
Leetcode0127. 单词接龙(difficult,双向BFS)
目录
1. 问题描述
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:5 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:0 解释:endWord "cog" 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/word-ladder
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
2. 方法一:广度优先搜索
2.1 思路
感觉这个问题leecode433(Leetcode0433. 最小基因变化(medium,BFS))就是换汤不换药嘛。
另外跟leetcode752(Leetcode0752. 打开转盘锁(medium,BFS))也很相似,只不过leetcode752中是四位数的数码,本题换成换成单词了。可选项以wordlist的形式出现,而在leetcode752中是以一个规则加上一个forbidden列表相结合给出。
采用和leetcode433相同的解决方案。为了方便以广度优先搜索的方式进行图搜索:先将beginWord与wordlist进行合并,然后以每个单词作为图中的一个节点间邻接列表。然后基于该邻接节点进行搜索。
注意,如果endWord不在wordList中的话肯定无法转换。
2.2 代码实现
这个代码其实基本上就是在leetcode433的基础上稍微做了一些细微的修改而得。
import time
from typing import List
from collections import deque
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
def diff_is_one(s1,s2)->bool:
cnt=0
for k in range(len(s1)):
if s1[k]!=s2[k]:
cnt+=1
return cnt==1
# Construct adjacency list first
endIdx = -1
wordList.insert(0, beginWord)
for k,word in enumerate(wordList):
if endWord==word:
endIdx = k
if endIdx<0:
return 0
adjlist = [ [] for k in range(len(wordList)) ]
for k in range(len(wordList)):
for j in range(k,len(wordList)):
if diff_is_one(wordList[k], wordList[j]):
adjlist[k].append(j)
adjlist[j].append(k)
# print(bank,adjlist)
q = deque([(0,0)])
visited = set([0])
while len(q)>0:
node,layer = q.popleft()
if node == endIdx:
return layer+1
for nxt in adjlist[node]:
if nxt not in visited:
q.append((nxt,layer+1))
visited.add(nxt)
return 0
if __name__ == "__main__":
sln = Solution()
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log","cog"]
print(sln.ladderLength(beginWord, endWord, wordList))
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
print(sln.ladderLength(beginWord, endWord, wordList))
with open('No0127-testcase.py','r') as f:
exec(f.read())
tstart=time.time()
print(sln.ladderLength(beginWord, endWord, wordList))
tstop=time.time()
print('tcost = {0:4.2f}(sec)'.format(tstop-tstart)) 提交超时。
也不意外,毕竟leetcode是medium,这个是difficult。要是同一套代码直接提交成功了,怎么对得起difficult的级别。
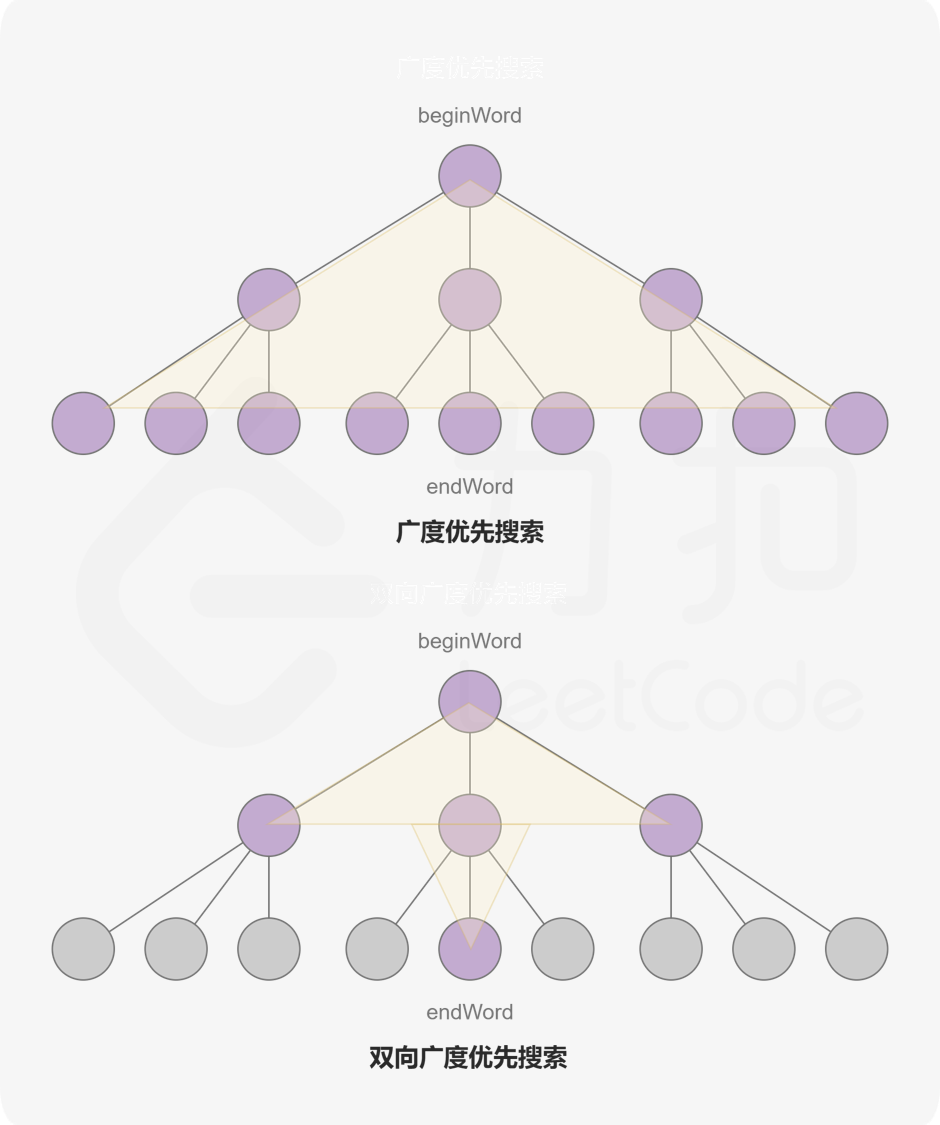
3. 方法二:双向广度优先搜索
3.1 思路
同时从两端出现进行广度优先搜索。
中途如果一方从队列中弹出的节点出现在对方已访问列表中,双方搜索碰头,则表示搜索成功。
与上面单端搜索不同的是,在已访问列表中也需要记忆layer信息,以便于碰头时计算两者走过的距离总和。
因此visited改用dict来表示。
双向广度优先搜索示意图如下(摘自力扣官解):
3.2 代码
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
def diff_is_one(s1,s2)->bool:
cnt=0
for k in range(len(s1)):
if s1[k]!=s2[k]:
cnt+=1
return cnt==1
# Construct adjacency list first
endIdx = -1
wordList.insert(0, beginWord)
for k,word in enumerate(wordList):
if endWord==word:
endIdx = k
if endIdx<0:
return 0
adjlist = [ [] for k in range(len(wordList)) ]
for k in range(len(wordList)):
for j in range(k,len(wordList)):
if diff_is_one(wordList[k], wordList[j]):
adjlist[k].append(j)
adjlist[j].append(k)
# print(bank,adjlist)
q1 = deque([(0,0)])
visited1 = dict()
visited1[0] = 0
q2 = deque([(endIdx,0)])
visited2 = dict()
visited2[endIdx] = 0
while len(q1)>0 or len(q2)>0:
if len(q1)>0:
node1,layer1 = q1.popleft()
if node1 in visited2:
return layer1+visited2[node1]+1
for nxt in adjlist[node1]:
if nxt not in visited1:
q1.append((nxt,layer1+1))
visited1[nxt]=layer1+1
if len(q2)>0:
node2,layer2 = q2.popleft()
if node2 in visited1:
return layer2+visited1[node2]+1
for nxt in adjlist[node2]:
if nxt not in visited2:
q2.append((nxt,layer2+1))
visited2[nxt]=layer2+1
return 0三下两下码完双向广度优先搜索,以为这总可以了吧。不过拿刚才单向方案提交报超时的testcase一测,OMG!居然时间没有什么差异,只有10%左右的改善,显然这也是不行的。
不明白为什么。容我再想一想。
看了看官解,还要加上个优化建图的元素。。。感觉智商欠费脑力耗竭,改日再战。
回到主目录:笨牛慢耕的Leetcode每日一解题解笔记(动态更新。。。)
相关文章
- Java实现 LeetCode 648 单词替换(字典树)
- Java实现 LeetCode 434 字符串中的单词数
- Java实现 LeetCode 318 最大单词长度乘积
- Java实现 LeetCode 139 单词拆分
- Java实现 LeetCode 127 单词接龙
- Java实现 LeetCode 58 最后一个单词的长度
- Java实现 蓝桥杯VIP 算法提高 不同单词个数统计
- Java实现 蓝桥杯VIP 算法提高 不同单词个数统计
- Java实现 蓝桥杯VIP 算法训练 统计单词个数
- LeetCode(58): 最后一个单词的长度
- 每日一道 LeetCode (13):最后一个单词的长度
- 编程笔试(解析及代码实现):国内各大银行(招商银行/浦发银行等)在线笔试常见题目(猴子吃桃/字符串逆序输出/一段话输出字的个数/单词大小转换等)及其代码实现(Java/Python/C#等)之详细攻略
- 力扣——1160. 拼写单词(Java、C、python3实现)
- 单词数 (STL set集合)
- 【华为机试 Python实现】HJ27 查找兄弟单词(中等)
- 【华为机试真题 Python实现】单词接龙游戏【2022 Q2 | 100分】
- 1967. 作为子字符串出现在单词中的字符串数目字符串模式匹配-kmp算法和kmp优化算法(双百代码)
- NC269 翻转单词序列
- [LeetCode] 139. 单词拆分 ☆☆☆(动态规划 回溯)
- spark uniq 本质上就是单词计数
- Hive mapreduce SQL实现原理——SQL最终分解为MR任务,而group by在MR里和单词统计MR没有区别了
- Java如何将每个单词的第一个字符转为大写?