
【目标检测】28、Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
文章目录
论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
代码:https://github.com/Zzh-tju/DIoU
出处:AAAI2020
一、背景
bbox 的回归在目标检测任务中的框定位问题中非常重要,IoU 也常用于衡量 bbox 回归质量。也有文章提出了 IoU loss 来提升对 IoU 的衡量:
IoU 计算方法如下:
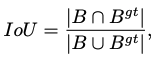
IoU-Loss 计算如下:
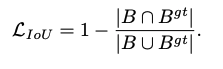
备注:
- IoU Loss 在提出的时候定义为: L I o U = − l n ( I o U ) L_{IoU}=-ln(IoU) LIoU=−ln(IoU)
- 但在使用中一般使用 L I o U = 1 − I o U L_{IoU}= 1-IoU LIoU=1−IoU
本文作者认为,IoU loss 只能在两个框有相交的情况下生效,对无相交的情况,IoU 为 0 ,不能带来梯度的修正。
GIoU loss 添加了一个惩罚参数,形式如下:
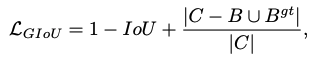
- C 是覆盖 B B B 和 B g t B^{gt} Bgt 的最小的盒子
- 引入该惩罚参数,距离越远,该惩罚项就会越大,Loss 会越大,和真实 gt 框无交集的预测框就会被移除
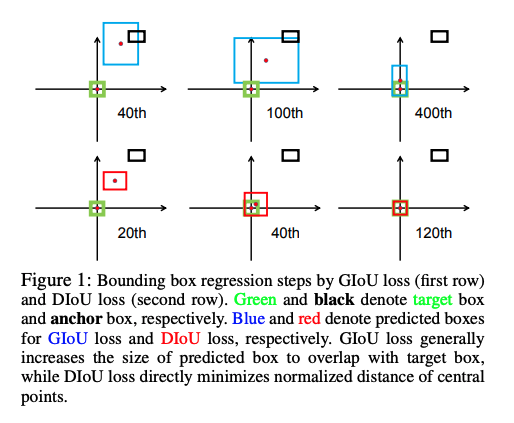
虽然 GIoU 可以通过移除未相交的框来缓解梯度消失的情况,但如图 1 所示,GIoU loss 首先会提升预测框的大小,使得其和 gt 框有相交,然后公式 3 就能够用来最小化相交面积。如图 2 所示,GIoU loss 能够降低最小包围框的 IoU loss。由于严重依赖 IoU,所以 GIoU 需要更长的迭代时间来收敛,尤其是垂直或水平的框(如图4所示)。所以 GIoU loss 会产生一些不准确的检测。
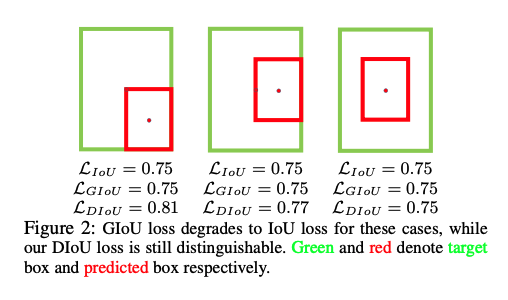
本文的解决方法:Distance-IoU loss
- DIoU Loss:在 NMS 中作为一个衡量指标。
在 IoU loss 的基础上添加了一个惩罚项,来直接最小化两个 bbox 的中心点的距离,比 GIoU 收敛的更快,如图 1 所示。DIoU loss 在 120 epochs 就已经收敛,GIoU loss 需要 400 epochs。该 Loss 可以更好的抑制冗余的 bbox,对遮挡情况更鲁棒。 - CIoU Loss:用于 bbox 回归。
本文作者认为,一个好的针对 bbox 回归的 loss 函数,需要考虑到三个方面:重叠面积、中心点距离、纵横比,通过结合这些几何度量,作者提出了 Complete IoU (CIoU),收敛速度更快,效果比 IoU 和 GIoU 效果更好。
二、方法
2.1 分析 IoU 和 GIoU 的局限性
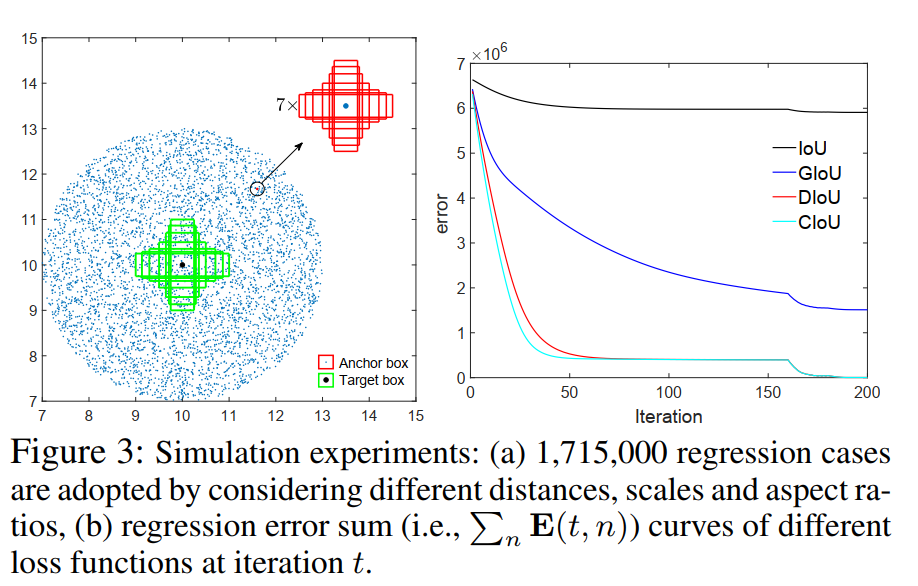
作者为了更加全面的分析距离、尺度、纵横比在 bbox 之间的关系,选取了 7 种不同纵横比的 unit box(即面积为 1),纵横比分别为(1:4, 1:3, 1:2, 1:1, 2:1, 3:1, 4:1),这 7 个 box 的中心点都在(10,10)。收敛曲线如图 3b 所示。
可以看出,CIoU loss 收敛速度最快,且准确率最高。
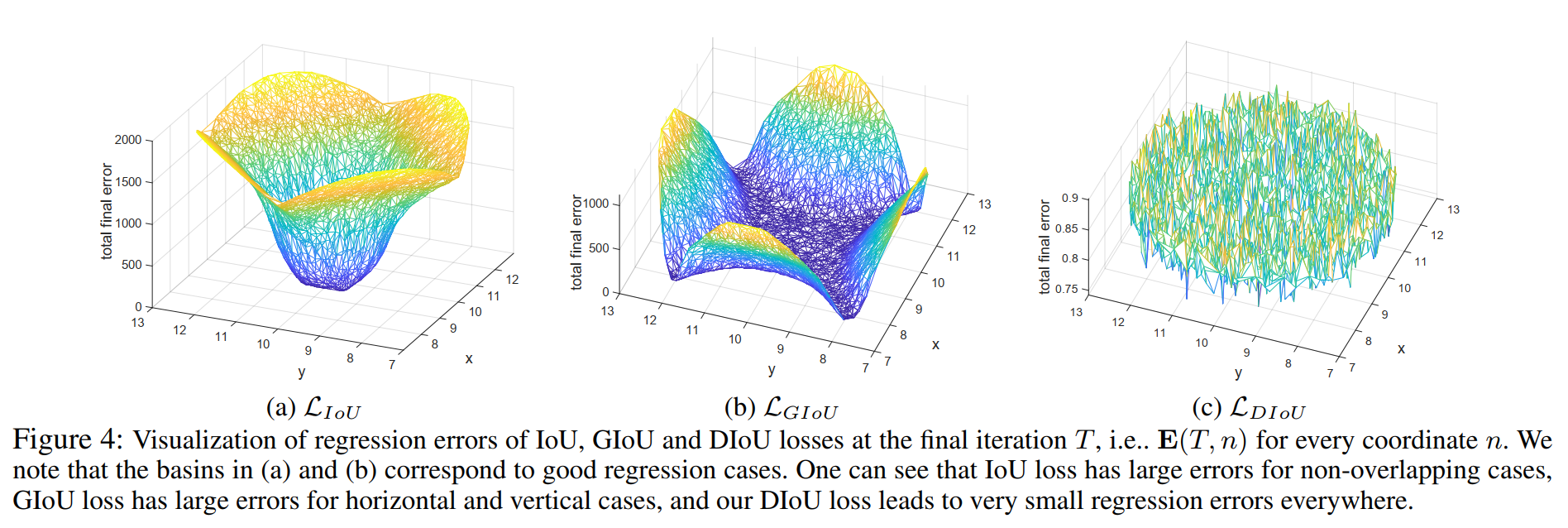
如图 4a 所示,作者展示了 5000 个分散的点在 iter 为 T 时的回归误差,IoU Loss 仅在 anchor 和真实框有相交的情况下,表现较好。那些和真实框无相交的 anchor 无法被移除。
如图 4b 所示,GIoU loss 可以移除那些 non-overlapping 的情况,GIoU 可以扩大作用域,但那些水平或竖直条形 anchor 的情况仍然会出现问题,这是由于 GIoU loss 使用的惩罚项是用于最小化 ∣ C − A ∪ B ∣ |C-A\cup B| ∣C−A∪B∣,但 C − A ∪ B C-A\cup B C−A∪B 的面积通常很小或为 0(两个框为包含关系的时候,为 0),GIoU loss 就退化成了 IoU loss。
只要运行足够的迭代并使用合适的学习率,GIoU loss 也可以得到很好的结果,但收敛速度确实非常缓慢。从图 1 的回归曲线来看,GIoU 会增大预测框的尺寸来让它和真实框有相交,但会使得收敛很慢。
总结:
- IoU loss 对未相交的 anchor 无法处理
- GIoU loss 收敛很慢
- GIoU 对于水平和竖直的条形 anchor,误差较大
GIoU 主要是在收敛 A c − U A^c-U Ac−U 这个值,也就是最小框面积-并集面积,作者经过实验发现这么收敛会导致网络优先选择扩大 bounding box 的面积来覆盖 ground truth,而不是去移动 bounding box 的位置去覆盖 ground truth。
基于此,作者提出了两个问题:
- 第一个:直接最小化预测框和真实框的 normalized distance 来实现更快的收敛是否可行?
- 第二个:如何在与目标框重叠甚至包含的情况下使回归更准确、更快?
2.2 本文提出的方法:D-IoU Loss 和 C-IoU Loss
首先可以定义 IoU-based loss 可以定义如下:
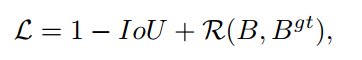
其中, R ( B , B g t ) R(B, B^{gt}) R(B,Bgt) 是惩罚项
1、Distance-IoU Loss
对于第一个问题,作者提出了一种方法,直接最小化两个 bboxes 的中心点的距离,惩罚项定义如下:
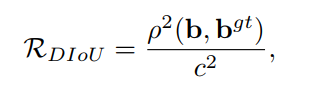
- b b b 和 b g t b^{gt} bgt 分别为 B B B 和 B g t B^{gt} Bgt 的中心点
- ρ 2 \rho ^2 ρ2 是欧式距离
- c c c 是最小包围盒的对角线距离
以此来看,DIoU 最小化的不是外接矩形和并集面积的差值,而是同时最小化外接矩形的面积和两框中心点的距离,这会使得网络更倾向于移动 bbox 的位置来减少 loss。
DIoU Loss 的函数如下:
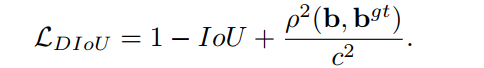
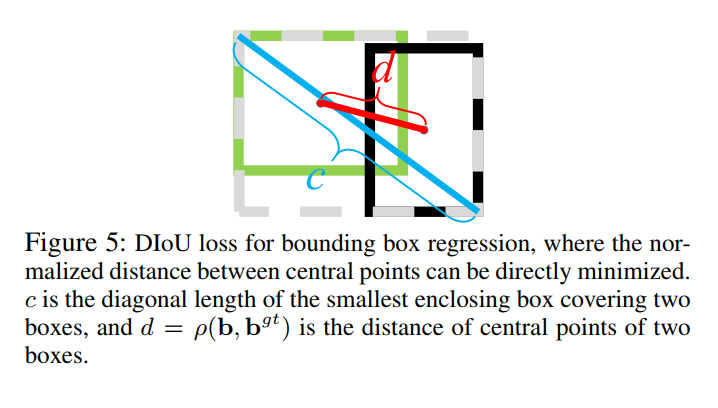
如图 5 所示,DIoU Loss 的惩罚项可以直接最小化两个中心点的距离,但 GIoU Loss 是最小化 C − B ∪ B g t C-B \cup B^{gt} C−B∪Bgt 的面积。
DIoU Loss 和 IoU 及 GIoU 的对比:
- DIoU Loss 是不随回归问题的尺度而变的
- DIoU Loss 可以给不和 gt box 相交的 anchor 提供移动的方向
- 当两个 bbox 很好的匹配时,三个 IoU Loss 都等于 0,当两个 bbox 远离时,GIoU 和 DIoU loss → 2
DIoU Loss 的特性:
- 如图 1 和图 3,DIoU 可以直接最小化两个 bbox 的距离,加速收敛,如图 1 和 3 所示。
- 对于两个 bbox 包围的情况,或水平/竖直的情况,DIoU Loss 收敛的更快,GIoU 和 IoU 的收敛速度类似。
2、Complete IoU Loss
对于第二个问题,作者提出,一个好的针对 bbox 回归的 loss 函数,要考虑三个集合问题:重合率、中心点距离、纵横比。
IoU loss 考虑了重合率,GIoU loss 很大程度上是基于 IoU loss 的。
DIoU loss 同时考虑了重合率和 bbox 的中心点距离。
所以 CIoU loss 在 DIoU 的基础上,添加了对纵横比的约束
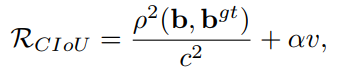
其中:
- α \alpha α 是正的平衡参数
- v v v 是衡量纵横比的一致性的,也就是说要让两个框的 w / h w/h w/h 尽可能的相同, v v v 才会很低
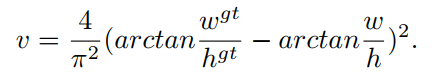
Loss 函数定义如下:
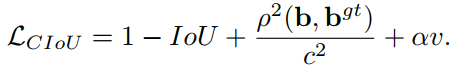
α \alpha α 定义如下,
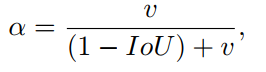
CIoU 的优化和 DIoU 一致,除过 v v v 要对 w w w 和 h h h 分别求导:
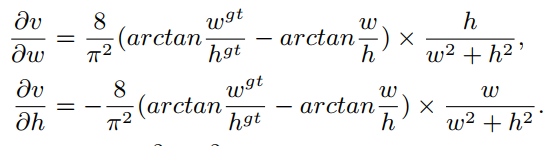
- w 2 + h 2 w^2+h^2 w2+h2 通常是一个很小的值, h h h 和 w w w 都是 [0,1] 之间的值,容易出现梯度爆炸,所以令其为 1
思考:
- 这里其实也有问题,因为当两个框为等比例缩放的时候, v = 0 v=0 v=0,难以被优化
- w w w 和 h h h 其中一个增大,另一个必然减小,无法同时增大或减小
- 只关心两者比例,而非每个边对应的真实差距,容易导致不期望的优化方式。
3、如何在 NMS 中使用
在传统的 NMS 中,IoU 通常被用于抑制多于的检测框,且相交面积是唯一衡量因子,这就会导致对有重叠的目标所产生的框的错误抑制。
所以本文中,使用 DIoU 作为 NMS 中框排序的依据,同时考虑了重合率和中心点距离作为衡量指标。
对于有高得分的框 M M M,DIoU-NMS 被定义如下:
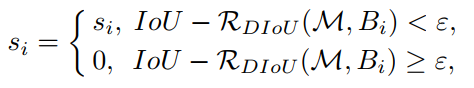
- B i B_i Bi 是同时考虑了 IoU 和中心点的距离后,才会被确定是否移除
- s i s_i si 是分类得分
- ϵ \epsilon ϵ 是 NMS 阈值
- 作者认为,两个框的中心点距离越远,则越可能是两个不同的目标,越不应该被移除。
- 所以 D − I o U − N M S D-IoU-NMS D−IoU−NMS 更加灵活有效
三、效果
3.1 YOLO v3 on PASCAL VOC
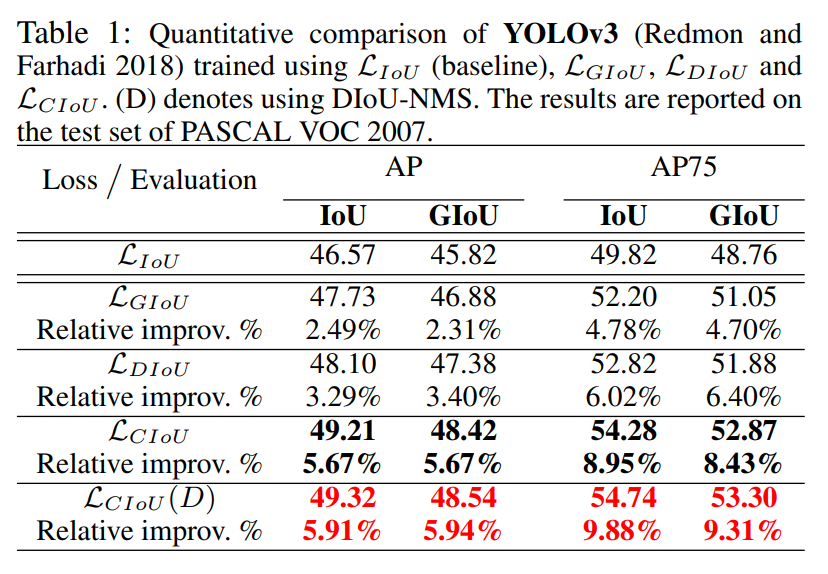
- DIoU 相比 IoU,提升了 3.29 AP,6.02 AP75
- CIoU 相比 IoU,提升了 5.67 AP,8.95 AP75

- CIoU loss 的检测框比 GIoU loss 的检测框更准确
- CIoU loss(结合 DIoU-NMS)带来了 5.91 AP 和 9.88 AP75 的提升
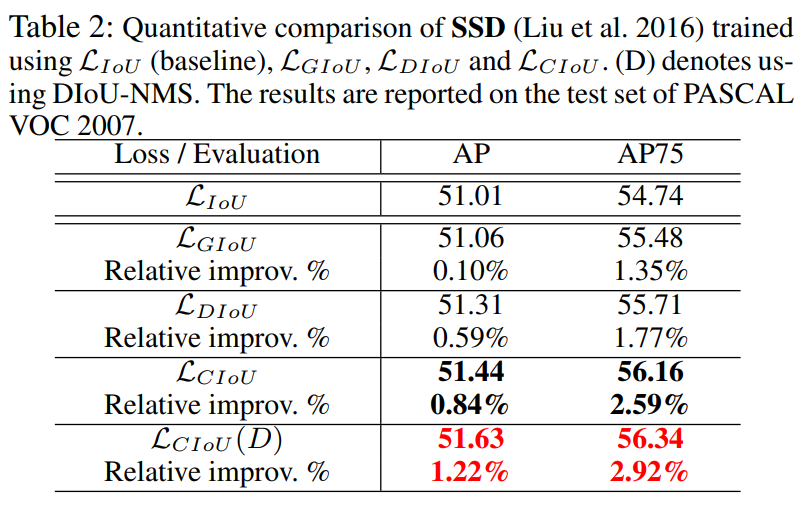
3.2 SSD on PASCAL VOC
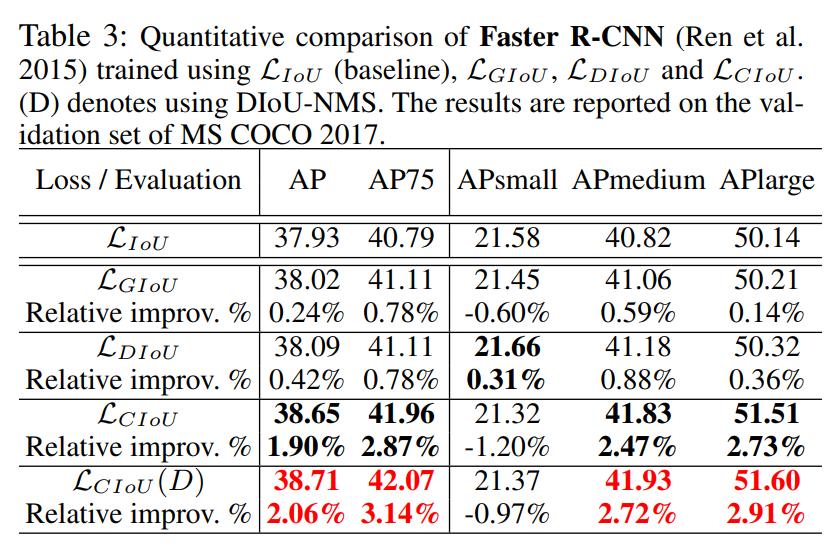
3.3 Faster R-CNN on MS COCO

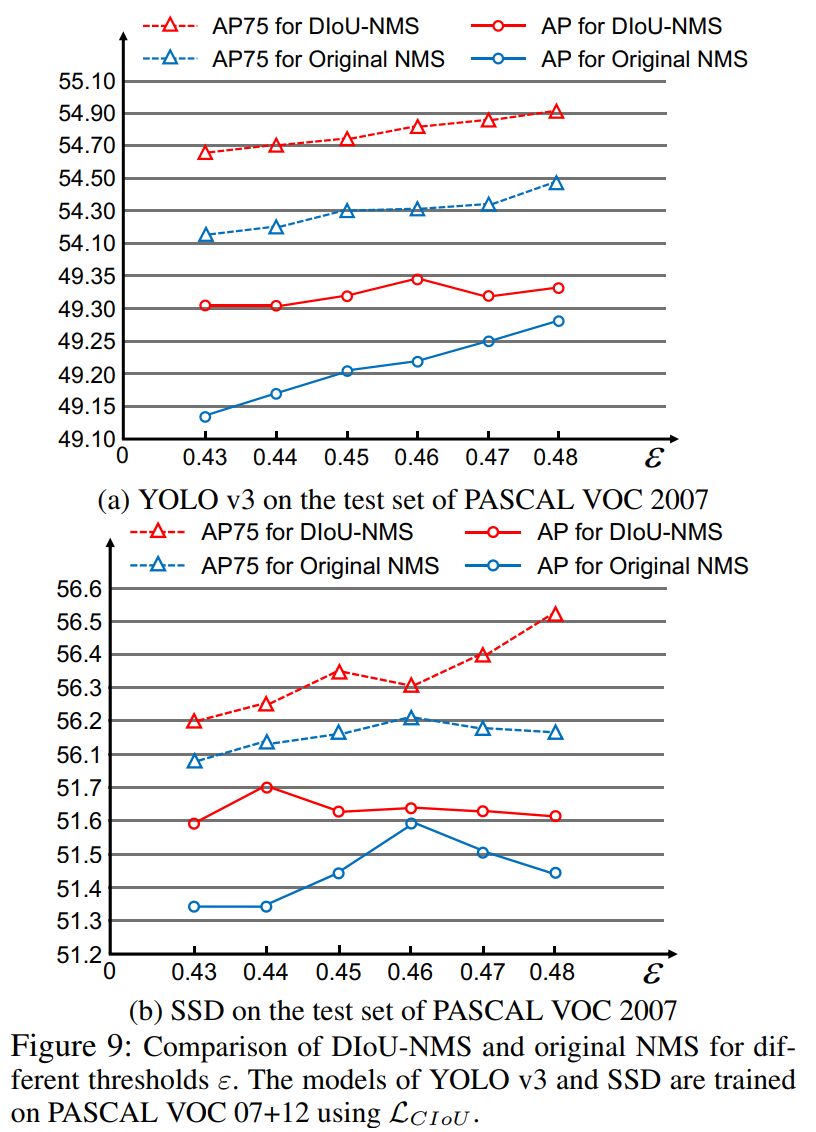
3.4 Discussion on DIoU-NMS

图 8 展示了 D-IoU-NMS 可以很好的保留正确检测框。
图 9 对比了不同阈值下的 AP 结果,DIoU-NMS 明显优于原始 NMS,
四、代码
https://github.com/Zzh-tju/DIoU-pytorch-detectron/blob/master/lib/utils/net.py
import logging
import os
import math
import numpy as np
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from core.config import cfg
import nn as mynn
logger = logging.getLogger(__name__)
def bbox_transform(deltas, weights):
wx, wy, ww, wh = weights
dx = deltas[:, 0::4] / wx
dy = deltas[:, 1::4] / wy
dw = deltas[:, 2::4] / ww
dh = deltas[:, 3::4] / wh
dw = torch.clamp(dw, max=cfg.BBOX_XFORM_CLIP)
dh = torch.clamp(dh, max=cfg.BBOX_XFORM_CLIP)
pred_ctr_x = dx
pred_ctr_y = dy
pred_w = torch.exp(dw)
pred_h = torch.exp(dh)
x1 = pred_ctr_x - 0.5 * pred_w
y1 = pred_ctr_y - 0.5 * pred_h
x2 = pred_ctr_x + 0.5 * pred_w
y2 = pred_ctr_y + 0.5 * pred_h
return x1.view(-1), y1.view(-1), x2.view(-1), y2.view(-1)
def compute_diou(output, target, bbox_inside_weights, bbox_outside_weights,
transform_weights=None):
if transform_weights is None:
transform_weights = (1., 1., 1., 1.)
x1, y1, x2, y2 = bbox_transform(output, transform_weights)
x1g, y1g, x2g, y2g = bbox_transform(target, transform_weights)
x2 = torch.max(x1, x2)
y2 = torch.max(y1, y2)
x_p = (x2 + x1) / 2
y_p = (y2 + y1) / 2
x_g = (x1g + x2g) / 2
y_g = (y1g + y2g) / 2
xkis1 = torch.max(x1, x1g)
ykis1 = torch.max(y1, y1g)
xkis2 = torch.min(x2, x2g)
ykis2 = torch.min(y2, y2g)
xc1 = torch.min(x1, x1g)
yc1 = torch.min(y1, y1g)
xc2 = torch.max(x2, x2g)
yc2 = torch.max(y2, y2g)
intsctk = torch.zeros(x1.size()).to(output)
mask = (ykis2 > ykis1) * (xkis2 > xkis1)
intsctk[mask] = (xkis2[mask] - xkis1[mask]) * (ykis2[mask] - ykis1[mask])
unionk = (x2 - x1) * (y2 - y1) + (x2g - x1g) * (y2g - y1g) - intsctk + 1e-7
iouk = intsctk / unionk
c = ((xc2 - xc1) ** 2) + ((yc2 - yc1) ** 2) +1e-7
d = ((x_p - x_g) ** 2) + ((y_p - y_g) ** 2)
u = d / c
diouk = iouk - u
iou_weights = bbox_inside_weights.view(-1, 4).mean(1) * bbox_outside_weights.view(-1, 4).mean(1)
iouk = ((1 - iouk) * iou_weights).sum(0) / output.size(0)
diouk = ((1 - diouk) * iou_weights).sum(0) / output.size(0)
return iouk, diouk
def compute_ciou(output, target, bbox_inside_weights, bbox_outside_weights,
transform_weights=None):
if transform_weights is None:
transform_weights = (1., 1., 1., 1.)
x1, y1, x2, y2 = bbox_transform(output, transform_weights)
x1g, y1g, x2g, y2g = bbox_transform(target, transform_weights)
x2 = torch.max(x1, x2)
y2 = torch.max(y1, y2)
w_pred = x2 - x1
h_pred = y2 - y1
w_gt = x2g - x1g
h_gt = y2g - y1g
x_center = (x2 + x1) / 2
y_center = (y2 + y1) / 2
x_center_g = (x1g + x2g) / 2
y_center_g = (y1g + y2g) / 2
xkis1 = torch.max(x1, x1g)
ykis1 = torch.max(y1, y1g)
xkis2 = torch.min(x2, x2g)
ykis2 = torch.min(y2, y2g)
xc1 = torch.min(x1, x1g)
yc1 = torch.min(y1, y1g)
xc2 = torch.max(x2, x2g)
yc2 = torch.max(y2, y2g)
intsctk = torch.zeros(x1.size()).to(output)
mask = (ykis2 > ykis1) * (xkis2 > xkis1)
intsctk[mask] = (xkis2[mask] - xkis1[mask]) * (ykis2[mask] - ykis1[mask])
unionk = (x2 - x1) * (y2 - y1) + (x2g - x1g) * (y2g - y1g) - intsctk + 1e-7
iouk = intsctk / unionk
c = ((xc2 - xc1) ** 2) + ((yc2 - yc1) ** 2) +1e-7
d = ((x_center - x_center_g) ** 2) + ((y_center - y_center_g) ** 2)
u = d / c
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w_gt/h_gt)-torch.atan(w_pred/h_pred)),2)
with torch.no_grad():
S = 1 - iouk
alpha = v / (S + v)
ciouk = iouk - (u + alpha * v)
iou_weights = bbox_inside_weights.view(-1, 4).mean(1) * bbox_outside_weights.view(-1, 4).mean(1)
iouk = ((1 - iouk) * iou_weights).sum(0) / output.size(0)
ciouk = ((1 - ciouk) * iou_weights).sum(0) / output.size(0)
return iouk, ciouk
def compute_giou(output, target, bbox_inside_weights, bbox_outside_weights,
transform_weights=None):
if transform_weights is None:
transform_weights = (1., 1., 1., 1.)
x1, y1, x2, y2 = bbox_transform(output, transform_weights)
x1g, y1g, x2g, y2g = bbox_transform(target, transform_weights)
x2 = torch.max(x1, x2)
y2 = torch.max(y1, y2)
xkis1 = torch.max(x1, x1g)
ykis1 = torch.max(y1, y1g)
xkis2 = torch.min(x2, x2g)
ykis2 = torch.min(y2, y2g)
xc1 = torch.min(x1, x1g)
yc1 = torch.min(y1, y1g)
xc2 = torch.max(x2, x2g)
yc2 = torch.max(y2, y2g)
intsctk = torch.zeros(x1.size()).to(output)
mask = (ykis2 > ykis1) * (xkis2 > xkis1)
intsctk[mask] = (xkis2[mask] - xkis1[mask]) * (ykis2[mask] - ykis1[mask])
unionk = (x2 - x1) * (y2 - y1) + (x2g - x1g) * (y2g - y1g) - intsctk + 1e-7
iouk = intsctk / unionk
area_c = (xc2 - xc1) * (yc2 - yc1) + 1e-7
giouk = iouk - ((area_c - unionk) / area_c)
iou_weights = bbox_inside_weights.view(-1, 4).mean(1) * bbox_outside_weights.view(-1, 4).mean(1)
iouk = ((1 - iouk) * iou_weights).sum(0) / output.size(0)
giouk = ((1 - giouk) * iou_weights).sum(0) / output.size(0)
return iouk, giouk
def smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, beta=1.0):
"""
SmoothL1(x) = 0.5 * x^2 / beta if |x| < beta
|x| - 0.5 * beta otherwise.
1 / N * sum_i alpha_out[i] * SmoothL1(alpha_in[i] * (y_hat[i] - y[i])).
N is the number of batch elements in the input predictions
"""
box_diff = bbox_pred - bbox_targets
in_box_diff = bbox_inside_weights * box_diff
abs_in_box_diff = torch.abs(in_box_diff)
smoothL1_sign = (abs_in_box_diff < beta).detach().float()
in_loss_box = smoothL1_sign * 0.5 * torch.pow(in_box_diff, 2) / beta + \
(1 - smoothL1_sign) * (abs_in_box_diff - (0.5 * beta))
out_loss_box = bbox_outside_weights * in_loss_box
loss_box = out_loss_box
N = loss_box.size(0) # batch size
loss_box = loss_box.view(-1).sum(0) / N
return loss_box
def clip_gradient(model, clip_norm):
"""Computes a gradient clipping coefficient based on gradient norm."""
totalnorm = 0
for p in model.parameters():
if p.requires_grad:
modulenorm = p.grad.data.norm()
totalnorm += modulenorm ** 2
totalnorm = np.sqrt(totalnorm)
norm = clip_norm / max(totalnorm, clip_norm)
for p in model.parameters():
if p.requires_grad:
p.grad.mul_(norm)
def decay_learning_rate(optimizer, cur_lr, decay_rate):
"""Decay learning rate"""
new_lr = cur_lr * decay_rate
# ratio = _get_lr_change_ratio(cur_lr, new_lr)
ratio = 1 / decay_rate
if ratio > cfg.SOLVER.LOG_LR_CHANGE_THRESHOLD:
logger.info('Changing learning rate %.6f -> %.6f', cur_lr, new_lr)
# Update learning rate, note that different parameter may have different learning rate
for param_group in optimizer.param_groups:
cur_lr = param_group['lr']
new_lr = decay_rate * param_group['lr']
param_group['lr'] = new_lr
if cfg.SOLVER.TYPE in ['SGD']:
if cfg.SOLVER.SCALE_MOMENTUM and cur_lr > 1e-7 and \
ratio > cfg.SOLVER.SCALE_MOMENTUM_THRESHOLD:
_CorrectMomentum(optimizer, param_group['params'], new_lr / cur_lr)
def update_learning_rate(optimizer, cur_lr, new_lr):
"""Update learning rate"""
if cur_lr != new_lr:
ratio = _get_lr_change_ratio(cur_lr, new_lr)
if ratio > cfg.SOLVER.LOG_LR_CHANGE_THRESHOLD:
logger.info('Changing learning rate %.6f -> %.6f', cur_lr, new_lr)
# Update learning rate, note that different parameter may have different learning rate
param_keys = []
for ind, param_group in enumerate(optimizer.param_groups):
if ind == 1 and cfg.SOLVER.BIAS_DOUBLE_LR: # bias params
param_group['lr'] = new_lr * 2
else:
param_group['lr'] = new_lr
param_keys += param_group['params']
if cfg.SOLVER.TYPE in ['SGD'] and cfg.SOLVER.SCALE_MOMENTUM and cur_lr > 1e-7 and \
ratio > cfg.SOLVER.SCALE_MOMENTUM_THRESHOLD:
_CorrectMomentum(optimizer, param_keys, new_lr / cur_lr)
def _CorrectMomentum(optimizer, param_keys, correction):
"""The MomentumSGDUpdate op implements the update V as
V := mu * V + lr * grad,
where mu is the momentum factor, lr is the learning rate, and grad is
the stochastic gradient. Since V is not defined independently of the
learning rate (as it should ideally be), when the learning rate is
changed we should scale the update history V in order to make it
compatible in scale with lr * grad.
"""
logger.info('Scaling update history by %.6f (new lr / old lr)', correction)
for p_key in param_keys:
optimizer.state[p_key]['momentum_buffer'] *= correction
def _get_lr_change_ratio(cur_lr, new_lr):
eps = 1e-10
ratio = np.max(
(new_lr / np.max((cur_lr, eps)), cur_lr / np.max((new_lr, eps)))
)
return ratio
def affine_grid_gen(rois, input_size, grid_size):
rois = rois.detach()
x1 = rois[:, 1::4] / 16.0
y1 = rois[:, 2::4] / 16.0
x2 = rois[:, 3::4] / 16.0
y2 = rois[:, 4::4] / 16.0
height = input_size[0]
width = input_size[1]
zero = Variable(rois.data.new(rois.size(0), 1).zero_())
theta = torch.cat([\
(x2 - x1) / (width - 1),
zero,
(x1 + x2 - width + 1) / (width - 1),
zero,
(y2 - y1) / (height - 1),
(y1 + y2 - height + 1) / (height - 1)], 1).view(-1, 2, 3)
grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, grid_size, grid_size)))
return grid
def save_ckpt(output_dir, args, model, optimizer):
"""Save checkpoint"""
if args.no_save:
return
ckpt_dir = os.path.join(output_dir, 'ckpt')
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
save_name = os.path.join(ckpt_dir, 'model_{}_{}.pth'.format(args.epoch, args.step))
if isinstance(model, mynn.DataParallel):
model = model.module
# TODO: (maybe) Do not save redundant shared params
# model_state_dict = model.state_dict()
torch.save({
'epoch': args.epoch,
'step': args.step,
'iters_per_epoch': args.iters_per_epoch,
'model': model.state_dict(),
'optimizer': optimizer.state_dict()}, save_name)
logger.info('save model: %s', save_name)
def load_ckpt(model, ckpt):
"""Load checkpoint"""
mapping, _ = model.detectron_weight_mapping
state_dict = {}
for name in ckpt:
if mapping[name]:
state_dict[name] = ckpt[name]
model.load_state_dict(state_dict, strict=False)
def get_group_gn(dim):
"""
get number of groups used by GroupNorm, based on number of channels
"""
dim_per_gp = cfg.GROUP_NORM.DIM_PER_GP
num_groups = cfg.GROUP_NORM.NUM_GROUPS
assert dim_per_gp == -1 or num_groups == -1, \
"GroupNorm: can only specify G or C/G."
if dim_per_gp > 0:
assert dim % dim_per_gp == 0
group_gn = dim // dim_per_gp
else:
assert dim % num_groups == 0
group_gn = num_groups
return group_gn
相关文章
- ValueError: day is out of range for month
- html中label及加上属性for之后的用法
- [RxJS] Use filter and partition for conditional logic
- [Angular] Create a custom validator for template driven forms in Angular
- [Javascript] Using map() function instead of for loop
- FlexCel for VCL Setup and Source Code
- Add-in Express for Office and Delphi VCL 10.4
- 【目标检测】29、Focal-EIoU:Focal and Efficient IOU Loss for Accurate Bounding Box Regression
- 【目标检测】27、GIoU:Generalized Intersection over Union:A Metric and A Loss for Bounding Box Regression
- GaussDB(for Redis)揭秘:Redis存算分离架构最全解析
- springMVC项目异步错误处理请求Async support must be enabled on a servlet and for all filters involved in async
- 迁移学习《Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation》
- 【文献学习】From learning to meta-learning: Reduced training overhead and complexity for communication Sys
- 《论文阅读》EmotionIC: Emotional Inertia and Contagion-driven Dependency Modeling for Emotion Recognition
- Myeclipse2017破解:成功解决me Trial expired 0 days ago mgeclipse It's now time to buy the best IDE for yo