
带你读AI论文丨用于细粒度分类的Transformer结构—TransFG
摘要:本文解读了《TransFG: A Transformer Architecture for Fine-grained Recognition》,该论文针对细粒度分类任务,提出了对应的TransFG。
本文分享自华为云社区《论文解读系列二十:用于细粒度分类的Transformer结构—TransFG》,作者: BigDragon 。

论文地址:https://arxiv.org/abs/2103.07976
GitHub地址:https://github.com/TACJu/TransFG
近来,细粒度分类研究工作主要集中在如何定位差异性图片区域,以此提高网络捕捉微小差异的能力,而大部分工作主要通过使用不同的基模型来提取特定区域的特征,但这种方式会使流程复杂化,并从特定区域提取出大量冗余特征。因此,本文将所有原始注意力权重整合至注意力映射中,以此来指导模型高效地选取差异性图片区域,提出用于细粒度分类的Transformer结构TransFG。
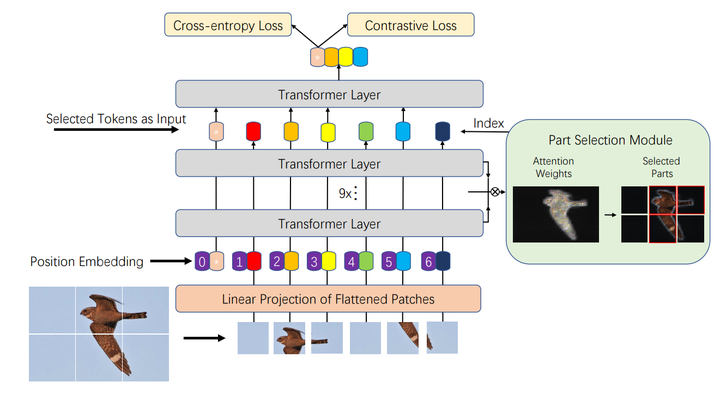
图1 TransFG 结构
1 问题定义
细粒度分类任务主要以定位方法及特征编码方法为主,定位方法主要通过定位差异性局部区域来进行分类,而特征编码方法通过高维信息或寻找差异对之间关系来学习更多信息。TransFG通过整合注意力权重,计算区域的对比损失,来定位差异性局部区域,以此进行细粒度分类。
2 TransFG
2.1 图像序列化
原有Vision Transformer将图片分割为相互不重叠的patch,但这会损害局部相邻结构,可能会导致差异性图像区域被分离。因此,为解决这个问题,本文采用滑动窗口产生重叠patch,所产生的patch数量N根据公式(1)进行计算。其中,H、W分别为图像长宽,P为图像patch尺寸,S为滑动窗口步长。
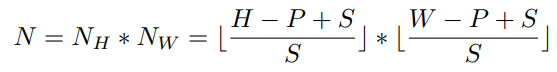
2.2 Patch Embedding 和 Transformer Encoder
TransFG在Patch Embedding 和 Transformer Encoder两个模块遵循了原有ViT的形式,并未进行改动
2.3 局部选取模块(PSM)
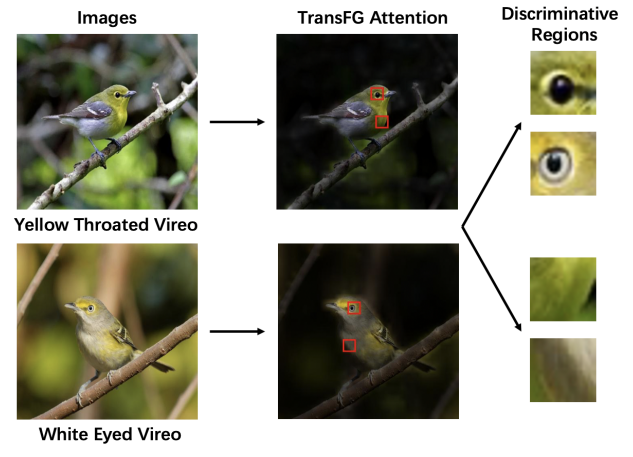
图2 TransFG的注意力映射及所选取的token
首先假设模型中具有K个自注意首部,各层注意力权重如公式(2)所示,其中al指第l层K个首部注意力权重。
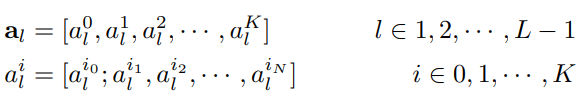
如公式(3)所示,将所有层的注意力权重进行矩阵相乘,afinal 捕捉了图像信息从输入到更深层的整个过程,相对于原有ViT,包含了更多信息,更加有助于选取具有识别性的区域
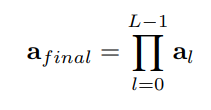
选取afinal中K个不同注意力首部的最大值A1、A2、…、AK,并将其与分类token进行拼接,其结果如公式(4)所示。该步骤不仅保留了全局信息,也让模型更加关注与不同类别之间的微小差异。
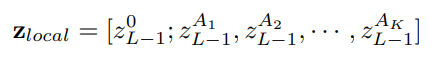
2.4 对比损失
如公式(5)所示,对比损失的目标是最小化不同类别对应的分类tokens的相似度,并最大化相同类别对应的分类tokens的相似度。其中,为减少loss被简单负样本影响,采用α来控制对loss有贡献的负样本对。
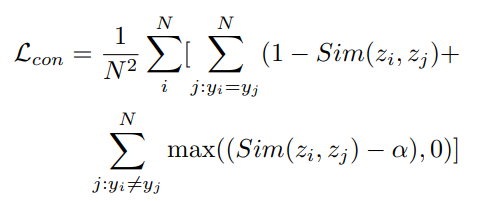
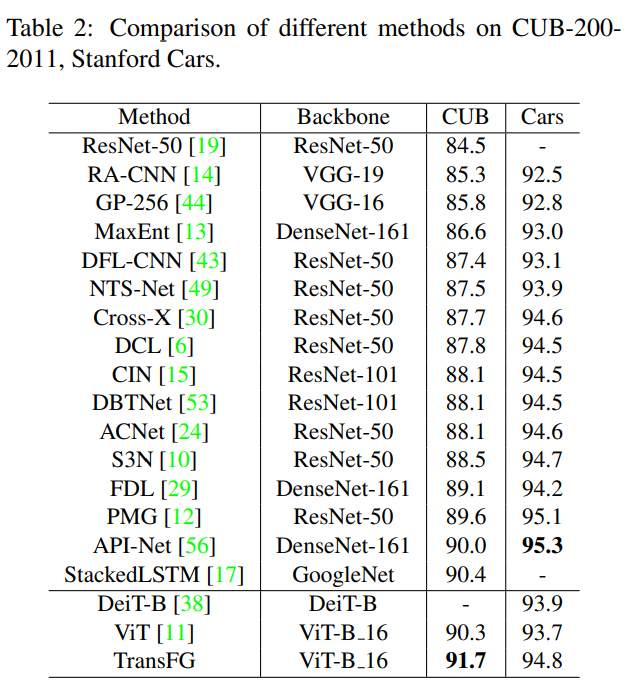
3 实验结果
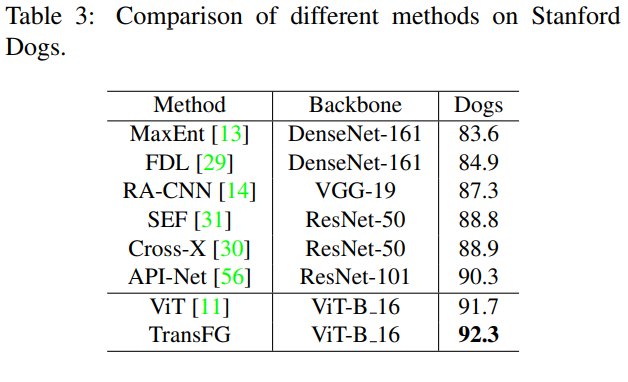
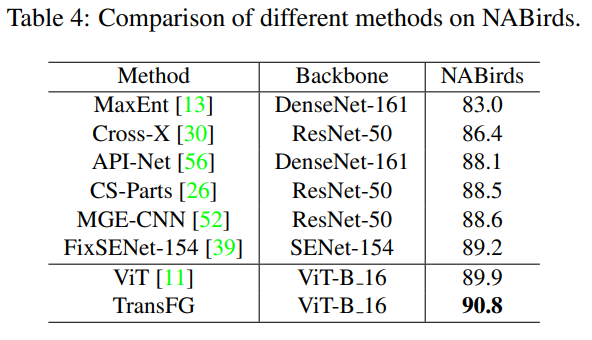
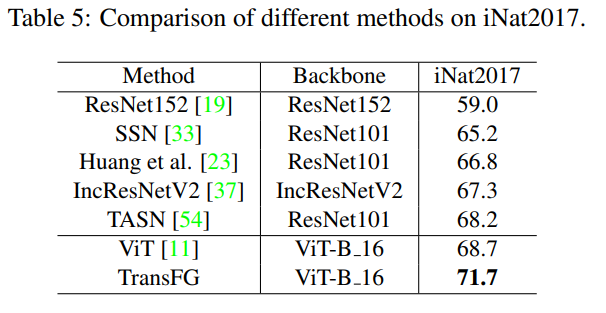
TranFG在CUB-200-2011、Stanford Cars、Stanford Dogs、NABirds及iNat2017五个数据集进行了验证,并在CUB-200-2011、Standford Dogs、NABirds数据集上取得了SOTA结果。
4. 总结
- 在图像序列化部分,相对于采用非重叠的patch分割方法,采用重叠方法的精度提高了0.2%
- PSM整合所有注意力权重,保留全局信息,让模型更加关注于不同类别的微小差别,让模型精度提高了0.7%。
- 采用对比损失函数,能减少不同类别的相似度,提高相同类别的相似度,让模型精度提高了0.4%-0.5%。
参考文献
[1] He, Ju, et al. "TransFG: A Transformer Architecture for Fine-grained Recognition." arXiv preprint arXiv:2103.07976 (2021).
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习