
JavaSE进阶 | 深入理解Java IO流(目录拷贝、对象专属流、IO和Properties的联合使用)
目录
🥅ObjectInputStream && ObjectOutputStream
🥅目录拷贝
把一个目录拷贝到另一个目录(包括里面的内容)
需要用到:FileInputStream+FileOutputStream+File+递归的思想
package com.bjpowernode.java.io;
import java.io.*;
public class CopyAll {
public static void main(String[] args) {
// 拷贝源
File srcFile = new File("C:\\Java学习\\javaSE学习");
// 拷贝目标
File destFile = new File("D:\\a\\b\\c");
// 调用方法进行拷贝
copyDir(srcFile,destFile);
}
/**
* 拷贝目录
* @param srcFile 拷贝源
* @param destFile 拷贝目标
*/
private static void copyDir(File srcFile, File destFile) {
//4、递归结束的条件,如果是文件就结束(就开始拷贝)
if(srcFile.isFile()){
// 是文件的是要要拷贝文件,一边读一遍写
FileInputStream in = null;
FileOutputStream out = null;
try {
// 读文件
in = new FileInputStream(srcFile);
// 写文件
String path = (destFile.getAbsolutePath().endsWith("\\")?destFile.getAbsolutePath() :
destFile.getAbsolutePath()+"\\")+srcFile.getAbsolutePath().substring(3);
System.out.println(path);
out = new FileOutputStream(path);
// 一边读一边写
byte[] bytes = new byte[1024*1024];// 1M
int readCount = 0;
while((readCount = in.read(bytes)) != -1){
out.write(bytes,0,readCount);
}
// 刷新
out.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return; // srcFile如果是一个文件,递归结束
}
//1、 获取拷贝源下面的子目录
File[] files = srcFile.listFiles(); //列出源文件下的子目录(目录和文件)
// 这个file有可能是目录,也有可能是文件;但都是一个File对象
for(File file:files){
// 获取所有文件的(目录和文件)绝对路径;进行打印测试
//System.out.println(file.getAbsolutePath());
// 3、创建对应的目录(目标文件对应的目录,要提前创建好)
if(srcFile.isDirectory()){ // 如果是一个目录
// 新建对应的目录
String srcDir = file.getAbsolutePath(); // 拿出所有的源目录
// 这里如果只是一个盘符的话,写上"//"会被识别出来;如果后面有其它目录,就识别不了"//"
// srcDir.substring(3)表示从下标为3的地方开始截取
String destDir = (destFile.getAbsolutePath().endsWith("\\")? destFile.getAbsolutePath() :
destFile.getAbsolutePath()+"\\")+srcDir.substring(3); // 目标目录
// 获取路径后,开始创建
File newFile = new File(destDir);
if(!newFile.exists()){ // 如果不存在,就递归创建目录
newFile.mkdirs();
}
}
//2、 递归调用(是目录的话一直往下拿,直到是一个文件就开始拷贝)
copyDir(file,destFile);
}
}
}
🥅ObjectInputStream && ObjectOutputStream
序列化:用ObjectOutputStream类保存基本类型数据或对象的机制。方法为:
public final void writeObject (Object obj): 将指定的对象写出。反序列化:用ObjectInputStream类读取基本类型数据或对象的机制。方法为:
public final Object readObject (): 读取一个对象。
ObjectInputStream和ObjectOutputStream也都是包装流。
1、首先我们先明白两个概念:序列化(Serialize)和反序列化(DeSerialize)
序列化:将java对象存储到文件中,将java对象的状态保存下来的过程
反序列化:将硬盘上的数据重新恢复到内存当中,恢复成java对象
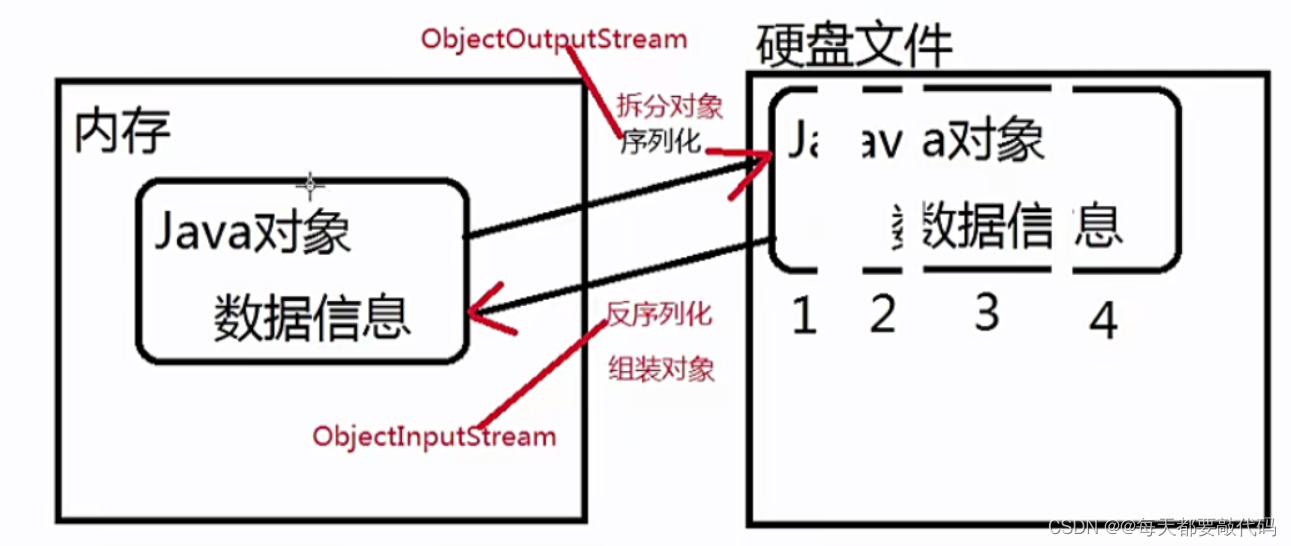
2、ObjectInputStream 和 ObjectOutputStream的作用
ObjectOutputStream是用来序列化的---》拆分对象,简单理解:写就是序列化
ObjectInputStream是用来反序列化的---》组装对象,简单理解:读就是反序列化
3、通过图,来理清楚它们之间的关系
1.序列化的实现
(1)参与序列化和反序列化的对象,必须实现Serializable接口。如果下面的Student类没有实现Serializable接口,会报java.io.NotSerializableException,译为:Student对象不支持序列化!
(2)注意:通过源代码发现,Serializable接口只是一个标志接口:
public interface Serializable {
}(3)这个接口当中什么代码都没有;那么它起到一个什么作用呢?
起到标识的作用,标志的作用,java虚拟机看到这个类实现了这个接口,可能会对这个类进行特殊待遇。Serializable这个标志接口是给java虚拟机参考的,java虚拟机看到Serializable这个接口之后,会为该类自动生成一个序列化版本号。(4)步骤:
第一步:准备一个Java对象,实现Serializable接口,例如:Student implements Serializable ;注意:要想完成序列化必须实现Serializable接口,这是和前面操作不同的地方
第二步:创建一个文件输出流FileOutputStream,参数要写入文件的名字;
第三步:创建一个ObjectOutputStream对象,因为是包装流,把上面的FileOutputStream流写进去;
第四步:调用writeObject把上面创建的Java对象传进去,这样就完成了序列化;
第五步:调用readObject方法就可以完成反序列化。
package com.bjpowernode.java.io;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class ObjectOutputStreamTest01 {
public static void main(String[] args) throws Exception {
// 创建Java对象
Student stu = new Student(111,"zhangsan");
// 序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("s文件"));
// 序列化对象,默认回去调用toString方法
oos.writeObject(stu);
// 刷新
oos.flush();
// 关闭
oos.close();
}
}
// 学生类
class Student<toString> implements Serializable {
private int no;
private String name;
// 构造方法
public Student() {
}
public Student(int no, String name) {
this.no = no;
this.name = name;
}
// setter and getter
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
// 重写toString
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
}2.反序列化的实现
package com.bjpowernode.java.io;
// 反序列化
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ObjectInputStreamTest01 {
public static void main(String[] args) throws Exception{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("s文件"));
// 开始反序列化,读
Object obj = ois.readObject();
// 反序列化回来是一个学生对象,所以会调用学生对象的toString方法。
System.out.println(obj);
// 关闭
ois.close();
}
}
3.序列化 && 反序列化多个对象
(1)可以一次序列化多个对象呢?
可以一次性序列化多个对象,例如:将对象放到ArrayList集合当中,序列化ArrayList集合!
(2)参与序列化的ArrayList集合中的Java对象都需要实现 java.io.Serializable接口(3)补充一个关键字:transient;这个关键字表示游离的,不参与序列化。
对于某个属性我们不希望它参与序列化,就可以在属性前面加上transient关键字,加上关键字以后;对于基本数据类型打印出来的是默认值,对于引用数据类型打印出来的是null !
(4)序列化集合,调用readObject()方法,实际上返回的还是一个Object对象,我们可以打印这个对象,一下子全部取出来;也可以把它强制类型转换为List集合,然后遍历集合,一个一个的取出来。
序列化
package com.bjpowernode.java.io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
public class ObjectOutputStreamTest02 {
public static void main(String[] args) throws Exception {
// 创建集合
List<User> userList = new ArrayList<>();
// 增加元素
userList.add(new User(1,"zhangsan"));
userList.add(new User(2,"lisi"));
userList.add(new User(3,"wangwu"));
// 序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("Users"));
// 序列化集合--->一次性序列化多个对象
oos.writeObject(userList);
// 刷新
oos.flush();
// 关闭
oos.close();
}
}
// USer类
class User implements Serializable {
private int num;
// 表示name不参与序列化操作;name打印出来的结果就是null
private transient String name;
// 构造方法
public User() {
}
public User(int num, String name) {
this.num = num;
this.name = name;
}
// setter and getter
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
// 重写toStringF方法
public String toString() {
return "User{" +
"num=" + num +
", name='" + name + '\'' +
'}';
}
}反序列化
package com.bjpowernode.java.io;
import java.util.List;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
// 反序列化
public class ObjectInputStreamTest02 {
public static void main(String[] args) throws Exception {
// 开始反序列化,读
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("Users"));
// 反序列化回来还是Object对象
Object obj = ois.readObject();
//System.out.println(obj instanceof List); // true,得到返回的是List集合
// 反序列化回来一个List集合
List<User> userList = (List<User>)ois.readObject();
for(User u:userList){
System.out.println(u);
}
// 关闭
ois.close();
}
}
4.序列化版本号
(1)java语言中是采用什么机制来区分类的?
第一:首先通过类名进行比对,如果类名不一样,肯定不是同一个类。
第二:如果类名一样,再怎么进行类的区别?可以通过包名;如果包名和类名都相同呢?靠序列化版本号进行区分。(2)序列化版本号有什么用呢?
小鹏编写了一个类:com.bjpowernode.java.bean.Student implements Serializable
胡浪编写了一个类:com.bjpowernode.java.bean.Student implements Serializable所以序列化版本号是用来区分类的!例如:类名相同,我们可以通过不通的序列化版本号来区分它;对于但也有缺点,对于同一个代码,我们更改了,必须重新编译才可以!
例如:对于上述的Student类,我们采用默认的序列化版本号,一年前我们实现了这个功能,有一个序列化版本号;一年后我们优化更改了代码,此时JVM就会认为这已经不是同一个类,必须重新进行编译,才能反序列化
(3)自动生成序列化版本号的好处和缺陷?好处:不同的人编写了同一个类,但“这两个类确实不是同一个类”;这个时候序列化版本就起上作用了。对于java虚拟机来说,java虚拟机是可以区分开这两个类的,因为这两个类都实现了Serializable接口,都有默认的序列化版本号,他们的序列化版本号不一样。所以区分开了。)
缺陷:这种自动生成的序列化版本号缺点是一旦代码确定之后,不能进行后续的修改,因为只要修改,必然会重新编译,此时会生成全新的序列化版本号,这个时候java虚拟机会认为这是一个全新的类。(4)总结:从需求来看
凡是一个类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号。这样,以后这个类即使代码修改了,但是版本号不变,java虚拟机会认为是同一个类。Java虚拟机看到Serializable接口之后,会自动生成一个序列化版本号。这里没有手动写出来,java虚拟机会默认提供这个序列化版本号。建议将序列化版本号手动的写出来,不建议自动生成 。
private static final long serialVersionUID = 1L; // 定义为常量java虚拟机识别一个类的时候先通过类名,如果类名一致,再通过序列化版本号。
(5)设置IDEA自动生成序列版本号
如果我们不想手动输入序列化版本号,想让IDEA自动给我们生成一个怎们办呢?需要进行设置:File--->Settings--->Editor--->Code Style--->Inspections--->JVM languages--->把下面这个打上对勾--->Apply--->OK
最终回到我们继承Serializable接口的类名上,alt+Enter即可自动生成序列版本号!

总结自定义类要想实现序列化机制,需要满足:
① 自定义类需要实现接口:Serializable
② 要求自定义类声明一个全局常量: static final long serialVersionUID = 42234234L;用来唯一的标识当前的类。
③ 要求自定义类的各个属性也必须是可序列化的。
> 对于基本数据类型的属性:默认就是可以序列化的
> 对于引用数据类型的属性:要求实现Serializable接口④ 如果不声明全局常量serialVersionUID,系统会自动声明生成一个针对于当前类的serialVersionUID。如果修改此类的话,会导致serialVersionUID变化,进而导致反序列化时,出现InvalidClassException异常。
⑤类中的属性如果声明为transient或static,则不会实现序列化。
🥅IO和Properties联合使用
(1)设计理念:把以后经常改变的数据,可以单独写到一个文件中,使用程序动态读取。
将来只需要修改这个文件的内容,java代码不需要改动,不需要重新编译,服务器也不需要重启;就可以拿到动态的信息。(2)类似于以上机制的这种文件被称为配置文件;并且当配置文件中的内容格式是:
key1=value
key2=value
的时候,我们把这种配置文件叫做属性配置文件,在属性配置文件当中#注释,如果key重复的话,value会自动覆盖。(3)java规范中有要求:属性配置文件建议以.properties结尾,但这不是必须的。这种以.properties结尾的文件在java中被称为:属性配置文件;其中Properties是专门存放属性配置文件内容的一个类。
(4)Properties是一个Map集合,key和value都是String类型。
(5)步骤:
第一步:先准备一个jdbc.properties文本文件
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql:/localhost:8080/bjpowernode
username=root
password=1223
第二步:创建一个文件输入流FileReader(FileInputStream也可以)
第三步:创建一个集合Properties(继承HashTable,key和value只能存String类型)
第四步:调用集合的load(reader流)方法,加载上面的文件流到集合当中
第五步:调用集合的getProperties(key)方法获取,里面的参数的key就是jdbc.properties前面的值
package com.bjpowernode.io;
import java.io.*;
import java.util.Properties;
// IO + Properties读属性配置文件
public class Test {
public static void main(String[] args) {
FileReader reader = null;
try {
// 第一步:创建输入流对象
reader = new FileReader("jdbc.properties");
// 第二步:创建IO流
Properties properties = new Properties();
// 第三步:调用load方法加载
properties.load(reader);
// 第四步:获取
System.out.println(properties.getProperty("driver"));
System.out.println(properties.getProperty("url"));
System.out.println(properties.getProperty("username"));
System.out.println(properties.getProperty("password"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
// 关闭流
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
执行结果如下:

相关文章
- Java实现 LeetCode 688 “马”在棋盘上的概率(DFS+记忆化搜索)
- Java实现 LeetCode 409 最长回文串
- Java实现 LeetCode 173 二叉搜索树迭代器
- Java实现 LeetCode 19删除链表的倒数第N个节点
- Java实现 基础算法 求100以内的质数
- java实现放麦子问题
- java实现第四届蓝桥杯连号区间数
- java实现第六届蓝桥杯九数分三组
- Java内存管理:Java内存区域 JVM运行时数据区
- Java 11正式发布,这几个逆天新特性教你写出更牛逼的代码
- linux(ubuntu21.10):安装jdk-17(java 17.0.3.1)
- 华为OD机试 - 开心消消乐(Java & JS & Python)
- JavaSE进阶 | 深入理解Java IO流(缓冲流、转换流、数据流、标准输出流、File类)
- JavaSE进阶 | 深入理解Java IO流(文件专属流)
- 【Java】java中javaSE与javaEE的区别
- JavaSE入门学习5:Java基础语法之keyword,标识符,凝视,常量和变量
- JavaSE学习总结(四)——Java面向对象十分钟入门
- JavaSE学习总结(三)——Java语言编程练习、格式化字符与常量
- JavaSE学习总结(二)——Java语言基础
- 《Java并发编程实战》第四章 对象的组合 读书笔记