
使用azkaban调度spark任务
这篇文章主要向大家介绍使用azkaban调度spark任务,主要内容包括基础应用、实用技巧、原理机制等方面,希望对大家有所帮助。
Azkaban是一种相似于Oozie的工作流控制引擎,能够用来解决多个Hadoop(或Spark等)离线计算任务之间的依赖关系问题。
也能够用其代替cron来对周期性任务进行调度,而且更为直观,可靠,同时提供了美观的可视化管理界面。
下文将对azkaban对spark离线任务调度进行简要说明。
一. 简介
该部份内容可参考官方文档:http://azkaban.github.io/azkaban/docs/latest/#overviewgithub
azkaban由三部分构成:
- Relational Database(Mysql)
- Azkaban Web Server
- Azkaban Executor Server
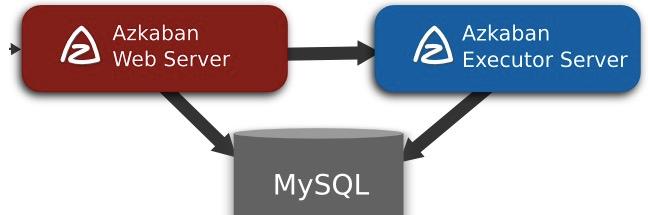
Relational Database(Mysql)
azkaban将大多数状态信息都存于Mysql中,Azkaban Web Server 和 Azkaban Executor Server也需要访问DB。
Azkaban Web Server
提供了Web UI,是azkaband的主要管理者,包括 project 的管理,认证,调度,对工作流执行过程的监控等。
Azkaban Executor Server
调度工作流和任务,记录工作流任务的日志,因此将AzkabanWebServer和AzkabanExecutorServer分开,主要是由于在某个任务流失败后,能够更方便的将重新执行。并且也更有利于Azkaban系统的升级。
可调度任务类型
- linux命令
- 脚本
- java程序
- hadoop MR
- spark
- flink
- hive
建立工做
-
建立工做任务
建立.job为后缀的文件,type是工做任务类型执行会输出 Hello Worldvim hello.job type=command command=echo "Hello World" -
建立工作流
两个工做任务,经过dependencies进行关联vim foo.job type=command command=echo foo vim bar.job type=command dependencies=foo command=echo bar工作流如下:
将会先调用foo再调用bar。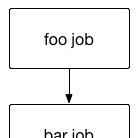
二. 调度Spark任务Demo
建立一个新的project
编写代码 写一段简单的Spark代码,将程序打包
package com.zxl
import org.apache.spark.{SparkConf, SparkContext}
object AzkabanTest extends App{
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("azkabanTest")
val sc = new SparkContext(conf)
val data = sc.parallelize(1 to 10)
data.map{_ * 2}.foreach(println)
}
编写调度命令
vim test.job
type=command
command=/usr/install/spark/bin/spark-submit --class com.zxl.AzkabanTest test-1.0-SNAPSHOT.jar
将这两个文件以zip的形式打包在一块儿
zip -r xxx.zip azkabanTest
上传工程
目前azkaban只支持zip包,其中要包括.job文件以及一些需要的工程和文件。
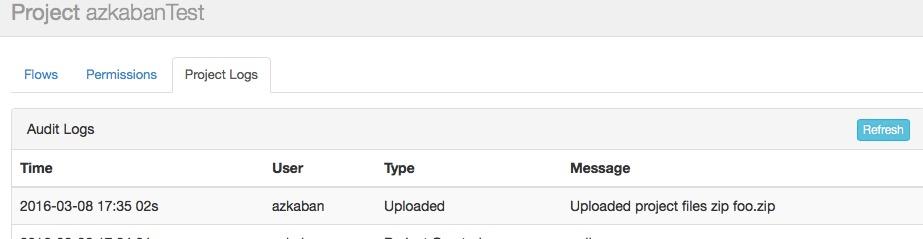
设置离线任务执行周期
若是需要的话能够设置离线任务的执行周期(相似于cron的功能)
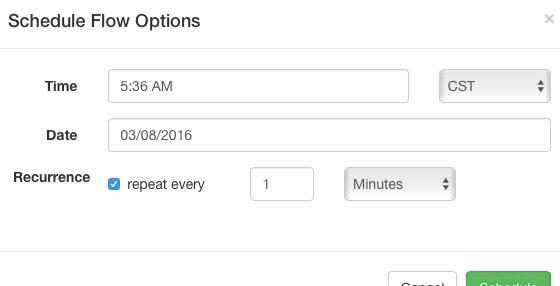
任务通知
能够设置任务完成或失败进行邮箱通知等操作。
一些界面
主界面
任务完成状况

任务log详情
定时任务调用状况图

相关文章
- spark-shell脚本分析
- 大叔经验分享(60)hive和spark读取kudu表
- 大叔问题定位分享(2)spark任务一定几率报错java.lang.NoSuchFieldError: HIVE_MOVE_FILES_THREAD_COUNT
- Spark修炼之道(高级篇)——Spark源码阅读:第三节 Spark Job的提交
- Spark修炼之道(高级篇)——Spark源码阅读:第一节 Spark应用程序提交流程
- Spark修炼之道(基础篇)——Linux大数据开发基础:第九节:Shell编程入门(一)
- 【docker脚本收藏】docker-compose部署hadoop、spark等大数据各组件
- 【收藏】使用springboot构建rest api远程提交spark任务
- spark on yarn参数: 任务优先级
- spark任务优先级设置:spark.yarn.priority
- spark on yarn任务提交及运行完整流程图
- Spark集群搭建+基于zookeeper实现高可用HA
- Livy安装使用(Spark rest接口服务工具)
- spark集成kafka数据源
- 《数据算法:Hadoop_Spark大数据处理技巧》艾提拉笔记.docx 第1章二次排序:简介 19 第2章二次排序:详细示例 42 第3章 Top 10 列表 54 第4章左外连接 96 第5
- 【Spark Core】任务运行机制和Task源代码浅析1
- spark中文文档
- Spark任务提交底层原理
- Spark 进程模型