
标准爬虫初探,来自Python之父的大餐!
首先不得不承认自己做了标题党,本文实质是分析500lines or less的crawl工程,这个工程的地址是https://github.com/aosabook/500lines,有兴趣的同学可以看看,是一个非常高质量的开源工程集合,据说要写一本书,不过看着代码提交记录,这本书面世时间应该不会很快。这篇文章写得很渣,错误一定要提啊。。。
网络爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。简单的可以将网络爬虫理解为一个带有终止条件的while循环,在条件不触发的情况下,爬虫就不断的从每个以及获取的url发送请求获取页面数据,然后解析当前页面的url,不断迭代下去。在crawl工程当中,完成这一过程的是crawler类,他并未采用广度优先或是深度优先的爬虫,在当前请求失败的时候就通过python挂起当前任务,然后在之后再进行调度,这可以勉强理解为基于网络连通性的A*搜索,其运行方式如下所示:
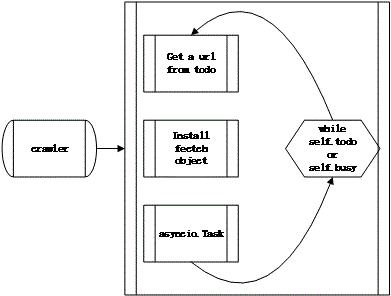
对一个初始化后的crawler对象,其中存在一个url,一个todo集合,存储尚未继续呢爬虫操作的url;一个busy集合,保存等待其他爬虫数据的url集合;一个done集合,保存完成页面爬取的url集合。爬虫的核心就是这个死循环,首先爬虫从todo集合当中获取一个url,然后初始化fetch对象用于获取页面上的url,***进行任务调度执行一个url请求任务。这段流程的代码如下所示。
- @asyncio.coroutine
- def crawl(self):
- """Run the crawler until all finished."""
- with (yield from self.termination):
- while self.todo or self.busy:
- if self.todo:
- url, max_redirect = self.todo.popitem()
- fetcher = Fetcher(url,
- crawler=self,
- max_redirect=max_redirect,
- max_tries=self.max_tries,
- )
- self.busy[url] = fetcher
- fetcher.task = asyncio.Task(self.fetch(fetcher))
- else:
- yield from self.termination.wait()
- self.t1 = time.time()
一个爬虫很明显不会仅仅由一个死循环构成,在crawl外层需要其他模块支持其操作,包括网络连接,url获取,任务调度等任务,整个crawl工程的调度框架如下所示:
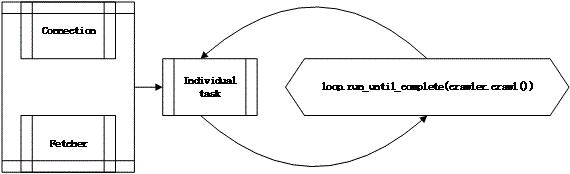
在crawl创建初始化时候首先创建一个ConnectionPool:
- self.pool = ConnectionPool(max_pool, max_tasks)
其中保留属性connections和queue,分别保存连接的集合和队列,用于后续调度;而connection中存储host和端口号并支持ssl,通过asyncio.open_connection()获取连接。
- self.connections = {} # {(host, port, ssl): [Connection, ...], ...}
- self.queue = [] # [Connection, ...]
任务执行时crawl方法首先通过loop.run_until_complete(crawler.crawl())加载到event loop当中,然后用上述语句构建的链接池ConnectionPool中保存connection对象,获取连接对象然后通过fetcher对象的fetch方法进行数据爬取。对于一个url请求任务,使用fetcher进行处理,调度则是用asyncio.Task方法进行的调度。其中fetch方法获取被挂起的generator,交给asyncio.Task执行。
通过yield from和asynico.coroutine语句,将这个方法变为执行过程中的generator,在执行fetcher.fetch()方法时候如果被挂起,则通过调度程序进行处理。
fetcher.fetch()方法是网络爬虫的核心方法,负责从网络上获取页面数据并将其中的url加载到todo集合当中,该方法尝试获取页面数据当尝试次数达到上限时停止操作,获取成功的html数据和外部链接以及重定向链接都将被存储。在url链接次数到达上限的情况下,将停止这个url的链接操作,输出出错日志。之后针对页面的不同状态,采取不同的处理方式。
下面的代码是crawling.py文件从333行开始(crawling.py)到对应方法结束的区域,通过对页面status的判断选择不同的处理方式。其中通过正则表达式,获取页面上的url信息,这里选择为href开头的字符串,核心url提取的代码在下面:
- # Replace href with (?:href|src) to follow image links.
- self.urls = set(re.findall(r'(?i)href=["\']?([^\s"\'<>]+)',body))
- if self.urls:
- logger.warn('got %r distinct urls from %r',len(self.urls), self.url)
- self.new_urls = set()
- for url in self.urls:
- url = unescape(url)
- url = urllib.parse.urljoin(self.url, url)
- url, frag = urllib.parse.urldefrag(url)
- if self.crawler.add_url(url):
- self.new_urls.add(url)
通过代码,很明显就可以看出正则匹配结果存储在urls集合当中并通过for循环依次进行处理,加入到当前fetcher的crawler对象的todo集合当中。
在之前分析的基础上对主文件crawl.py进行进一步分析,可以得到整体爬虫的架构:
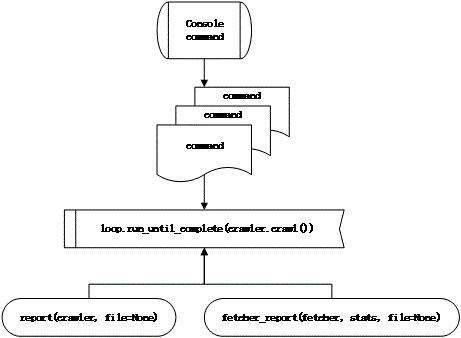
在主文件当中首先通过argparse.ArgumentParser进行解析,设置控制台的数据读取和控制,其中选择了IOCP作为windows环境下的event loop对象。主方法,首先通过parse_args返回存储命令行数据的字典,如果没有root属性,则给出提示。然后配置日志级别,指示日志的输出级别,低于***级别的不输出。
通过入口函数main方法进入程序的时候,首先根据来自命令行参数对Crawler进行初始化,同时获取使用asyncio的loop event对象,执行run_until_complete方法,会一直执行到这个程序结束运行。
除此之外reporting.py用于打印当前任务执行情况。其中fetcher_report(fetcher, stats, file=None)打印这个url的工作状态,url就是fetcher的url属性;report(crawler, file=None)打印整个工程所有完成的url工作状态。
至此,crawl的基本框架就展现在眼前了。至于在这个程序中出现的一些不容易理解的python语言特性,某些应用到的核心模块,将在下一篇博客《标准爬虫分析,精简不简单!》中进行阐述。
相关文章
- 图像处理工具Python扩展库,你了解吗?
- 十个常用的损失函数解释以及Python代码实现
- 30 个数据科学工作中必备的 Python 包
- 如何在 Windows 上安装 Python
- 几行 Python 代码就可以提取数百个时间序列特征
- 使用Python快速搭建接口自动化测试脚本实战总结
- 哪种编程语言最适合开发网页抓取工具?
- 不要在 Python 中使用循环,这些方法其实更棒!
- 震惊!用Python探索《红楼梦》的人物关系!
- 如何最简单、通俗地理解Python模块?
- 酷炫,Python实现交通数据可视化!
- 为什么急于寻找Python的替代者?
- 30 个数据工程必备的Python 包
- 去字节面试被面这题能答上来吗?谈谈你对时间轮的理解?
- 火山引擎在行为分析场景下的 ClickHouse JOIN 优化
- 用Python爬取了某宝1166家月饼数据进行可视化分析,终于找到最好吃的月饼~
- 在 Linux 上试试这个基于 Python 的文件管理器
- Python列表解析式到底该怎么用?
- 如何快速把你的 Python 代码变为 API
- 十个Python初学者常犯的错误