
@Deprecated
public ExportUtil(@NotNull EntityManager em, @NotNull String sql) {
this.em = em;
this.sql = sql;
}
/**
* 通过写SQL语句的方式将结果导出到Excel
* @param em EntityManager
* @param sql sql语句必须匹配:"SELECT .* FROM .*",且不能以limit子句结尾
* @param sqlParams sql的参数
* @deprecated 建议使用JPA的方式导出数据
*/
@Deprecated
public ExportUtil(@NotNull EntityManager em, @NotNull String sql, Map<String, Object> sqlParams) {
this(em, sql);
this.sqlParams = sqlParams;
}
public String export(@NotNull String sheetName, @NotNull Function<? super X, Map<String, Object>> process) throws IOException {
this.sheetName = sheetName;
return this.export(process);
}
public String export(@NotNull String sheetName) throws IOException {
this.sheetName = sheetName;
return this.export(this::process);
}
private Map<String, Object> process(X x) {
Map<String, Object> row = new LinkedHashMap<>();
Field[] fields = ReflectUtil.getFields(x.getClass());
for (Field field : fields) {
ExcelProperty excelProperty = field.getAnnotation(ExcelProperty.class);
if (excelProperty == null) {
continue;
}
String columnName = excelProperty.columnName();
String value = ReflectUtil.invoke(x, StrUtil.upperFirstAndAddPre(field.getName(), "get"));
row.put(columnName, value);
}
return row;
}
/**
* 从数据库到Excel导出流程
*
* @param fristRowName
* @param response
* @param process
* @throws IOException
*/
public String export(@NotNull Function<? super X, Map<String, Object>> process) throws IOException {
String tempFile = genTempFile();
ExcelWriter writer = ExcelUtil.getBigWriter(tempFile, sheetName);
long count = Optional.ofNullable(jpaSpecificationExecutor).map(x -> x.count(spec)).orElseGet(() -> new SqlQueryData(0, 1).count());
int threadNum = Math.min(maxThreadNum, Math.max((int) count / perThreadRow, defaultThreadNum));
Set<Future<?>> submitSet = new HashSet<>(threadNum);
for (int i = 0; i < count; i += BATCH_SIZE) {
waiteSubmit(submitSet, threadNum - 1);// 保证至少有一个空闲线程才向下执行
QueryData queryData;
if (Objects.nonNull(jpaSpecificationExecutor)) {
queryData = new JpaQueryData(i, BATCH_SIZE);
} else {
queryData = new SqlQueryData(i, BATCH_SIZE);
}
Future<?> submit = executorService.submit(new DB2Excel(queryData, writer, process));
submitSet.add(submit);
}
waiteSubmit(submitSet, 0);// 保证所有线程都执行完成才向下执行
if (count <= autoSizeThresholdNum && count > 0) {
// writer.autoSizeColumnAll();
}
writer.close();
// String compressedFile = compressFile(tempFile);
// flush(response, tempFile, fristRowName);
return tempFile;
}
/**
* 等待指定数量的线程结束
* @param submits 线程结果集
* @param max 最大允许多少个正在执行的线程,如果超过这个数量,则等待
*/
private void waiteSubmit(Collection<Future<?>> submits, int max) {
while (submits.size() > max) {
for (Future<?> submit : submits) {
try {
// 查询这个线程是否结束,如果结束从线程结果集中删除
submit.get(10, TimeUnit.MILLISECONDS);
submits.remove(submit);
break;
} catch (TimeoutException e) {
// 正常超时,查询下一个线程
} catch (ExecutionException e) {
logger.warn("等待查询导出线程过程中出现异常,不再查询这个线程:{}", e.getMessage());
submits.remove(submit);
} catch (InterruptedException e) {
logger.warn("等待查询导出线程过程中收到中断信号:{}", e.getMessage());
}
}
}
}
/**
* 导出实现类
*/
class DB2Excel implements Runnable {
QueryData queryData;
ExcelWriter excelWriter;
Function<? super X, Map<String, Object>> process;
DB2Excel(@NotNull QueryData queryData, @NotNull ExcelWriter excelWriter,
@NotNull Function<? super X, Map<String, Object>> process) {
this.queryData = queryData;
this.excelWriter = excelWriter;
this.process = process;
}
@Override
public void run() {
logger.info("开始查询导出:{}", queryData);
List<Map<String, Object>> content = queryData.query().stream().map(process).collect(Collectors.toList());
int contentSize = content.size();
long totalElements = queryData.count();
synchronized (excelWriter) {
if (0 == currentLine.get() % SHEET_SIZE && CollectionUtil.isNotEmpty(content)) {
if (currentLine.get() > 0 && totalElements <= autoSizeThresholdNum) {
// excelWriter.autoSizeColumnAll();
}
if (currentLine.get() > 0) {
excelWriter.setSheet(sheetName + (currentLine.get() / SHEET_SIZE + 1));
}
if (totalElements > autoSizeThresholdNum) {
List<Object> firstLine = new ArrayList<>(1);
firstLine.add(content.get(0));
excelWriter.write(firstLine, true);
// excelWriter.autoSizeColumnAll();
content.remove(firstLine.get(0));
excelWriter.write(content, false);
} else {
excelWriter.write(content, true);
}
} else {
excelWriter.write(content, false);
}
currentLine.addAndGet(contentSize);
}
}
}
/**
* 查询类基类
*/
abstract class QueryData {
protected int offset;
protected int limit;
/**
* 查询参数
* @param offset
* @param limit
*/
QueryData(int offset, int limit) {
this.offset = offset;
this.limit = limit;
}
/**
* 查询结果总数
*/
abstract long count();
/**
* 查询结果
*/
abstract public List<X> query();
@Override
public String toString() {
return "QueryData{" + "offset=" + offset + ", limit=" + limit + '}';
}
}
/**
* JPA查询实现类
*/
class JpaQueryData extends QueryData {
JpaQueryData(int offset, int limit) {
super(offset, limit);
}
@Override
long count() {
return jpaSpecificationExecutor.count(spec);
}
@Override
public List<X> query() {
Pageable pageable = PageRequest.of(offset / BATCH_SIZE, BATCH_SIZE);
Page<X> page = jpaSpecificationExecutor.findAll(spec, pageable);
return page.getContent();
}
}
/**
* SQL查询实现类
*/
class SqlQueryData extends QueryData {
private static final String SQL_REG = "SELECT .* FROM .*";
String convertCountSql() {
if (!sql.matches(SQL_REG)) {
logger.warn("非法的SQL查询语句:{}");
throw new RuntimeException("不能查询到有效的数据!");
}
int fromIdx = sql.indexOf("FROM");
return "SELECT count(1) AS total " + sql.substring(fromIdx);
}
SqlQueryData(int offset, int limit) {
super(offset, limit);
}
@Override
long count() {
Query query = em.createNativeQuery(convertCountSql());
query.setMaxResults(BATCH_SIZE);
query.setFirstResult(0);
if (Objects.nonNull(sqlParams)) {
sqlParams.forEach((x, y) -> query.setParameter(x, y));
}
Object singleResult = query.getSingleResult();
return Long.parseLong(singleResult.toString());
}
@SuppressWarnings("unchecked")
@Override
public List<X> query() {
Query query = em.createNativeQuery(sql);
query.setMaxResults(BATCH_SIZE);
query.setFirstResult(offset);
if (Objects.nonNull(sqlParams)) {
sqlParams.forEach((x, y) -> query.setParameter(x, y));
}
query.unwrap(NativeQueryImpl.class).setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP);
return query.getResultList();
}
}
/**
* 产生一个临时文件名
*/
private String genTempFile() throws UnsupportedEncodingException {
String tmpDir = System.getProperty("java.io.tmpdir");
if (!tmpDir.endsWith(File.separator)) {
tmpDir += File.separator;
}
return String.format("%s%s-%d.xlsx", tmpDir, cn.hutool.core.date.DateUtil.date().toString(DatePattern.PURE_DATETIME_MS_PATTERN),
RandomUtil.randomInt(100000));
}
public String combineExcel(@NotNull String sheetName, @NotNull Function<? super X, Map<String, Object>> process,
@NotNull String sheetName1, @NotNull Function<? super Map<String, Object>, Map<String, Object>> process1,
@NotNull JdbcTemplate em, @NotNull String sql, Object[] objects, String orderSql) throws IOException {
String tempFile = genTempFile();
ExcelWriter writer = new BigExcelWriter(tempFile, sheetName);
export(process, writer);
@SuppressWarnings("deprecation")
ExportUtilFromHbase<Map<String, Object>> exportUtil = new ExportUtilFromHbase<Map<String, Object>>(em, sql, objects, orderSql);
exportUtil.export(process1, writer, sheetName1);
// export(process1, writer);
writer.close();
return tempFile;
}
public void export(@NotNull Function<? super X, Map<String, Object>> process, ExcelWriter writer) throws IOException {
long count = Optional.ofNullable(jpaSpecificationExecutor).map(x -> x.count(spec)).orElseGet(() -> new SqlQueryData(0, 1).count());
int threadNum = Math.min(maxThreadNum, Math.max((int) count / perThreadRow, defaultThreadNum));
Set<Future<?>> submitSet = new HashSet<>(threadNum);
for (int i = 0; i < count; i += BATCH_SIZE) {
waiteSubmit(submitSet, threadNum - 1);// 保证至少有一个空闲线程才向下执行
QueryData queryData;
if (Objects.nonNull(jpaSpecificationExecutor)) {
queryData = new JpaQueryData(i, BATCH_SIZE);
} else {
queryData = new SqlQueryData(i, BATCH_SIZE);
}
Future<?> submit = executorService.submit(new DB2Excel(queryData, writer, process));
submitSet.add(submit);
}
waiteSubmit(submitSet, 0);// 保证所有线程都执行完成才向下执行
if (count <= autoSizeThresholdNum && count > 0) {
// writer.autoSizeColumnAll();
}
}
}
5.5 线程相关工具类.
public class Threads {
private static final Logger logger = LoggerFactory.getLogger(Threads.class);
/**
* sleep等待,单位为毫秒
*/
public static void sleep(long milliseconds) {
try {
Thread.sleep(milliseconds);
} catch (InterruptedException e) {
logger.error("Threads sleep error", e);
Thread.currentThread().interrupt();
return;
}
}
/**
* 停止线程池 先使用shutdown, 停止接收新任务并尝试完成所有已存在任务. 如果超时, 则调用shutdownNow,
* 取消在workQueue中Pending的任务,并中断所有阻塞函数. 如果仍人超時,則強制退出. 另对在shutdown时线程本身被调用中断做了处理.
*/
public static void shutdownAndAwaitTermination(ExecutorService pool) {
if (pool != null && !pool.isShutdown()) {
pool.shutdown();
try {
if (!pool.awaitTermination(120, TimeUnit.SECONDS)) {
pool.shutdownNow();
if (!pool.awaitTermination(120, TimeUnit.SECONDS)) {
logger.info("Pool did not terminate");
}
}
} catch (InterruptedException ie) {
pool.shutdownNow();
Thread.currentThread().interrupt();
}
}
}
/**
* 打印线程异常信息
*/
public static void printException(Runnable r, Throwable t) {
if (t == null && r instanceof Future<?>) {
try {
Future<?> future = (Future<?>) r;
if (future.isDone()) {
future.get();
}
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
if (t != null) {
logger.error(t.getMessage(), t);
}
}
}
5.6 定时触发任务,且任务没有触发之前,可以更新任务触发时间和执行的动作
@Slf4j
public class TaskSchedule {
final private ExecutorService executors = Executors.newCachedThreadPool();
final private Map<String, Date> key2Date = new HashMap<>();
final private TreeMap<Date, List<Pair<String, Runnable>>> taskMap = new TreeMap<>();
final private Thread deamonThread = new Thread(this::deamon);
final static private TaskSchedule defaultTask = new TaskSchedule();
public static TaskSchedule getDefault() {
return defaultTask;
}
public TaskSchedule() {
deamonThread.start();
}
/**
* 设置定时任务
* 注:1.如果已经存在名为taskName的任务,则用当前的信息更新之前的任务
* 2.如果task 或者 triggerDate 为null,且之前没有设置过,取消任务
*
* @param taskName 任务名
* @param task 任务代码
* @param triggerDate 触发时间
*/
public void submit(String taskName, Runnable task, Date triggerDate) {
pushTaskInner(taskName, task, (Date) triggerDate.clone());
}
public boolean cancel(String taskName) {
synchronized (taskMap) {
return cancelInner(taskName);
}
}
/**
* 设置定时任务
* 注:1.如果已经存在名为taskName的任务,则用当前的信息更新之前的任务
* 2.如果task为null,且之前没有设置过,取消任务
*
* @param taskName 任务名
* @param task 任务代码
* @param delayMS 相对于当前,延时触发时间
*/
public void submit(String taskName, Runnable task, int delayMS) {
pushTaskInner(taskName, task, DateUtil.date().offset(DateField.MILLISECOND, delayMS));
}
/**
* 任务派发核心线程
*/
private void deamon() {
synchronized (taskMap) {
while (true) {
try {
Map.Entry<Date, List<Pair<String, Runnable>>> entry = taskMap.firstEntry();
if (Objects.isNull(entry)) {
taskMap.wait();
}
DateTime now = new DateTime();
long sleepTime = entry.getKey().getTime() - now.getTime();
if (sleepTime <= 0) {
runTask(entry.getValue());
taskMap.remove(entry.getKey());
entry.getValue().forEach(x -> key2Date.remove(x.getKey()));
} else {
taskMap.wait(sleepTime);
runTask(entry.getValue());
taskMap.remove(entry.getKey());
entry.getValue().forEach(x -> key2Date.remove(x.getKey()));
}
} catch (InterruptedException e) {
// todo nothing
// 有新任务push 进来
}
}
}
}
/**
* 任务发送到缓存队列
*/
private void pushTaskInner(String taskName, Runnable task, Date triggerDate) {
if (StrUtil.isBlank(taskName)) {
return;
}
synchronized (taskMap) {
task = Optional.ofNullable(task).orElseGet(() -> getTaskInner(taskName));
triggerDate = Optional.ofNullable(triggerDate).orElseGet(() -> key2Date.get(taskName));
if (Objects.isNull(task) || Objects.isNull(triggerDate)) {
return;
}
cancelInner(taskName);
if (!taskMap.containsKey(triggerDate)) {
List<Pair<String, Runnable>> taskList = new ArrayList<>(1);
taskList.add(new Pair<>(taskName, task));
taskMap.put(triggerDate, taskList);
log.debug("add new data task : {} - {}", taskName, triggerDate);
} else {
List<Pair<String, Runnable>> oriTask = taskMap.get(triggerDate);
oriTask.add(new Pair<>(taskName, task));
log.debug("add same data task : {} - {}", taskName, triggerDate);
}
key2Date.put(taskName, triggerDate);
deamonThread.interrupt();
}
}
/**
* 通过任务名获取任务的回调方法
*
* @param taskName
* @return
*/
private Runnable getTaskInner(String taskName) {
if (Objects.isNull(taskName)) {
return null;
}
Date date = key2Date.get(taskName);
if (Objects.isNull(date)) {
return null;
}
List<Pair<String, Runnable>> tasks = taskMap.get(date);
if (Objects.isNull(tasks)) {
return null;
}
return tasks.stream().filter(x -> Objects.equals(x.getKey(), taskName))
.findFirst().map(Pair::getValue).orElse(null);
}
/**
* 取消任务
*/
private boolean cancelInner(String taskName) {
if (Objects.isNull(taskName)) {
return false;
}
Date date = key2Date.get(taskName);
if (Objects.isNull(date)) {
return false;
}
key2Date.remove(taskName);
List<Pair<String, Runnable>> tasks = taskMap.get(date);
if (Objects.isNull(tasks)) {
return false;
}
boolean ret = tasks.removeIf(x -> Objects.equals(x.getKey(), taskName));
if (tasks.isEmpty()) {
taskMap.remove(date);
}
return ret;
}
/**
* 把任务派发到执行线程
*
* @param tasks
*/
private void runTask(List<Pair<String, Runnable>> tasks) {
if (Objects.nonNull(tasks)) {
tasks.forEach(x -> executors.execute(x.getValue()));
}
}
}
相关文章
- Tomcat 配置 项目 到tomcat目录外面 和 域名绑定访问(api接口、前端网站、后台管理网站)
- 使用阿里云身份证扫描识别接口案例——CSDN博客
- mybatis源码学习--spring+mybatis注解方式为什么mybatis的dao接口不需要实现类
- 路飞学城项目-支付相关-支付接口
- 路飞学城项目-支付相关-购物车接口
- EasyDarwin开源音频解码项目EasyAudioDecoder:EasyPlayer Android音频解码库(第二部分,封装解码器接口)
- nginx配置部署vuejs gva(gin-vue-admin)项目并解决后端api接口请求时报404问题(附nginx.conf)
- Angular Public API 接口设计
- Atitit 项目常用模块 非业务模块 通用技术模块 attilax大总结 理论上可行。但要限制接口方式。 不然现在很多ui与后端接口模式很多,导致组合爆炸。。。 常用模块也就100来个而已。。
- 【项目实战】MyBatis的基础源码 —— MapperProxy(Mapper接口的代理类)源码介绍
- 【C语言】封装接口(加减乘除)
- 华为云EI人脸识别接口初探
- 枚举实现接口——模拟可扩展的枚举
- pytest接口自动化测试框架 | 项目实战(pytest+allure+数据驱动)
- 采用CXF+spring+restful创建一个web接口项目
- 只会postman单接口测试?这些高级功能你必须掌握
- Python接口自动化核心模块 - 数据库操作和日志
- 【进阶自动化测试第一步】接口测试基础
- 如何用Python获取接口响应时间?elapsed方法来帮你
- 接口测试结果字段太多,断言烦不胜烦,DeepDiff帮你一键弄好
- 新冠肺炎疫情实时数据接口API和开源项目
- Mybatis接口注解
- Python 封装SNMP调用接口
- Springboot项目如何设计接口中敏感字段模糊查询?
- Eolink——通用文字识别OCR接口示例