
【数据库设计与实现】第1章:空间管理与数据布局
数据库设计数据布局和空间管理应当考虑哪些因素呢?又有哪些设计原则?本章先提出问题,看有哪些因素要考虑,然后选取Oracle和MySQL这2款最流行的数据库,看看它们是如何进行空间管理的。我们先看看有哪些因素要考虑:
- 数据最终要反映到持久设备上,空间管理首先要考虑持久设备(如磁盘)的物理特性,考虑如何组织数据才能最大化地发挥存储设备的效率;
- 如何协调平衡多样化的数据,如超大的单表和数据庞大的小表,持久数据和临时数据,系统管理数据和用户数据,索引数据和非索引数据等等;
- 如何平衡数据的逻辑相关性和逻辑独立性,逻辑相关性要求将逻辑上相关的数据聚集在一起,提高联合访问的效率,而逻辑独立性又要求将逻辑上独立的数据独立存放,提高数据失效、迁移、变更的效率;
- 如何平衡并发度和空间利用率,并发度要求尽可能将所有相关的持久化设备都调动起来,将设备能力尽可能均衡地用满,而空间利用率则要求尽可能紧凑地利用空间,避免空间区域和碎片,提高扫描效率;
Oracle的tablespace由若干个datafile组成,datafile以extent为单位进行空间的申请和释放。可以这么说,datafile是空间的提供者,而segment是空间的使用者,两者之间的交互语言就是extent和block。
图1.2-1 Block结构
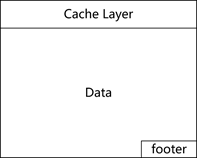
表1.2-1 Cache Layer结构
域 | 长度 | 含义 |
type | 1 | 本Block的类型,可以取值:
|
frmt | 1 | 格式,标识不同的block版本 |
spare1/2 | 2 | 保留 |
rdba | 4 | 相对block地址,前10个bit为相对文件id,后22个bit为block号,可见1个tablespace可以有1023个datafile,每个datafile可以有4M个block |
scn | 6 | 本block最近一次更新时的scn |
seq | 1 | 如果更新本block时scn相同,则seq加1 |
flg | 1 | 组合标志位:
|
chkval | 2 | flg的CHECKSUM标志为真时,写入前对block计算CHECKSUM,并填入本域,后继读出时会再次计算并检查,防止块损坏 |
spare3 | 2 | 保留 |
表1.2-2 footer结构
域 | 长度 | 含义 |
seq | 1 | 等于cache layer中的seq |
type | 1 | 等于cache layer中的type |
filter | 2 | 数据文件:等于cache layer中scn的末尾2个byte 控制文件:control seq |
block是数据管理的基本单元,在讨论datafile空间管理方式之前,我们先讨论一下block。如图1.2-1所示,所有的block都有3个部分组成:
- Cache layer:定义block的总体信息,详情如表1.2-1所示;
- Data:block中存放的内容,具体内容随cache layer中的type不同而不同;
- Footer:如果block发生了更改,scn和seq至少有一个会变动,通过比较footer和cache layer中的对应部分就可以检测块损坏(如写入磁盘时,写入一半掉电的情况),当然cache layer中还有chkval,如果启用可以提供更强的校验能力;
图1.2-2 datafile文件结构

了解了block基本文件结构之后,我们开始讨论datafile是如何提供空间的。如图1.2-2所示,datafile由Data File Header、KTFB Bitmapped File Space Header、KTFB Bitmapped File Space Bitmap和Data组成,其中Data File Header、KTFB Bitmapped File Space Header、KTFB Bitmapped File Space Bitmap为文件保留区,保留区占用的block数随db_block_size的变化而变化(如2KB保留32个block,4KB保留16个block,8KB保留8个block,16KB和32KB保留4个block),下面详细看下各个部分的含义:
- Data File Header:描述本datafile的总体信息,Cache Layer.type=0x0b,block size为8KB时占用2个block,详情见表1.2-3;
- KTFB Bitmapped File Space Header:描述bitmap的总体信息,Cache Layer.type=0x1d,block size为8KB时占用1个block,详情见表1.2-4;
- KTFB Bitmapped File Space Bitmap:完整的bitmap,用于描述本datafile中各个extent的详细情况,Cache Layer.type=0x1e,block size为8KB时占用5个block,详情见表1.2-5;
- Data:用于存放具体数据;
表1.2-3 Data File Header部分关键信息
域 | 含义 |
dbid | 本文件归属的db id |
dbname | 本文件归属的db name |
tablespace | 本文件归属的tablespace |
file number | 本文件的文件编号(dba、uba等地址中都会含文件编号) |
prev file | 归属于同1个tablepace的前1个datafile |
file size | 本文件的大小 |
file type | 本文件的类型,3表示数据文件 |
blksize | block的大小 |
checkpoint | checkpoint系统信息 |
backup | backup系统信息 |
表1.2-4 KTFB Bitmapped File Space Header部分关键信息
域 | 含义 |
RelFno | 相对文件编号 |
Unit | 单元数,即bitmap中每个bit位代表的block数 |
Size | 本datafile包含的block数 |
AutoExtent | 对应于create tablespace语法 |
MaxSize | 对应于create tablespace语法 |
tail | 本文件最后1个block |
first | 本文件第一个处于free状态的unit地址 |
free | free状态的unit数量 |
表1.2-5 KTFB Bitmapped File Space Bitmap部分关键信息
域 | 含义 |
beginblock | 存放data的block地址,前面的区域存放Data File Header、KTFB Bitmapped File Space Header、KTFB Bitmapped File Space Bitmap |
flag | 0永久文件,1临时文件 |
first | 本block中第1个可用的unit位置 |
free | 本block中free的unit数量 |
map | 1个bit代表1个unit,0表示free,1表示used |
在KTFB Bitmapped File Space Bitmap Block中,对于统一尺寸的extent来说,unit等于extent,即1个bit位代表1个extent。对于自动管理来说,extent的大小是变化的,1个bit位代表1个最小尺寸的extent。由于大extent一定是小extent的整数倍,所以unit将最小exent作为基准,即1个bit位代表64K。当extent的实际大小是1M、8M、64M时就用多个bit位来表示,如1M的extent就用连续的16个bit来标识。
从空间利用率来看,由于某个extent只能属于某个特定的segment,所以小extent空间利用率高,大extent空间利用率低。例如当extent的大小为64M时,表哪怕仅使用了1个字节,也为它分配1个64M的extent,这64MB空间完全属于这个表,其它表无法使用。从性能的角度来看,大的extent空间比较连续,非常适合全表扫描类操作。Oracle的动态管理方式在空间利用率、性能之间做了平衡。
图1.2-3 segment 3级bitmap管理机制
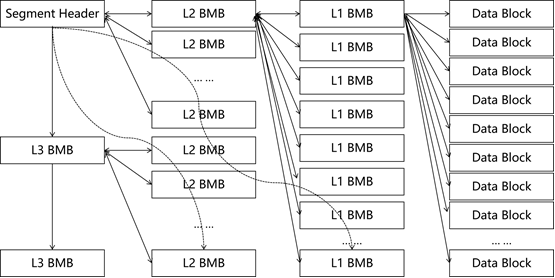
通过上节我们知道,datafile是通过bitmap管理表空间的extent分配情况。segment作为实际使用者,需要更加精确地知道本segment中各block的使用情况。如图1.2-3所示,segment是通过3级位图机制对block进行精细化管理的:
- L1 BMB(BitMap Block):详细描述了其管理的各data block的空间使用情况,并有指向其归属的L2 BMB指针,详细情况见表1.2-6;
- L2 BMB:记录了其管理的所有L1 BMB地址,并有指向其归属的L3 BMB指针,详细情况见表1.2-7;
- L3 BMB:记录了其管理的所有L2 BMB地址,并有指向其归属的segment header block指针,实际上segment header block本身就是一个特殊的L3 BMB;
表1.2-6 L1 BMB部分关键信息
一级域 | 二级域 | 含义 |
parent dba | 其归属的L2 BMB地址 | |
unformatted | 未格式化的block数量 | |
total | MAP中block总数 | |
first useful block | MAP中第1个可用的block | |
MAP(*n) | offset | extent的地址,即extent中首个block的地址 |
length | extent中block的数量 | |
bits | 标识extent中各个block的状态,每个block的状态占用4个bit位:
| |
表1.2-7 L2 BMB部分关键信息
一级域 | 二级域 | 含义 |
parent dba | 其归属的L3 BMB地址或segment header block地址 | |
number | MAP中L1 BMB的数量 | |
nfree | MAP中尚有空闲空间的L1 BMB数量 | |
ffree | MAP中已满的L1 BMB数量 | |
MAP(*n) | dba | L1 BMB的地址 |
free | 5:空闲; 0:FULL; | |
随着申请的data block越来越多,需要不断地申请L1 BMB、L2 BMB和L3 BMB进行管理。实际上,通过L1 BMB和L2 BMB已经能够管理非常庞大的data block数量,使用L3 BMB的情况非常少见(当然data segment header block本身就是一个特殊的L3 BMB)。在高并发时,存在多个L1 BMB可用,分散了争用,提高了并发性,可以获得非常高的性能:
- 通过data segment header block找到第1个含空闲空间的L2 BMB(L2 Hint for inserts);
- 对操作进程PID做HASH运算,得到随机数N,在L2 BMB中找到第N个L1 BMB;
- 对操作进程PID做HASH运算,得到随机数M,在L1 BMB中找到第M个有空闲空间的data block;
- 向找到的data block插入数据;
实际插入算法更加复杂,既要考虑一定的随机性和离散性,避免并发插入在特定的data block和BMB上竞争,又要考虑一定的聚集性,提高空间利用率和数据扫描效率(实际上会优先插入HWM以下的data block),最终算法在两者之间进行平衡。
图1.2-4 data segment header block结构
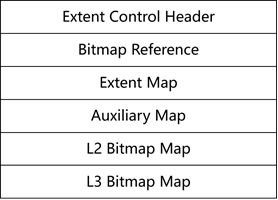
表1.2-8 Extent Control Header部分关键信息
一级域 | 二级域 | 含义 |
extents | 本segment的extent数量 | |
blocks | 本segment的block数量(不含segment header block) | |
High HWM | HWM | High HWM的地址 |
ext | High HWM在哪个extent上 | |
blk | High HWM在该extent的哪个bock上 | |
ext size | High HWM所在的extent有多大 | |
blocks below | 本segment中处于High HWM下的block数量 | |
Low HWM | HWM | Low HWM的地址 |
ext | Low HWM在哪个extent上 | |
blk | Low HWM在该extent的哪个bock上 | |
ext size | Low HWM所在的extent有多大 | |
blocks below | 本segment中处于Low HWM下的block数量 | |
L1 BMB for high HWM block | High HWM所在的block归属的L1 BMB | |
L1 BMB for low HWM block | Low HWM所在的block归属的L1 BMB | |
nl2 | 本segment中L2 BMB的数量 | |
blksz | block的大小 | |
L2 array start offset | L2 Bitmap Map在segment header block中的偏移 | |
First level3 BMB | L3 BMB链表头 | |
Last level3 BMB | L3 BMB链表尾 | |
L2 hint for inserts | 从本L2 BMB开始查找空闲空间供插入 | |
Last level2 BMB | 最新的L2 BMB | |
Last level1 BMB | 最新的L1 BMB | |
表1.2-9 Extent Map和Auxiliary Map部分关键信息
一级域 | 二级域 | 含义 |
next | 下一个map block的地址,随着extent数量的不断增长,data segment header block中就不够存放,这时会申请独立的map(type=0x12 extent map block)存放多出来的map | |
extents | extent的数量 | |
Extent Map(*n) | dba | extent的地址 |
length | extent的block数量 | |
Auxiliary Map(*n) | extent index | 数组下标,虚拟列 |
L1 dba | 管理该extent的L1 BMB地址,1个L1 BMB可以管理多个extent,1个extent只能归属于1个L1 BMB管理 | |
data dba | 该extent中首个data block的地址,extent中可能有L1 BMB、L2 BMB、L3 BMB、Extent Map Block、Segment Header Block等等,这些Metadata Block一般处于extent的头部 | |
如图1.2-4所示,data segment header block包含如下几个关键部分:
- 通过extent control header、L3 BMB、L2 BMB、L1 BMB就可以知道所有data block的空间使用情况、HWM情况,然后进行高并发的插入操作;
- 通过extent control header、extent map、auxiliary map就可以知道所有数据的分布情况、HWM情况,进行高效的数据扫描,即从extent map起始extent开始扫描,扫描至Low HWM,对于Low HWM和high HWM之间的block,需要参考L1 BMB,以避开尚未格式化的block;
图1.2-5 extent内block分布示例
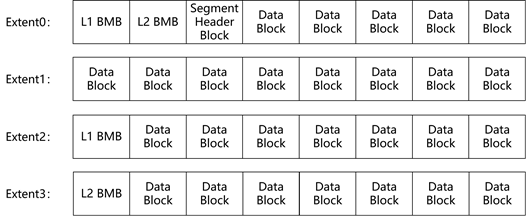
最后再看一下extent内的block分布情况,不管block是何种类型,最终都要落到extent内,接受以extent为单位的连续空间管理。图1.2-5给出了extent内block的分布示例,如果extent内存在metadata类型的block,一般都存放在extent的头部。extent在使用和分配上存在如下规律:
- 延迟分配,建表时不分配extent,只有在实际插入数据时才会分配extent;
- 非统一大小时,extent的大小是动态变化的(以block size等于8K为例):
- 0-15 extent,每个extent包括8个block,此时segment总大小<=1M,每个L1 BMB可以管理16个block;
- 16-79 extent,每个extent包括128个block,此时segment总大小<=32M,每个L1 BMB可以管理64个block;
- 80-199 extent,每个extent包括1024个block,此时segment总大小<=1G,每个L1 BMB可以管理256个block;
- >199 extent,每个extent包括8192个block,此时segment总大小>1G,每个L1 BMB可以管理1024个block;
- 有些情况下1个L1 BMB会管理多个extent,所以有的extent中没有L1 BMB,有些情况下1个L1 BMB无法将单个extent中的所有block都管理起来,此时extent中就会有多个L1 BMB;
- 当tablespace由多个datafile组成时,extent分片会考虑一定的均衡性,segment会分布在多个datafile中,但单个extent不会跨datafile;
图1.2-6 data block结构
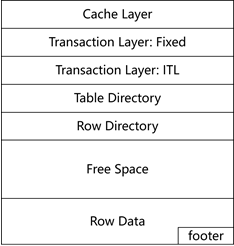
表1.2-10 Table Directory部分关键信息
域 | 长度 | 含义 |
flag | 1 | N=pctfree hit(clusters) F=don’t put on free list K=flushable cluster keys |
ntab | 1 | 本data block涉及的table数,只有clusters才可能大于1 |
nrow | 2 | 本data block中的记录数 |
frre | 2 | 空闲行的位置,初始为0,-1表示满了 |
fsbo | 2 | Free space的起始偏移 |
fseo | 2 | Free space的结尾偏移 |
avsp | 2 | Data block中空闲空间大小 |
tosp | 2 | 所有事务提交后总可用空间大小 |
表1.2-11 Row Directory部分关键信息
域 | 长度 | 含义 |
offs | 1 | clusters表时有效 |
nrow | 1 | 第1个表的行数 |
rowoff*n | 2 | Array,每行记录占1个位置,记录改行记录在Row Data中位置。记录在Row Directory中的下标是RowID组成部分之一 RowId=Seg/Obj Number + File Number + Block Number + Row Number,其中Row Number就是Row Directory中的下标 |
表1.2-10 Row Data部分关键信息
域 | 长度 | 含义 |
fb | 1 | K=cluster key C=cluster table member H=head piece of row D=deleted row F=first data piece L=last data piece P=first column continues from previous piece N=last column continues in next piece
|
lb | 1 | 本行记录被ITL中的哪个事务给锁住了 |
cc | 1 | 记录的列数,超过255列就需要行链接 |
data | var | 数据,每列数据由length+data组成,length的情况:
|
如图1.2-6所示,data block和数据存储强相关的部分主要包括Row Directory和Row Data,Oracle的data block设计有如下特点:
- row directory:行目录,array型结构,每行记录占用2个字节,指向该行记录在Row Data中的位置。array的下标是RowID的组成部分,所以某行记录一旦落到block中,其在row directory中的位置就不能改变(row data是可以被整理的),因为index、行迁移、行链接等都是通过RowID来定位的;
- row data:每行记录的头部大小应尽可能地小,从而提高空间利用率。fb、lb、cc仅占用3个字节,每列的length部分也是变长的,且对于取值为null的number类型列,直接通过length=0xff来表示,不再占用data空间;
- 随着行记录的增加,row directory从上向下增长,row data从下向上增长;
- data block如果写入过满,将来update操作很可能产生较多行迁移,影响查询性能,为此通过PCTFree参数定义插入时预留多少空间出来,用于将来的update(pctfree对data block,以及B树的leaf block有效,但对B树的root block和branch block无效);
Oracle中有system tablesapce、sysaux tablespace、temporary tablespace、undo tablespace和permanent tablespace,其存放的数据分别如下:
- system tablespace:存放数据字典;
- sysaux tablespace:存放工具相关对象信息;
- temporary tablespace:存放临时数据,以及在内存不足时作为诸多活动的辅助空间(如排序);
- undo tablespace:存放undo日志(前像);
- permanent tablespace:存放用户数据;
应用可以根据实际情况创建多个temporary tablespace、undo tablespace和permanent tablespace。同时还可以设置bigfile属性,以容纳更大的数据量。每个tablespace都按照segment进行管理,规则如下:
- 1个表创建1个segment,如果是分区,每个分区创建1个segment;
- 1个索引创建1个segment,如果是分区索引,每个分区索引创建1个segment;
- 表的每个CLOB、BLOB或者NCLOB列都会创建1个segment,如果这些列上有索引,还会创建对应的LOB索引segment;
MySQL同样也采用了tablespace、segment、extent、page(对应oracle中的block)这几个概念,tablespace由若干个datafile组成,datafile以extent为单位进行空间的申请和释放。不同的是MySQL将extent分成了2种:
- extent:正常的extent,1个extent大小为1M,由连续的page组成,segment以extent为单位申请和释放空间;
- frag extent:特殊的extent,1个frag extent也是连续的1M空间,但是frag extent不属于任何segment,而是为大家共用。MySQL不支持变长extent,为了节约空间,每个segment的前32个page在frag extent中申请page,超过32个page再以extent为单位申请空间;
图1.3-1 page结构
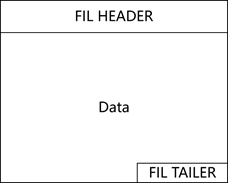
表1.3-1 FIL HEADER结构
域 | 长度 | 含义 |
FIL_PAGE_SPACE_OR_CHKSUM | 4 | 4.0版本前存space id,之后存checksum值 |
FIL_PAGE_OFFSET | 4 | page no |
FIL_PAGE_PREV | 4 | B-Tree叶子page的前1个page,用于索引扫描 |
FIL_PAGE_NEXT | 4 | B-Tree叶子page的下1个page,用于索引扫描 |
FIL_PAGE_LSN | 8 | 本page的LSN,标识本page的最近一次修改 |
FIL_PAGE_TYPE | 2 | page类型: FIL_PAGE_INDEX FIL_PAGE_UNDO_LOG FIL_PAGE_INODE FIL_PAGE_IBUF_FREE_LIST FIL_PAGE_TYPE_SYS |
FIL_PAGE_FIL_FLUSH_LSN | 8 |
|
FIL_PAGE_SPACE_ID | 4 | 本page的space id |
表1.3-2 FIL TAILER结构
域 | 长度 | 含义 |
FIL_CHECKSUM | 4 | 本page的checksum,用于校验异常page |
FIL_PAGE_LSN | 4 | 等于FIL HEADER中的FIL_PAGE_LSN,用于检测page写一半系统掉电的异常情况 |
page是MySQL datafile空间管理的基本单位,其结构如1.3-1所示,组成部分如下:
- FIL HEADER:page头,定义了page的总体信息,详细情况见表1.3-1;
- Data:数据部分,格式随着FIL_PAGE_TYPE不同而不同;
- FIL TAILER:page尾,用于校验异常page,详细情况见表1.3-2;
图1.3-2 datafile总体空间布局

了解page的结构,下面看总体空间布局。如图1.3-2所示,MySQL数据文件空间布局相对比较固定,非常有规律可循:
- FIL_PAGE_TYPE_XDES:该类page存放extent的管理信息,当page size确定后每个FIL_PAGE_TYPE_XDES page可以管理的extent数量是固定的,这样本page就可以按照管理的extent数有规律地存放。图1.3-2示例是page size为16K的情况,每个FIL_PAGE_TYPE_XDES page可以管理256个extent,每个extent包含64个page,所以FIL_PAGE_TYPE_XDES page每隔16384(256*64)个page出现1个;
- FIL_PAGE_TYPE_HDR:FIL_PAGE_TYPE_HDR和FIL_PAGE_TYPE_XDES非常类似,除了存放extent管理信息之外,还多了一个SPACE HEADER结构,作为空间管理的总入口,可以这么说,FIL_PAGE_TYPE_HDR是一个特殊的FIL_PAGE_TYPE_XDES。本类page只有1个,且固定在第0个位置上;
- FIL_PAGE_IBUF_BITMAP:本类page存放每个page的空闲情况以及IBUF的使用情况,由于FIL_PAGE_IBUF_BITMAP和FIL_PAGE_TYPE_XDES管理的规模一样多,所以FIL_PAGE_IBUF_BITMAP page永远跟在FIL_PAGE_TYPE_XDES page后面,位置固定;
- FIL_PAGE_INODE:本类page存放各segment的入口信息,page的类型为FIL_PAGE_INODE,位置不固定;
图1.3-3 FIL_PAGE_TYPE_HDR vs FIL_PAGE_TYPE_XDES

表1.3-3 XDES Entry结构
域 | 长度 | 含义 |
XDES_ID | 8 | 其归属的segment id |
FLST_PREV | 6 | 链表指针,指向前1个XDES Entry,前4个字节为该Entry的page no,后2个字节为page内偏移 |
FLST_NEXT | 6 | 链表指针,指向后1个XDES Entry,前4个字节为该Entry的page no,后2个字节为page内偏移 |
XDES_XSTATE | 4 | 表示本XDES Entry处在哪个链表上:
|
XDES_BITMAP | 16 | 16*8,共计128个bit位,每2个bit位对应1个page,1个bit标识该page是否为空(XDES_FREE_BIT),另1个bit预留; |
表1.3-4 SPACE HEADER结构
域 | 长度 | 含义 |
FSP_SPACE_ID | 4 | space id |
FSP_NOT_USED | 4 | 保留 |
FSP_SIZE | 4 | 本tablespace的page总数,自动扩展时会不断增加 |
FSP_FREE_LIMIT | 4 | 小于本数的page都尚未初始化,该数以后的page都尚未加入到FREE LIST中 |
FSP_SPACE_FLAGS | 4 | 32个bit位,各位的含义如下:
|
FSP_FRAG_N_USED | 4 | FSP_FREE_FRAG链表上已经被使用的page数 |
FSP_FREE | 16 | 链表指针,指向空extent(所有page都为空)链表 |
FSP_FREE_FRAG | 16 | 链表指针,指向含空闲空间的frag extent链表 |
FSP_FULL_FRAG | 16 | 链表指针,指向已经用满的frag extent链表 |
FSP_SEG_ID | 8 | 当前系统最大segment id+1,作为分配segment id的计数器 |
FSP_SEG_INODES_FULL | 16 | 链表指针,指向完全用满的inode page链表 |
FSP_SEG_INODES_FREE | 16 | 链表指针,指向尚有空闲空间的inode page链表 |
下面详细对比一下FIL_PAGE_TYPE_HDR page和FIL_PAGE_TYPE_XDES page,如图1.3-3所示,两者的结构基本是一样的。FIL_PAGE_TYPE_HDR page的SPACE HEADER结构是有信息的,而FIL_PAGE_TYPE_XDES page的对应位置为空。SPACE HEADER结构存放的是空间管理的总入口信息,所以只需要存在于第0个page中。在讨论SPACE HEADER前,先看一下XDES Entry结构。如表1.3-3所示,XDES Entry通过XDES_BITMAP标识其管理的extent中各page的空间状态,FLST_PREV和FLST_NEXT双向指针将处于相同状态且归属于同1个segment的XDES Entry链接在一起。那么这些链表的头指针在哪里呢?在SPACE HEADER结构中,如表1.3-4所示,SPACE HEADER作为总入口,管理着如下5个重要的链表:
- FSP_FREE链表:管理所有空的extent,指向状态为XDES_FREE的XDES Entry;
- FSP_FREE_FRAG链表:管理所有含空闲空间的frag extent,指向状态为XDES_FREE_FRAG的XDES Entry;
- FSP_FULL_FRAG链表:管理所有已经写满的frag extent,指向状态为XDES_FULL_FRAG的XDES Entry,随着frag extent的满和不满,对应的XDES Entry会在FSP_FREE_FRAG链表和FSP_FULL_FRAG链表之间移动;
- FSP_SEG_INODES_FULL、FSP_SEG_INODES_FREE链表:分别管理所有已经写满和尚未写满的INDOES;
- 链表头结构:FLST_LEN 4个字节+FLST_FIRST 6个字节+FLST_LAST 6个字节,共计16个字节,FLST_LEN表示链表长度,FLST_FIRST指向第1个节点(4个字节的page no+2个字节的page内偏移),FLST_LAST指向最后1个节点;
通过FSP_FREE_FRAG和FSP_FULL_FRAG链表将所有frag extent管理起来,通过FSP_FREE链表将所有尚未分配给segment的空闲extent管理起来,那么已经分配给segment的extent又是如何管理的呢?实际上,就是通过FSP_SEG_INODES_FULL和FSP_SEG_INODES_FREE链表进行间接管理的,我们将在segment机制章节进一步讨论。
图1.3-4 FIL_PAGE_IBUF_BITMAP结构
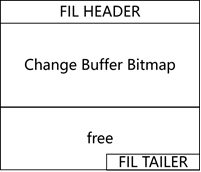
表1.3-5 Change Buffer Bitmap结构
域 | 长度 | 含义 |
IBUF_BITMAP_FREE | 2bit | 某个page的空闲情况,0(0bytes),1(512bytes),2(1024bytes),3(2048bytes) |
IBUF_BITMAP_BUFFERED | 1bit | 某个page上是否存在ibuf缓存 |
IBUF_BITMAP_IBUF | 1bit | 某个page本身是否是ibuf BTree的节点 |
最后再看一下FIL_PAGE_IBUF_BITMAP page,MySQL发明了Insert Buffer机制,并将其进一步通用化为Change Buffer机制。其核心思想是对非唯一的二级索引进行insert、delete时,如果对应的page不在缓存中,不必将该page调度进缓存进行实时操作,而是将insert、delete操作缓存到insert buffer page中,待将来读到该page或者后台purge线程再实施真正的insert、delete操作,从而提高效率。但insert buffer机制存在如下约束和要求:
- 唯一索引上的insert操作不能缓存,因为要做唯一性校验,必须读到真正的page才能做唯一性校验;
- insert buffer是以BTree组织的,缓存的每条记录的主键为spaceid、page no、counter,通过spaceid、page no记录缓存的操作时针对哪个page的,但这就要求page no在缓存过程中不能发生变化,这就需要一个机制来及时识别page no是否可能发生变化;
- 还需要一个机制来识别某个page上的操作是否有缓存,从而在读到该page时,先将缓存的操作merge进来,然后再实施真正的读处理;
FIL_PAGE_IBUF_BITMAP page就是为这些目的而设计的,FIL_PAGE_IBUF_BITMAP page固定在FIL_PAGE_TYPE_XDES page后面。如图1.3-4所示,change buffer bitmap中每4个bit对应后面的1个page,8192个字节就可以管理16384个page(8192*8/4)。如表1.3-5所示,4个bit的组成如下:
- IBUF_BITMAP_FREE:给出某个特定page的空闲情况,如果空闲空间过小,会发生page分裂,page no会发生变化,不能缓存,否则可以缓存;
- IBUF_BITMAP_BUFFERED:标识某个特定page上是否做了操作缓存;
- IBUF_BITMAP_IBUF:标识某个特定page本身缓存的一部分;
图1.3-5 FIL_PAGE_INODE page结构

表1.3-6 INODE Entry结构
域 | 长度 | 含义 |
FSEG_ID | 8 | 本INODE归属的segment,0表示未使用 |
FSEG_NOT_FULL_N_USED | 8 | FSEG_NOT_FULL链表上已被使用的page数 |
FSEG_FREE | 16 | 链表头,指向已分配给本segment,但尚未使用的extent链表 |
FSEG_NOT_FULL | 16 | 链表头,指向属于本segment,但尚未用满的extent链表 |
FSEG_FULL | 16 | 链表头,指向属于本segment,且已完全用满的extent链表 |
FSEG_MAGIC_N | 4 | 仅在调试模式下使用 |
FSEG_FRAG_ADDR | 128 | 32*4,管理32个frag page(分布在frag extent中的page),4个字节记录page no |
MySQL是通过INODE Entry管理segment的,每个INODE Entry对应1个segment。下面结合存放INODE Entry的FIL_PAGE_INODE page一起来讨论。如图1.3-5所示,FIL_PAGE_INODE page包括如下2个部分:
- FSEG_INODE_PAGE_NODE:12个字节的双向指针,将相关的FSEG_INODE_PAGE_NODE page链接在一起。实际上有2个FSEG_INODE_PAGE_NODE链表,就是FIL_PAGE_TYPE_HDR page中的FSP_SEG_INODES_FULL和FSP_SEG_INODES_FREE链表,前者将所有已经写满INODE Entry的FSEG_INODE_PAGE_NODE page链接在一起,后者将尚未写满INODE Entry的FSEG_INODE_PAGE_NODE page链接在一起;
- INODE Entry:1个FSEG_INODE_PAGE_NODE page中可以存放n个INODE Entry(随page的大小变化),每个INODE Entry管理1个具体的segment;
如表1.3-6所示,INODE Entry管理着1个具体的segment,其中的关键信息如下:
- FSEG_FREE、FSEG_NOT_FULL、FSEG_FULL:3个extent链表的指针头,结合XDES Entry结构中的双向指针,把已经分配给本segment的extent按照尚未使用、已使用但尚未用满、已经用满3种情况管理起来;
- FSEG_FRAG_ADDR:通过记录page号,将frag extent中分配给本segment的32个page管理起来;
图1.3-6 空间管理全貌

至此,如图1.3-6所示,我们得到MySQL空间管理的全景图(不含ibuf):
- SPACE HEADER中的FSP_FREE结合XDES Entry将所有尚未分配给segment的extent管理起来;
- SPACE HEADER中的FSP_FREE_FRAG和FSP_FULL_FRAG结合XDES Entry将所有尚未用满和已经用满的frag extent管理起来;
- SPACE HEADER中的FSP_SEG_INODES_FREE和FSP_SEG_INODES_FULL结合FSEG_INODE_PAGE_NODE将所有尚未用满和已经用满的FIL_PAGE_INODE管理起来;
- 每个segment有1个INODE Entry(存在于FIL_PAGE_INODE中),通过FSEG_FULL、FSEG_NOT_FULL、FSEG_FREE结合XDES Entry将所有分配给本segment的已经用满、尚未用满、尚未使用的extent管理起来;
- frag extent既被SPACE HEADER管理,其中的page同时又被INODE Entry中的FSEG_FRAG_ADDR管理;
图1.3-7 data page结构

表1.3-7 PAGE HEADER结构
域 | 长度 | 含义 |
PAGE_N_DIR_SLOTS | 2 | page directory区域的槽位数量 |
PAGE_HEAP_TOP | 2 | 堆中空闲空间的偏移量 |
PAGE_N_HEAP | 2 | 堆中记录的数量,包括用户记录、系统记录、标记为删除的记录,同时第1个bit位为1时表示记录格式为compact |
PAGE_FREE | 2 | 指向第1条标记为删除的记录,记录头有next,可以将所有标记为删除的记录链接在一起 |
PAGE_GARBAGE | 2 | 标记为删除的记录总空间(行记录的delete flag为1),属于可回收的空间 |
PAGE_LAST_INSERT | 2 | 指向最近1次插入的记录,用于优化顺序插入 |
PAGE_DIRECTION | 2 | 最后1条记录的插入方向:
标识当前记录的插入顺序,用于插入优化 |
PAGE_N_RECS | 2 | 以相同方向连续插入记录的数量 |
PAGE_MAX_TRX_ID | 8 | 本page内有效用户记录数,不含系统记录和标记为删除的记录 |
PAGE_LEVEL | 2 | 当前page在BTree中的层级,叶子节点取值为0 |
PAGE_INDEX_ID | 8 | 索引id,本page属于哪个索引 |
表1.3-8 segment info结构
域 | 长度 | 含义 |
FSEG_HDR_SPACE | 4 | 本segment对应的inode entry所在page的space id |
FSEG_HDR_PAGE_NO | 4 | 本segment对应的inode entry所在page的page no |
FSEG_HDR_OFFSET | 2 | 本segment对应的inode entry在所在page内偏移 |
如图1.3-7所示,data page除了通用的FIL HEADER和FIL TAILER之外,其它关键组成部分如下:
- PAGE HEADER:描述了本page的总体信息,详细见表1.3-7,通过PAGE_FREE和每条记录中的REC_NEXT,将所有标志为删除的记录链接在一起;
- SEGMENT INFO:仅在BTree的root page中设置,SEGMENT INFO1记录叶子节点segment对应的INODE信息,SEGMENT INFO2记录非叶子节点segment对应的INODE信息;
- SYS RECORDS:2条特殊的系统记录,infimum和supremun,占用26个字节,用于MySQL特有的边界定位和锁控制;
- USER RECORDS:用户记录,从上向下增长;
- PAGE DIRECTORY:目录,从下向上增长,每个slot占用2个字节,指向USER RECORDS中的具体某条记录。目录中的slot和记录不是一一对应的,每4到8条记录在目录中占用1个slot;
有效的用户记录(删除标志位不为真)和2条系统记录通过记录头的REC_NEXT链接在一起,链接的顺序即为索引的键值顺序,且infimum永远是第1条记录,而supremum永远是最后1条记录。为了加快记录匹配效率,MySQL在page的底部设计了DIRECTORY区域,每隔4-8条记录占用1个slot(slot对应多少条记录是动态变化的,slot之间也不相等,就某个slot来说,通过对应记录头的REC_NEW_N_OWNED记录相应的记录数)。由于DIRECTORY区域是有序的(按主键或索引键逆序存放),可以通过折半查找快速匹配到目标记录。
图1.3-8 compact记录格式

表1.3-9 RECORD HEADER结构
域 | 长度 | 含义 |
REC_NEW_INFO_BITS | 4bits | 仅使用了前2个bit,1个bit位标记本行记录是否已经被删除,另1个bit位标记本行记录是否为BTree当前Level最左边page的第1条用户记录 |
REC_NEW_N_OWNED | 4bits | 非0表示本行记录在page directory中占1个slot,具体取值为本slot和下1个slot之间的记录数 |
REC_NEW_HEAP_NO | 13bits | 本行记录在堆中的序号,用于MySQL的锁机制 |
REC_NEW_STATUS | 3bits | 记录的类型:
|
REC_NEXT | 16btis | 指向本page中的下1条记录,用于2中情况:
|
compact格式已经成为MySQL的主流格式。如图1.3-8所示,compact记录格式包括如下组成部分:
- RECORD_HEADER:记录的头部信息,详情如表1.3-9所示,记录在page内的偏移一般都是指RECORD HEADER的位置,因为记录的其它几个部分都是变长的;
- VAR_COL_LEN_LST:每个变长列的实际长度在此描述,最大长度小于255或者实际长度小于128占1个字节,否则占2个字节;
- NULL_BITS:每个可为NULL的列在此占1个bit,如果列的实际值为NULL,此bit位为真,ROW_DATA部分不会出现此列;
- ROW_DATA:实际列数据,聚集索引会增加事务id(6个字节)和回滚指针(7个字节)2个隐藏列;
MySQL的数据包括系统数据、临时数据、回滚数据、用户数据、重做数据和binlog数据,重做数据和binlog数据相对独立,和tablespace没有太大关系,下面重点看其它几个数据的布局:
- 用户数据:InnoDB的所有表都是索引组织表,每个索引创建2个segment,1个segment存放叶子节点page,1个segment存放非叶子节点page。每张表存放的tablespace随着历史的演进有3种方案:
- 早期版本:所有数据都存放在1个公共的系统tablespace中;
- 其后版本:增加支持每张表有1个独立的tablespace中;
- 近期版本:增加支持通用的tablespace;
- 系统类数据(InnoDB):主要有数据字典数据和系统数据,存放在公共的系统tablespace中。字典数据表有SYS_TABLES、SYS_INDEXS、SYS_COLUMNS、SYS_FIELDS,分别存放表信息、索引信息、表列信息、索引列信息,也采用索引组织表方式存放。系统数据有insert buf、double write、事务系统数据等等;
- 临时数据:存放用户创建的临时表,对应临时tablespace;
- 回滚数据:存放回滚数据,包括rollback segment和undo log segment,早期版本存放在公共的系统tablespace中,近期版本可存放在独立的undo tablespace中;
Oracle和MySQL的空间布局总体上非常类似,采用tablespace、segment、extent、block(page) 4层管理机制。extent和block(page)最大化地发挥持久设备的物理特性,tablespace和segment用于在逻辑上平衡数据的独立性和相关性。不过在管理设计上,Oracle和MySQL还是存在非常大的差异性。
在block(page)层面,Oracle的block设计更加通用,MySQL的page设计与索引组织表深度耦合,具体表现在:
- 对于单条记录,MySQL设计了NULL_BITS,稀疏场景下可以有效节省空间。不过MySQL的记录头和隐藏列比较厚重,每条记录占用18个字节(RECORD HEADER占5个字节,事务id占6个字节,回滚指针占7个字节),Oracle的记录头仅占3个字节;
- MySQL的page也设计相对比较粗放,某些区域仅在特定场景下有效,如SEGMENT INFO仅在BTree的root page中有效,FIL_PAGE_PREV和FIL_PAGE_NEXT仅对BTree的叶子节点page有效等等;
- Oracle采用了相对地址管理方式,RowID中保存了file no、block no、directory id,优势是可以快速定位记录,缺点是block内的碎片整理可以比较高效,但block间的整理涉及记录在block间移动,代价非常高(shrink table,调整rowid,涉及面较广)。MySQL采用的是主键管理方式,数据和索引解耦,优势是不仅可做page内的碎片整理,还可以做page间的碎片整理(optimize table),缺点是定位记录需在BTree中检索,然后在page内通过directory进行折半查找,定位效率低;
- Oracle的page组织方式上,记录之间没有强的依赖关系,插入操作可以并发执行,并发间竞争小。MySQL是索引组织的,插入操作竞争page的概率大,且对于每个插入操作而言,需要在directory中进行这边查找,且有可能发生directory目录重组,单次插入操作的平均成本也相对较高;
在extent层面,Oracle通过变长extent应对多样化的表大小,MySQL则通过frag extent来达到类似的效果。不过extent对block的管理上,Oracle做得更加精细,也更加准确。采用4个bit描述1个block,区分<25% free、25-50% free、50-75% free、>75% free。MySQL只使用了1个bit(虽然预留了2个bit),只能描述1个page满还是空。当然MySQL还有1个change buffer机制,为了获得好的缓存效果,也统计了page的空间情况,但也只区分了0 free、512 free、1024 free、2048 free,完全针对change buffer机制定制,在两处对page进行了各自的统计,并没有拉通设计。
在segment层面,Oracle采用三级位图进行管理,实际上L1 BMB已经达到block级,和extent对block的管理是拉通的。MySQL则通过3个双向链表FSEG_FREE、FSEG_NOT_FULL、FSEG_FULL和1个FSEG_FRAG_ADDR位图进行管理。实际上,Oracle刚开始也采用的链表方式管理,然后演进到位图方式。链表管理方式需要从链表头开始进行遍历,高并发下竞争非常明显,影响并发效率。当然MySQL在并发插入时瓶颈在索引组织表上,此处的瓶颈还没有显现出来。
在segment的使用上,两者都区分undo segment、temporary segment。Oracle将大字段(BLOB)放在独立的segment中,表数据和索引逻辑独立,所以也分别放在各自的segment中。MySQL是索引组织表,并将索引的叶子节点和非叶子节点分别放在2个不同的segement中。
在tablesapce层面,都区分permanent table、temporary tablespace、undo tablespace,两者没有太大的本质区别。
相关文章
- day1python基础
- mongodb Java(八)
- invalid comparison: java.util.Date and java.lang.String
- java 使用 mysql-binlog-connector-java 同步Mysql数据
- ElasticSearch python基本操作
- 聊天机器人 java_java实现自动回复聊天机器人
- python mysql 游标使用
- java http请求快速_Java http请求快速入门
- 2019年java中高级java面试题(三)mysql
- Java开发面试题目,java开发技术经理招聘
- Python pandas快速入门
- Python mysql 数据库操作
- 该如何从 Java 8 升级到 Java 10
- java hincrby_使用Redis构建文章投票网站(Java)
- Java自学资料!java程序内存溢出找原因
- [Python] Python3 - 对内存的使用--深拷贝,浅拷贝
- python3mysql.connector_Python3使用mysql.connector操作mysql数据库
- 用R收集和映射推特数据的初学者向导
- 如何使用Nginx在AWS上部署React?
- 实现资源库还没找到称手的家伙