
爬虫(8) - 可视化爬虫框架Selenium
2023-02-18 15:49:50 时间
基本使用
selenium在爬虫中的应用
- 获取动态网页中的数据,一些动态的数据我们在获取的源码中并没有显示的之一类动态加载数据
- 可用于模拟登录
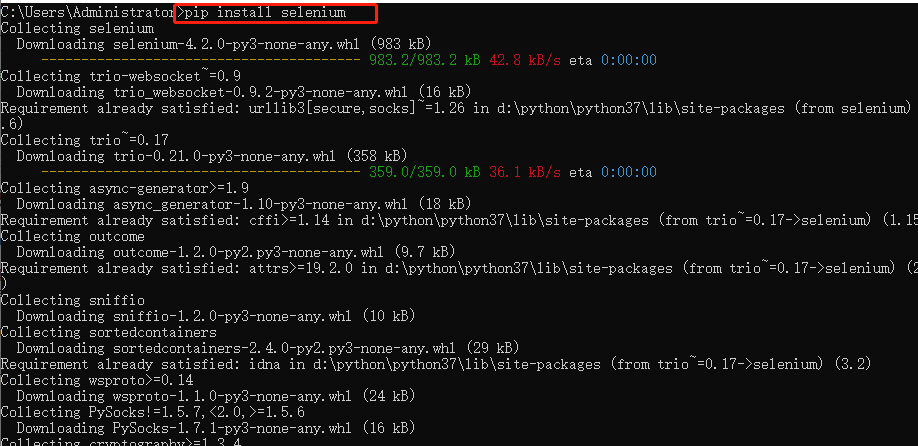
安装selenium
pip install selenium
下载浏览器驱动
Chrome浏览器
下载地址:http://chromedriver.storage.googleapis.com/index.html
注意:webdriver的版本与浏览器版本有者对应关系
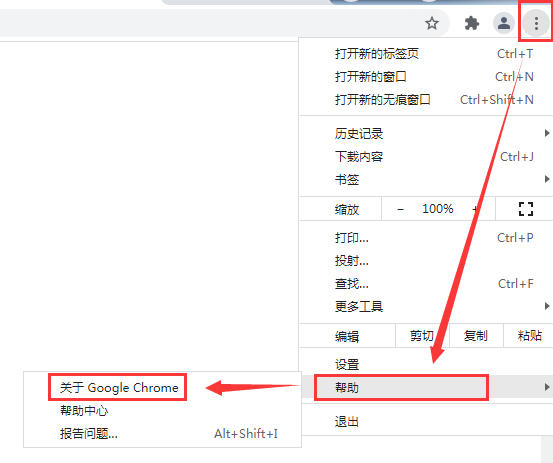
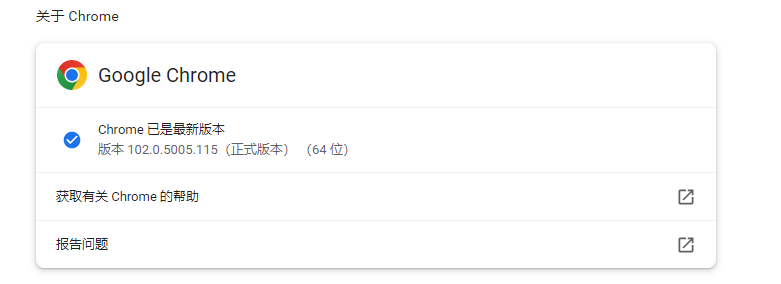
1)首先,查看当前浏览器的版本,方法如下图所示
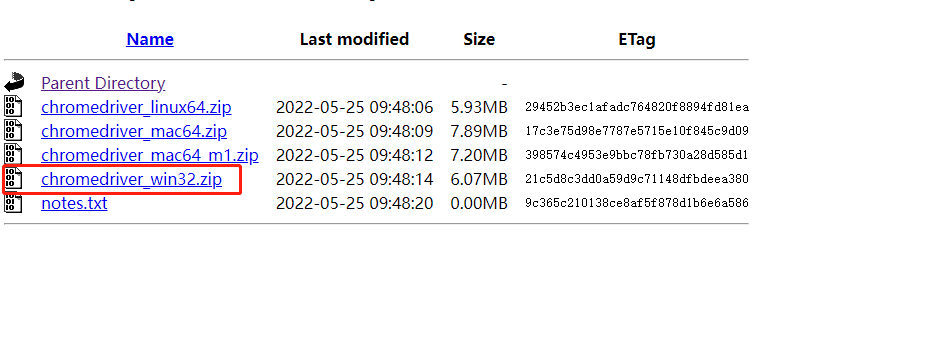
2)然后,下载支持102版本的webdriver,以Windows系统为例,如下图所示

点击进入102.0.5005.61
3) 将下载的文件解压缩,放到文件夹中
调用浏览器访问动态网页数据
直接参开,这个比较细,基础的东西,此处不赘诉https://zhuanlan.zhihu.com/p/470278623
相关文章
- 从 Redis 表项看 SONiC 架构
- Velero 是怎样对 Kubernetes 资源实现备份还原的?
- Redis实现朋友圈,微博等Feed流功能,实现Feed流微服务(业务场景、实现思路和环境搭建)
- 马上都2023了,但是CNS级别单细胞文章仍然是使用monocle2
- 使用Mosquitto实现MQTT客服端C语言
- mosquitto移植到ARM
- mosquitto的安装与使用
- QT下载与安装
- 虚拟基站(VRS)
- liunx驱动之字符设备的注册
- 湃兔更新镜像文件的制作与烧写
- 通过busybox制作根文件系统详细过程
- 内核与设备树的编译和烧写
- UBoot的编译与烧写
- Nextcloud 使用教程
- uboot通过NFS挂载ubuntu根文件系统
- 如何在博客园编写博文章
- [NetWork] 数据封装与解封装流程
- 深度学习-LeNet(第一个卷积神经网络)
- Java跨域-Redirect的跨域问题解决