
详解Oracle数据库的三大索引类型
2023-03-14 22:22:18 时间
今天主要介绍Oracle数据库的三大索引类型,仅供参考。
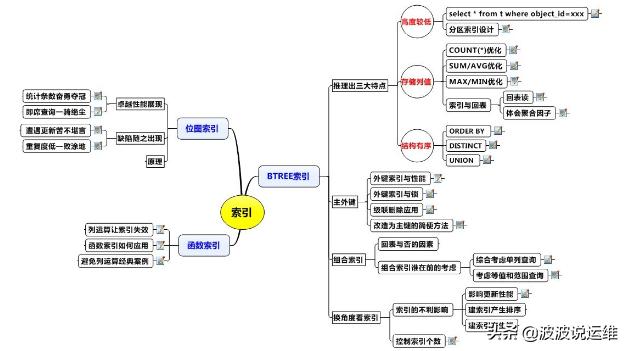
一、B-Tree索引
三大特点:高度较低、存储列值、结构有序
1. 利用索引特性进行优化
- 外键上建立索引:不但可以提升查询效率,而且可以有效避免锁的竞争(外键所在表delete记录未提交,主键所在表会被锁住)。
- 统计类查询SQL:count(), avg(), sum(), max(), min()
- 排序操作:order by字段建立索引
- 去重操作:distinct
- UNION/UNION ALL:union all不需要去重,不需要排序
2. 联合索引
应用场景一:SQL查询列很少,建立查询列的联合索引可以有效消除回表,但一般超过3个字段的联合索引都是不合适的.
应用场景二:在字段A返回记录多,在字段B返回记录多,在字段A,B同时查询返回记录少,比如执行下面的查询,结果c1,c2都很多,c3却很少。
- select count(1) c1 from t where A = 1;
- select count(1) c2 from t where B = 2;
- select count(1) c3 from t where A = 1 and B = 2;
联合索引的列谁在前?
普遍流行的观点:重复记录少的字段放在前面,重复记录多的放在后面,其实这样的结论并不准确。
- drop table t purge;
- create table t as select * from dba_objects;
- create index idx1_object_id on t(object_id,object_type);
- create index idx2_object_id on t(object_type,object_id);
等值查询:
- select * from t where object_id = 20 and object_type = 'TABLE';
- select /*+ index(t,idx1_object_id) */ * from t where object_id = 20 and object_type = 'TABLE';
- select /*+ index(t,idx2_object_id) */ * from t where object_id = 20 and object_type = 'TABLE';
结论:等值查询情况下,组合索引的列无论哪一列在前,性能都一样。
范围查询:
- select * from t where object_id >=20 and object_id < 2000 and object_type = 'TABLE';
- select /*+ index(t,idx1_object_id) */ * from t where object_id >=20 and object_id < 2000 and object_type = 'TABLE';
- select /*+ index(t,idx2_object_id) */ * from t where object_id >=20 and object_id < 2000 and object_type = 'TABLE';
结论:组合索引的列,等值查询列在前,范围查询列在后。 但如果在实际生产环境要确定组合索引列谁在前,要综合考虑所有常用SQL使用索引情况,因为索引过多会影响入库性能。
3. 索引的危害
表上有过多索引主要会严重影响插入性能;
- 对delete操作,删除少量数据索引可以有效快速定位,提升删除效率,但是如果删除大量数据就会有负面影响;
- 对update操作类似delete,而且如果更新的是非索引列则无影响。
4. 索引的监控
- --监控
- alter index [index_name] monitoring usage;
- select * from v$object_usage;
- --取消监控:
- alter index [index_name] nomonitoring usage;
根据对索引监控的结果,对长时间未使用的索引可以考虑将其删除。
5. 索引的常见执行计划
- INDEX FULL SCAN:索引的全扫描,单块读,有序
- INDEX RANGE SCAN:索引的范围扫描
- INDEX FAST FULL SCAN:索引的快速全扫描,多块读,无序
- INDEX FULL SCAN(MIN/MAX):针对MAX(),MIN()函数的查询
- INDEX SKIP SCAN:查询条件没有用到组合索引的第一列,而组合索引的第一列重复度较高时,可能用到
二、位图索引
应用场景:表的更新操作极少,重复度很高的列。
优势:count(*) 效率高
- create table t(
- name_id,
- gender not null,
- location not null,
- age_range not null,
- data
- )as select
- rownum,
- decode(floor(dbms_random.value(0,2)),0,'M',1,'F') gender,
- ceil(dbms_random.value(0,50)) location,
- decode(floor(dbms_random.value(0,4)),0,'child',1,'young',2,'middle',3,'old') age_range,
- rpad('*',20,'*') data
- from dual connect by rownum <= 100000;
- create index idx_t on t(gender,location,age_range);
- create bitmap index gender_idx on t(gender);
- create bitmap index location_idx on t(location);
- create bitmap index age_range_idx on t(age_range);
- select * from t where gender = 'M' and location in (1,10,30) and age_range = 'child';
- select /*+ index(t,idx_t) */* from t where gender = 'M' and location in (1,10,30) and age_range = 'child';
三、函数索引
应用场景:不得不对某一列进行函数运算的场景。
利用函数索引的效率要低于利用普通索引的。
oracle中创建函数索引即是 你用到了什么函数就建什么函数索引,比如substr
- select * from table where 11=1 and substr(field,0,2) in ('01')
创建索引的语句就是
- create index indexname on table(substr(fileld,0,2)) online nologging ;
相关文章
- 仿IOS 带字母索引的滑轮控件
- 音视频开发之音频基础知识!
- 自定义FlowLayout,android flowLayout实现
- Ffmpeg编码实战!
- 空间转录组2022||空间数据反卷积RCTD分析:full mode on Visium hippocampus
- scMethBank:单细胞全基因组 DNA 甲基化图谱在线数据库
- android Fragment单页面加载,避免重复加载(懒加载)分析
- MySQL使用多因素身份认证
- MySQL全面的在线文档
- MySQL安装、升级篇——RPM
- C语言联合体(共用体)使用方法及大小计算
- 数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化|附代码数据
- R语言广义线性模型(GLM)、全子集回归模型选择、检验分析全国风向气候数据|附代码数据
- GIS空间数据模型: 注记文本模型
- 地理空间索引实现:z 曲线、希尔伯特曲线、四叉树, 最邻近几何特征查询、范围查询
- flask + pyecharts 搭建新冠肺炎疫情数据可视化交互分析平台:包含疫情数据获取、态势感知、预测分析、舆情监测等任务
- ArcEngine + DevPress GIS二次开发:湖北疫情交互式数据分析、地图输出、专题可视化系统 具体实现
- 编译过程中的并行性优化(二):基本块与全局代码调度算法
- 地理空间数据库复习笔记:概论、关系模型与关系代数
- (本地无法连接MySQL服务器)ERROR 2003 (HY000): Can‘t connect to MySQL server on ‘localhost‘ (10061)