
关于MVCC,我之前写错了,这次我改好了!

简单理解版
以下先引用我之前写过的那篇中的内容,可以快速理解,建议先简单看看。
要说幻读,首先要了解MVCC,MVCC叫做多版本并发控制,实际上就是保存了数据在某个时间节点的快照。
我们每行数据实际上隐藏了两列,创建时间版本号,过期(删除)时间版本号,每开始一个新的事务,版本号都会自动递增。
还是拿上面的user表举例子,假设我们插入两条数据,他们实际上应该长这样。

这时候假设小明去执行查询,此时current_version=3
- select * from user where id<=3;
同时,小红在这时候开启事务去修改id=1的记录,current_version=4
- update user set name='张三三' where id=1;
执行成功后的结果是这样的

如果这时候还有小黑在删除id=2的数据,current_version=5,执行后结果是这样的。

由于MVCC的原理是查找创建版本小于或等于当前事务版本,删除版本为空或者大于当前事务版本,小明的真实的查询应该是这样
- select * from user where id<=3 and create_version<=3 and (delete_version>3 or delete_version is null);
所以小明最后查询到的id=1的名字还是'张三',并且id=2的记录也能查询到。这样做是为了保证事务读取的数据是在事务开始前就已经存在的,要么是事务自己插入或者修改的。
真正原理
事实上,上述的说法只是简化版的理解,真正的MVCC用于读已提交和可重复读级别的控制,主要通过undo log日志版本链和read view来实现。
每条数据隐藏的两个字段也并不是创建时间版本号和过期(删除)时间版本号,而是roll_pointer和trx_id。
roll_pointer指向更新事务之前生成的undo log,undo log用于事务的回滚,保证事务的原子性。
trx_id就是最近一次更新数据的事务ID。
以上述例子来举例,最初插入两条数据,真实的情况是这样,因为第一次插入数据没有undo log,所以roll_pointer指向一个空的undo log。
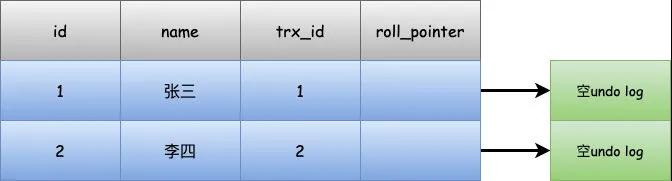
这时候假设小明去执行查询,就会开启一个read view,read view包含几个重要的东西。
- m_ids,就是还未提交的事务id集合
- low_limit_id,m_ids里最小的值
- up_limit_id,m_ids里的最大值
- creator_trx_id,创建read view的事务ID,也就是自己的事务ID
小明来执行查询了,当前事务ID=3
- select * from user where id<=3;
小红在这时候开启事务去修改id=1的记录,事务ID=4
- update user set name='张三三' where id=1;
这时候小明的read view是这样。
- m_ids=[3,4]
- low_limit_id=3
- up_limit_id=5
- creator_trx_id=3
所以,小明在执行查询的时候,会去判断当前这条数据的trx_id
这时候,小红的修改也完成了,小红数据于是就变成了这样。

如果小明再次去查询的话,就会发现现在的trx_id>read view的low_limit_id,也就是4>3,不符合条件,同时发现现在的trx_id=4在low_limit_id和up_limit_id [3,5]之间,并且trx_id=4在m_ids=[3,4]之中,所以就会根据roll_pointer指向的undo log去查找,trx_id=1小于现在的low_limit_id=3,符合条件,就找到了上一个版本name=张三的记录。
如果这时候小明自己去修改这条记录的值,把名字改成张五,结果就是这样。
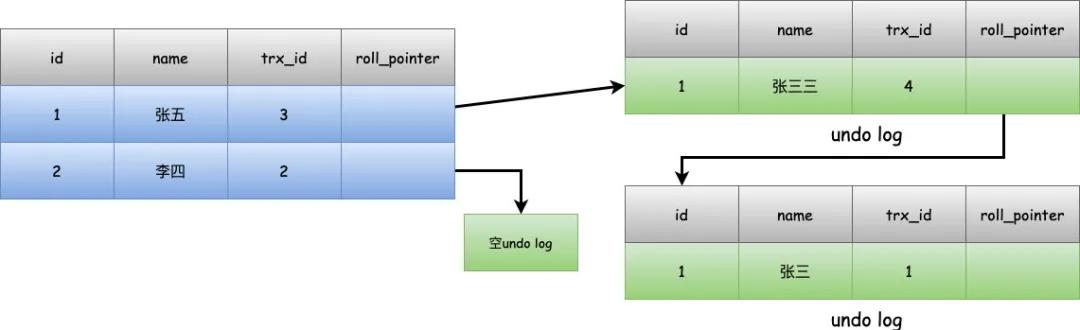
然后小明去查询的话,就会发现当前的trx_id=3就是自己的creator_trx_id,就是自己,那么就直接返回这条数据。
所以,我们可以先总结下几种情况:
- 如果trx_id次开启事务查询的场景<>
- 如果trx_id>low_limit,trx_id还在[low_limit_id,up_limit_id]范围之内,并且trx_id在m_ids中,就会根据roll_pointer去查找undo log日志链,找到之前版本的数据,对应的就是小红修改后小明再次查询的场景
- 如果trx_id=creator_trx_id,那么说明就是自己修改的,直接返回就好了,对应的就是小明自己去修改数据的场景
不同隔离级别的实现
根据上面阐述的原理,你可能发现了,这是可重复读下的实现啊,保证每次读取到的数据都是一致的。
那么,如果是读已提交级别下,这个是怎么实现的?
其实很简单,在上面的原理解释中,我都是假设每次查询的时候生成了read view,后续并没有重新生成。
而读已提交级别下,则是每次查询都会生成一次read view。
以上述小红修改过张三后的场景来举例。
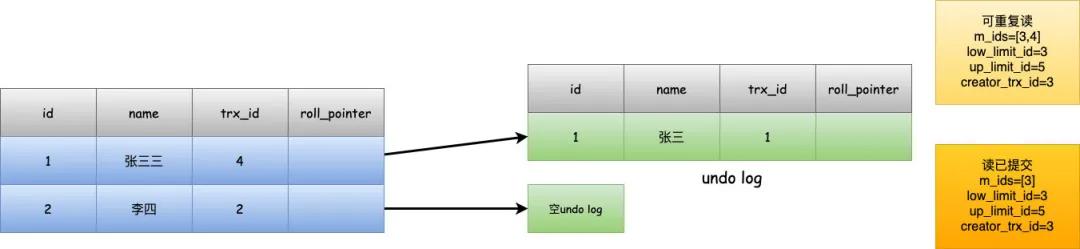
在可重复度级别下,由于trx_id>low_limit,trx_id还在[low_limit_id,up_limit_id]范围之内,并且trx_id在m_ids中,满足我们上述的条件2,所以就会根据roll_pointer找到之前的版本记录,保证可重复读。
而在读已提交的级别下,重新生成了read view,这时候trx_id不在m_ids之中,说明事务已经提交,所以可以直接返回这条数据,所以查到的数据就是小红修改后的name=张三三的数据了。
本文转载自微信公众号「艾小仙」,可以通过以下二维码关注。转载本文请联系艾小仙公众号。

相关文章
- 数据科学中的“数据智慧”
- 大数据,勾绘智慧城市新蓝图
- 吴甘沙:大数据的六大人工智能变现方式
- 这些大酒店用大数据和分析技术对我们做了什么?
- 车品觉:对于大数据未来趋势的判断
- 我们原来生活在“数字阴影”和“平行宇宙”中
- 2016年大数据在金融领域的10大趋势
- 3个可视化案例:不只酷炫,洞察最重要
- 澳大利亚疯狂计划:把现实世界数字化
- 如何解决实施大数据的常见障碍
- [案例]信息巨头Carfax如何打造数据产品
- 大数据下客户金融产品购买概率预测
- 有了800件T恤测量数据,能选出最合身的尺寸吗?
- 大数据分析的光荣与陷阱——从谷歌流感趋势谈起
- 阿里副总裁车品觉:无数据不成活
- IBM提出五大能力驱动认知商业变革
- 网络社交媒体的情感认知与计算
- Google用大数据画出救命地图,力抗寨卡病毒
- 【慢性病管理】: 大数据、电子病历、物联网三合一
- 关于危险驾驶的大数据:且看保险公司如何跟踪你!