
Memcached · 最佳实践 · 热点 Key 问题解决方案
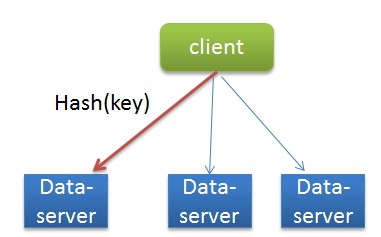
在分布式K-V存储系统中,对某个key进行读写时,会根据该key的hash计算出一台固定的server来存取该K-V,如果集群不发生服务器数量变化,那么这一映射关系就不会变化。
云数据库 memcached 就是这样一种K-V缓存系统。在实际应用中的某些高峰时段,有的云数据库 memcached 用户会大量请求同一个Key(可能对应应用的热卖商品、热点新闻、热点评论等),所有的请求(且这类请求读写比例非常高)都会落到同一个server上,该机器的负载就会严重加剧,此时整个系统增加新server也没有任何用处,因为根据hash算法,同一个key的请求还是会落到同一台新机器上,该机器依然会成为系统瓶颈。这个问题称为“热点key”问题。
用户使用云数据库 memcached 就是为了提升业务性能,难免会触发“热点key问题”。但云数据库memcached做为公有云服务,在发现有热点的情况下,如果继续放任该热点无限激增,就会带来整个系统雪崩。所以当前的做法是对每个用户在每台服务器上分配一定的QPS或带宽,当用户在某台服务器上的请求超过该用户的配额,我们就会对用户进行流控,服务端返回TEMPORARY_FAILURE,该限制会影响用户正常请求,持续时间分钟级。
用户触发热点问题是业务需要,是理所当然;云数据库 memcached 对热点 key 进行流控是保障系统稳定性,也在情理之中。但有没有一种既能提供用户热点 key 访问的需求,又能保护云数据库memcached服务器的方法呢,这正是本文所要阐述的。
解决热点问题有很多办法,比如用户如果提前知道某些key可能成为热点,那么客户端可以提前拆分热点key;也可以搭建一个备用集群,写的时候双写,然后随机双读。这些方案的实现前提和难度可想而知,下面给出的是对应用透明,且动态发现热点的解决方案。
本方案解决的是用户读热点问题,不解决写热点问题。
首先,云数据库memcached简单架构图如下:
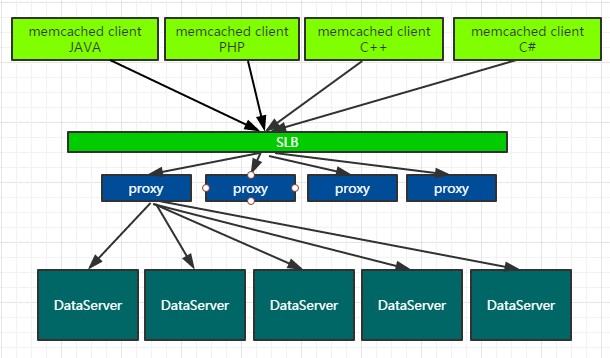
我们的proxy是无状态层,上面做了些访问控制功能,用户客户端到proxy是随机的,不受固定算法(如hash)控制。而proxy到DataServer的链路是根据key决定的,当用户访问热点key时,所有proxy上关于该key的请求都会落到同一台DataServer。
所以解决热点问题,其核心思路是:每台DataServer对所有key进行采样、定位,实时计算出当前热点key,将其反馈给proxy层,由proxy缓存备份。即负载压力由DataServer转向proxy。理由是:Proxy可以无状态扩容,而DataServer不可以。
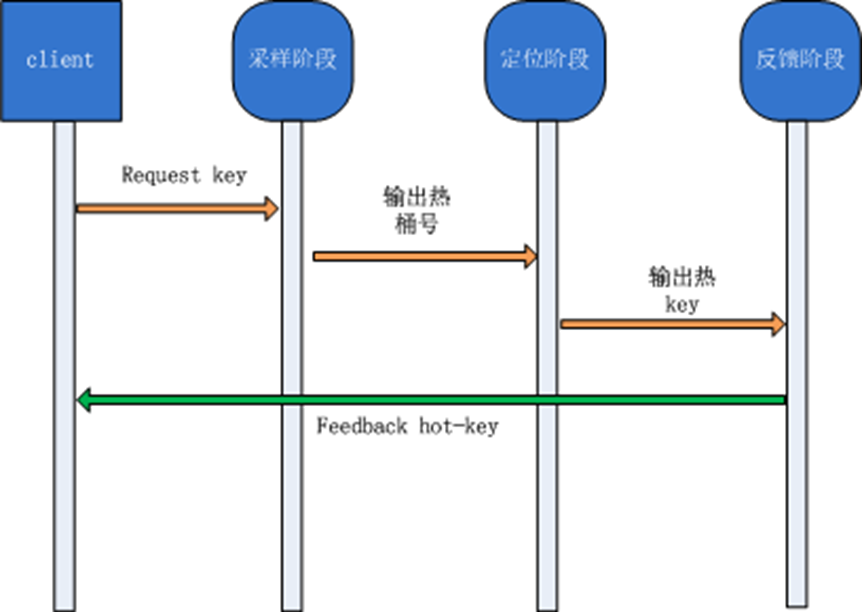
DataServer如何发现热点每台服务器有个HotKey逻辑,让每个到达服务器的目标请求(可配置不同类型请求)经历三个流水阶段:
采样阶段(根据配置设定采样次数sample_max)本阶段输出:是否有热点现象,如果有热点,输出热点的桶号供下阶段使用。 定位阶段(根据配置设定采样次数reap_max)
本阶段输出:热点key(如果满足阈值),并添加到服务端的LRU链表。 反馈阶段
对到达服务器的目标请求,取出key,然后查询LRU链表判断该key是否为热点key。如果是热点,就会在请求结束后,向proxy发送一个feedback包,通知proxy。
至此,服务器hot-key逻辑结束。流程图如下:
当Proxy收到DataServer的热点反馈之后,会将该key写入到自己的LRU-cache里面,该cache的过期时间和容量大小都交由用户通过控制台设置,默认分别是100ms和30。这样热点的key就已经存在于与proxy中了,下次用户请求就可以直接返回了。
如何保证数据一致性呢?下面讨论都是用户client已经触发了热点key问题,假设用户client跟每个proxy都建立了链接,并且每个proxy上都有对热点key的请求,那么理论上每个proxy的LRU-cache都有一份数据。
我们保证单条连接上的一致性。
当用户client和proxy1建立连接,用户修改了一个key(任何写操作),proxy1上会在LRU-cache中同步删除该key,新key就会写到DataServer上,然后在读数据的时候,由于LRU-cache不命中,就会从DataServer上拿到最新数据。
不同链接上只能提供弱一致性。
如果这个时候用户从proxy2上读热点数据呢?理论上就会读到老数据,该数据将于100ms之后从proxy-cache中过期淘汰掉,之后就会更新会最新数据,即不同连接间可能有100ms不一致。
怎样看待弱一致性。
事实上,不开启热点key功能,在不同链接上也会存在弱一致。假设用户client建立了两条链接到云数据库memcached,在链接1上写入key-value1,在链接1、2上分别读该key。当链接1上用户update了key-value2,这个请求需要一定的网络延迟才能写入到服务端,如果这个时候链接2上同时发起对key的读取操作,如果读请求先到服务端,它将读到的是value1的老值。
所以开启热点key功能,只是增加了不一致时间,且该功能为可选,控制权由用户掌握。
由以上分析可以看到,开启热点key功能之后,只会对用户的读请求产生影响,该影响增加了不同链接上的弱一致性的时间。因此,该功能适合读多写少,且对强一致性要求不高的应用。
整个方案核心是负载压力由DataServer转移到Proxy。好处如下:
因为DataServer扩容也解决不了热点问题,而Proxy可以无状态扩容,对用户来讲就极大提升了热点key访问的能力,不受单点制约; 缩短了服务端处理链路,对用户平均RT也所降低; 免除服务端热点流控的分钟级别影响。腾讯架构师是如何解释:Redis高性能通信的原理(精华版) 我们一直说Redis的性能很快,那为什么快?Redis为了达到性能最大化,做了哪些方面的优化呢? 在深度解析Redis的数据结构 这篇文章中,其实从数据结构上分析了Redis性能高的一方面原因。
Redis 在互金核心账务系统中的场景实践 Redis是一款开源的、网络化的、基于内存的、可进行数据持久化KEY-VALUE的存储系统。Redis通过KEY映射VALUE的方式来建立字典来保存数据,支持多类型存储包括STRING、LIST,SET,SORT SET和HASH等,可以在这些数据类型上做很多原子性操作。Redis将数据存储在内存里面,而且它发送给Redis的命令请求不需要经过典型的查询分析器(PARSER)或查询优化器(OPTIMIZER)处理,所以Redis对自身存储的数据执行随机读写的速度是非常快速的。
MySQL · 内核特性 · 统计信息的现状和发展 简介我们知道查询优化问题其实是一个搜索问题。基于代价的优化器 ( CBO ) 由三个模块构成:计划空间、搜索算法和代价估计 [1] ,分别负责“看到”最优执行计划和“看准”最优执行计划。如果不能“看准”最优执行计划,那么优化器基本上就是瞎忙活,甚至会产生严重的影响,出现运算量特别大的 SQL ,造成在线业务的抖动甚至崩溃。在上图中,代价估计用一个多项式表示,其系数 c 反应了硬件环境和算子特性,而
MongoDB·最佳实践·count不准原因分析 一般来说,除了由于secondary延迟可能造成查询secondary节点数据不准以外,关于count的准确性问题,在MongoDB4.0官方文档中有这么一段话On a sharded cluster, db.
深度解析双十一背后的阿里云 Redis 服务 摘要: Redis是一个使用范围很广的NOSQL数据库,阿里云Redis同时在公有云和阿里集团内部进行服务,本文介绍了阿里云Redis双11的一些业务场景:微淘社区之亿级关系链存储、天猫直播之评论商品游标分页和菜鸟单据履行中心之订单排序。
Redis · lazyfree · 大key删除的福音 redis重度使用患者应该都遇到过使用 DEL 命令删除体积较大的键, 又或者在使用 FLUSHDB 和 FLUSHALL 删除包含大量键的数据库时,造成redis阻塞的情况;另外redis在清理过期数据和淘汰内存超限的数据时,如果碰巧撞到了大体积的键也会造成服务器阻塞。
Redis · 引擎特性 · 基于 LFU 的热点 key 发现机制 业务中存在访问热点是在所难免的,redis也会遇到这个问题,然而如何发现热点key一直困扰着许多用户,redis4.0为我们带来了许多新特性,其中便包括基于LFU的热点key发现机制。 Least Frequently Used Least Frequently Used——简称LFU,意为最不经常使用,是redis4.0新增的一类内存逐出策略,关于内存逐出可以参考文章《Redis数据过期和淘汰策略详解》。
db匠 rds内核团队秘密研发的全自动卖萌机. 追加特效: 发数据库内核月报. 月报传送: http://mysql.taobao.org/monthly/
相关文章
- C# 序列化与反序列化之DataContract与xml对子类进行序列化的解决方案
- Spring MVC无法获取到页面表单put过来的参数的解决方案
- This dependency was not found: * !!vue-style-loader!css-loader?……解决方案
- 【问题解决方案】GitHub克隆项目到本地
- 【UNITY3D 游戏开发之八】UNITY编译到IPHONE运行 COLLIDER 无法正常触发事件解决方案
- EasyDSS流媒体解决方案实现的RTMP/HLS视频直播、直播鉴权(如何完美将EasyDSS过渡到新版)
- UI自动化关闭远程桌面连接,鼠标键盘失效的解决方案
- Atitit 跨平台的系统截图解决方案
- atitit.身份认证解决方案attilax总结
- 缓存穿透,缓存击穿,缓存雪崩解决方案分析
- 注解 @ 或者 Alt+/ 不提示 或者提示 no default propsals 解决方案
- 广播解决方案:Livemind Recorder:录音机
- Android 12.0 内置app编译报错编不过的解决方案
- Leetcode1736. 替换隐藏数字得到的最晚时间(解决方案太Low了)
- Android一些解决方案内存问题(一)
- android sqlite批量插入数据速度解决方案
- 002-权限管理解决方案