
美团二面:如何解决 Bin Log 与 Redo Log 的一致性问题

刚看见这个题目的时候还是有点懵逼的,后来才反应过来其实问的就是 redo log 的两阶段提交
老规矩,背诵版在文末。点击阅读原文可以直达我收录整理的各大厂面试真题
为什么说 redo log 具有崩溃恢复的能力
前面我们说过,MySQL Server 层拥有的 bin log 只能用于归档,不足以实现崩溃恢复(crash-safe),需要借助 InnoDB 引擎的 redo log 才能拥有崩溃恢复的能力。所谓崩溃恢复就是:即使在数据库宕机的情况下,也不会出现操作一半的情况
至于为什么说 redo log 具有崩溃恢复的能力,而 bin log 没有,我们先来简单看一下这两种日志有哪些不同点:
1)适用对象不同:
bin log 是 MySQL 的 Server 层实现的,所有引擎都可以使用
而 redo log 是 InnoDB 引擎特有的
2)写入内容不同:
bin log 是逻辑日志,记录的是这个语句的原始逻辑,比如 “给 id = 1 这一行的 age 字段加 1”
redo log 是物理日志,记录的是 “在某个数据页上做了什么修改”
3)写入方式不同:
bin log 是可以追加写入的。“追加写” 是指 bin log 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
redo log 是循环写的,空间固定会被用完
可以看到,redo log 和 bin log 的一个很大的区别就是,一个是循环写,一个是追加写。也就是说 redo log 只会记录未刷入磁盘的日志,已经刷入磁盘的数据都会从 redo log 这个有限大小的日志文件里删除。
而 bin log 是追加日志,保存的是全量的日志。这就会导致一个问题,那就是没有标志能让 InnoDB 从 bin log 中判断哪些数据已经刷入磁盘了,哪些数据还没有。
举个例子,bin log 记录了两条日志:
- 记录 1:给 id = 1 这一行的 age 字段加 1
- 记录 2:给 id = 1 这一行的 age 字段加 1
假设在记录 1 刷盘后,记录 2 未刷盘时,数据库崩溃。重启后,只通过 bin log 数据库是无法判断这两条记录哪条已经写入磁盘,哪条没有写入磁盘,不管是两条都恢复至内存,还是都不恢复,对 id = 1 这行数据来说,都是不对的。
但 redo log 不一样,只要刷入磁盘的数据,都会从 redo log 中被抹掉,数据库重启后,直接把 redo log 中的数据都恢复至内存就可以了。
这就是为什么说 redo log 具有崩溃恢复的能力,而 bin log 不具备。
redo log 两阶段提交
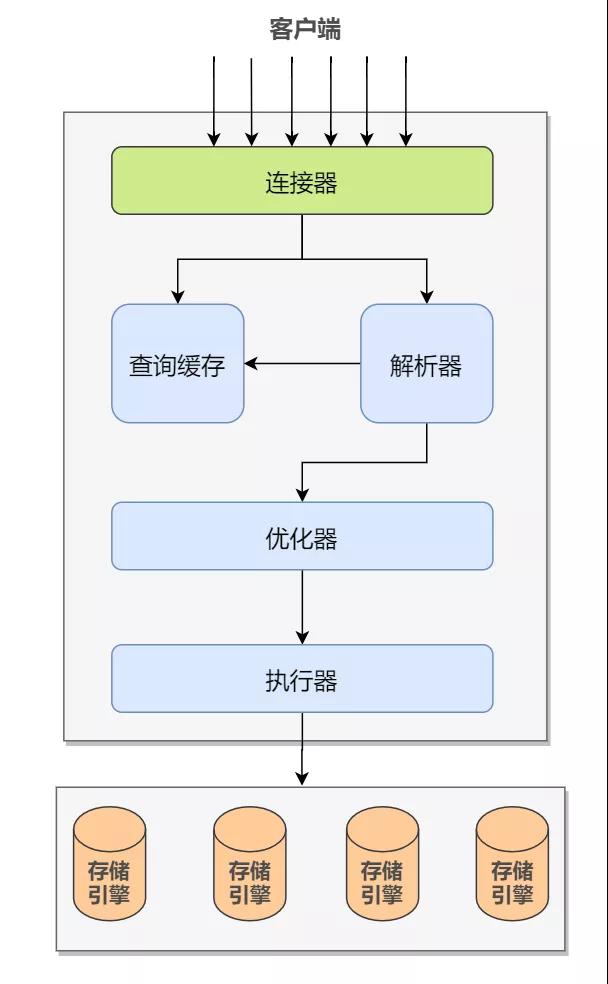
前面我们介绍过一条 SQL 查询语句的执行过程,简单回顾:
MySQL 客户端与服务器间建立连接,客户端发送一条查询给服务器;
服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果;否则进入下一阶段;
服务器端进行 SQL 解析、预处理,生成合法的解析树;
再由优化器生成对应的执行计划;
执行器根据优化器生成的执行计划,调用相应的存储引擎的 API 来执行,并将执行结果返回给客户端
对于更新语句来说,这套流程同样也是要走一遍的,不同的是,更新流程还涉及两个重要的日志模块 bin log 和 redo log。
以下面这条简单的 SQL 语句为例,我们来解释下执行器和 InnoDB 存储引擎在更新时做了哪些事情:
- update table set age = age + 1 where id = 1;
执行器:找存储引擎取到 id = 1 这一行记录
存储引擎:根据主键索引树找到这一行,如果 id = 1 这一行所在的数据页本来就在内存池(Buffer Pool)中,就直接返回给执行器;否则,需要先从磁盘读入内存池,然后再返回
执行器:拿到存储引擎返回的行记录,把 age 字段加上 1,得到一行新的记录,然后再调用存储引擎的接口写入这行新记录
存储引擎:将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务
注意不要把这里的提交事务和我们 sql 语句中的提交事务 commit 命令搞混了哈,我们这里说的提交事务,指的是事务提交过程中的一个小步骤,也是最后一步。当这个步骤执行完成后,commit 命令就执行成功了。
执行器:生成这个操作的 bin log,并把 bin log 写入磁盘
执行器:调用存储引擎的提交事务接口
存储引擎:把刚刚写入的 redo log 状态改成提交(commit)状态,更新完成
如下图所示:
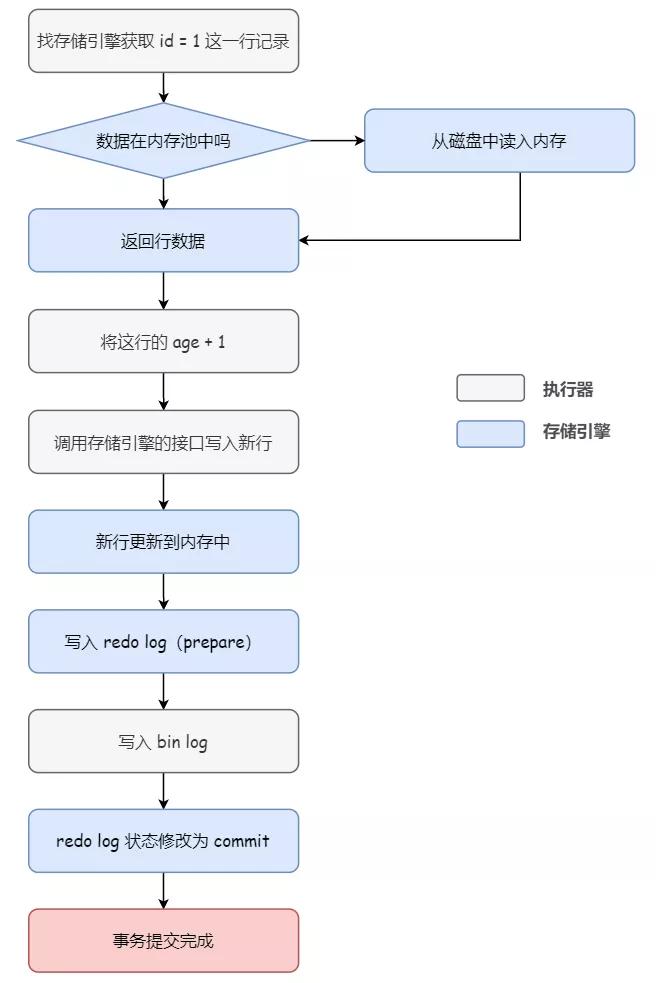
可以看到,所谓两阶段提交,其实就是把 redo log 的写入拆分成了两个步骤:prepare 和 commit。
所以,为什么要这样设计呢?这样设计怎么就能够实现崩溃恢复呢?
根据两阶段提交,崩溃恢复时的判断规则是这样的:
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交
如果 redo log 里面的事务处于 prepare 状态,则判断对应的事务 binlog 是否存在并完整
- a. 如果 binlog 存在并完整,则提交事务;
- b. 否则,回滚事务。
当然,这样说小伙伴们肯定没法理解,下面来看几个实际的例子:
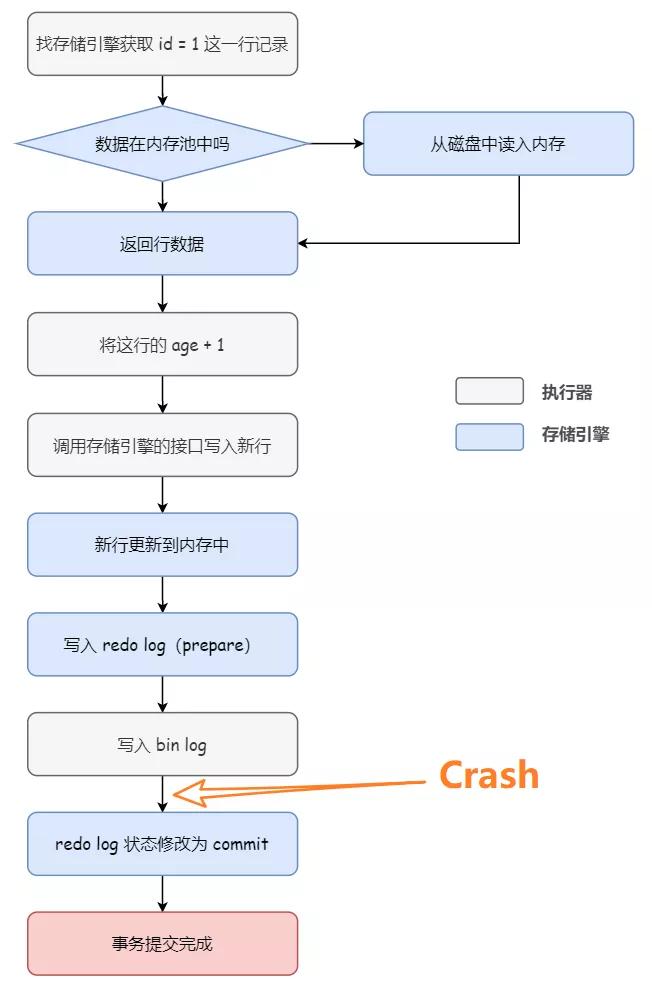
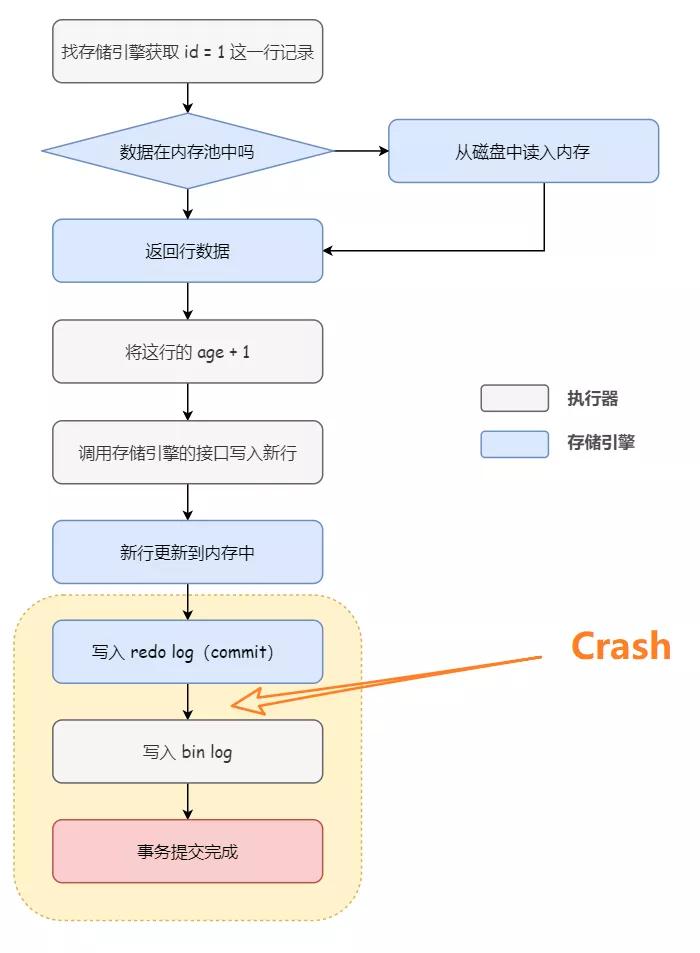
如下图所示,假设数据库在写入 redo log(prepare) 阶段之后、写入 binlog 之前,发生了崩溃,此时 redo log 里面的事务处于 prepare 状态,binlog 还没写(对应 2b),所以崩溃的时候,这个事务会回滚。
Why?
因为 binlog 还没有写入,之后从库进行同步的时候,无法执行这个操作,但是实际上主库已经完成了这个操作,所以为了主备一致,在主库上需要回滚这个事务
并且,由于 binlog 还没写,所以也就不会传到备库,从而避免主备不一致的情况。
而如果数据库在写入 binlog 之后,redo log 状态修改为 commit 前发生崩溃,此时 redo log 里面的事务仍然是 prepare 状态,binlog 存在并完整(对应 2a),所以即使在这个时刻数据库崩溃了,事务仍然会被正常提交。
Why?
因为 binlog 已经写入成功了,这样之后就会被从库同步过去,但是实际上主库并没有完成这个操作,所以为了主备一致,在主库上需要提交这个事务。
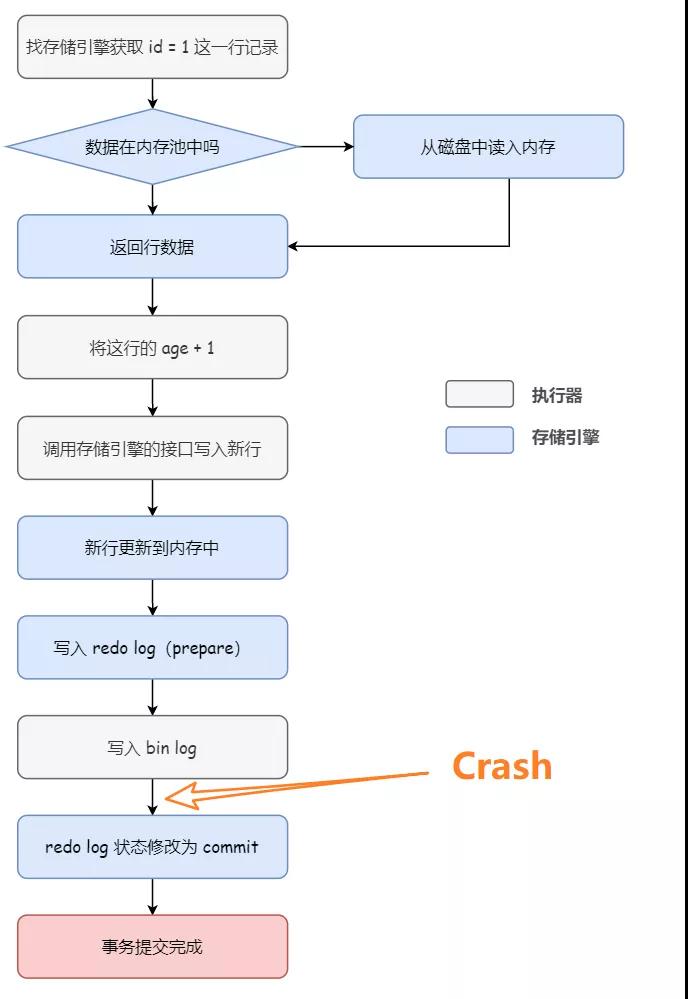
所以,其实可以看出来,处于 prepare 阶段的 redo log 加上完整的 bin log,就能保证数据库的崩溃恢复了。
可能有同学就会问了,MySQL 咋知道 bin log 是不是完整的?
简单来说,一个事务的 binlog 是有完整格式的(这个我们在后面的文章中会详细解释):
- statement 格式的 bin log,最后会有 COMMIT
- row 格式的 bin log,最后会有 XID event
而对于 bin log 可能会在中间出错的情况,MySQL 5.6.2 版本以后引入了 binlog-checksum 参数,用来验证 bin log 内容的正确性。
思考一个问题,两阶段提交是必要的吗?可不可以先 redo log 写完,再写 bin log 或者反过来?
1)对于先写完 redo log 后写 bin log 的情况:
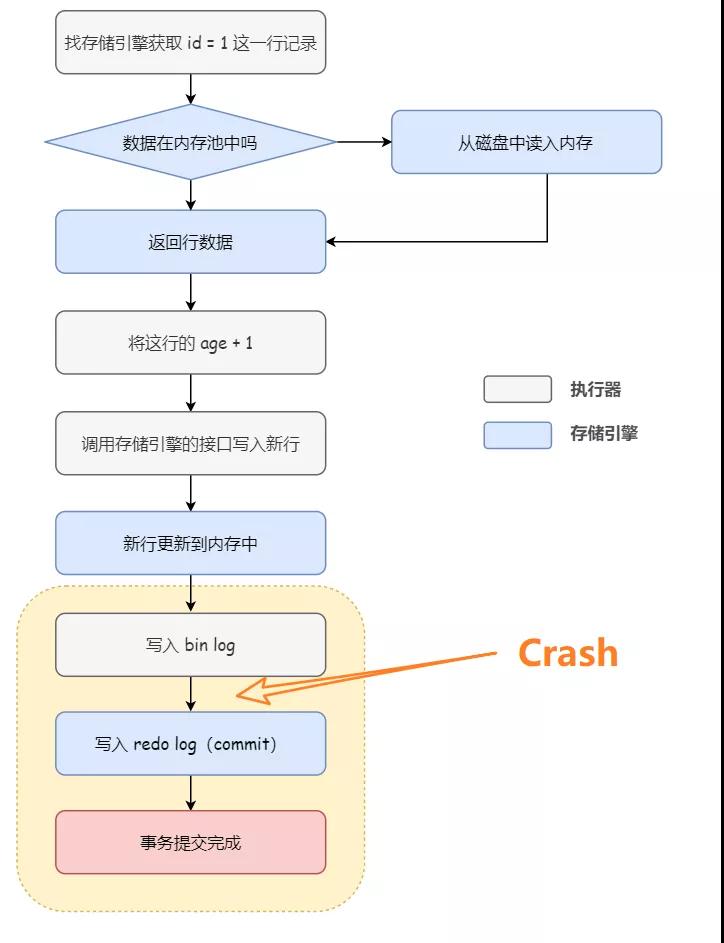
假设在 redo log 写完,bin log 还没有写完的时候,MySQL 崩溃。主库中的数据确实已经被修改了,但是这时候 bin log 里面并没有记录这个语句。因此,从库同步的时候,就会丢失这个更新,和主库不一致。
2)对于先写完 binlog 后写 redo log 的情况:
如果在 bin log 写完,redo log 还没写的时候,MySQL 崩溃。因为 binlog 已经写入成功了,这样之后就会被从库同步过去,但是实际上 redo log 还没写,主库并没有完成这个操作,所以从库相比主库就会多执行一个事务,导致主备不一致
最后放上这道题的背诵版:
面试官:
- 问法 1:如何解决 bin log 与 redo log 的一致性问题?
- 问法 2:一条 SQL 更新语句是如何执行的?
- 问法 3:讲一下 redo log / redo log 两阶段提交原理
小牛肉:
所谓两阶段提交,其实就是把 redo log 的写入拆分成了两个步骤:prepare 和 commit。
首先,存储引擎将执行更新好的新数据存到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务
然后执行器生成这个操作的 bin log,并把 bin log 写入磁盘
最后执行器调用存储引擎的提交事务接口,存储引擎把刚刚写入的 redo log 状态改成提交(commit)状态,更新完成
如果数据库在写入 redo log(prepare) 阶段之后、写入 binlog 之前,发生了崩溃:
此时 redo log 里面的事务处于 prepare 状态,binlog 还没写,之后从库进行同步的时候,无法执行这个操作,但是实际上主库已经完成了这个操作,所以为了主备一致,MySQL 崩溃时会在主库上回滚这个事务
而如果数据库在写入 binlog 之后,redo log 状态修改为 commit 前发生崩溃,此时 redo log 里面的事务仍然是 prepare 状态,binlog 存在并完整,这样之后就会被从库同步过去,但是实际上主库并没有完成这个操作,所以为了主备一致,即使在这个时刻数据库崩溃了,主库上事务仍然会被正常提交。
相关文章
- 图像处理工具Python扩展库,你了解吗?
- 十个常用的损失函数解释以及Python代码实现
- 30 个数据科学工作中必备的 Python 包
- 如何在 Windows 上安装 Python
- 几行 Python 代码就可以提取数百个时间序列特征
- 使用Python快速搭建接口自动化测试脚本实战总结
- 哪种编程语言最适合开发网页抓取工具?
- 不要在 Python 中使用循环,这些方法其实更棒!
- 震惊!用Python探索《红楼梦》的人物关系!
- 如何最简单、通俗地理解Python模块?
- 酷炫,Python实现交通数据可视化!
- 为什么急于寻找Python的替代者?
- 30 个数据工程必备的Python 包
- 去字节面试被面这题能答上来吗?谈谈你对时间轮的理解?
- 火山引擎在行为分析场景下的 ClickHouse JOIN 优化
- 用Python爬取了某宝1166家月饼数据进行可视化分析,终于找到最好吃的月饼~
- 在 Linux 上试试这个基于 Python 的文件管理器
- Python列表解析式到底该怎么用?
- 如何快速把你的 Python 代码变为 API
- 十个Python初学者常犯的错误