
用Python从零开始构造决策树
起步
本章介绍如何不利用第三方库,仅用python自带的标准库来构造一个决策树。
熵的计算公式:
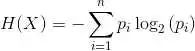
对应的 python 代码:

条件熵的计算
根据计算方法:
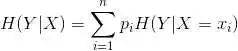
对应的 python 代码:
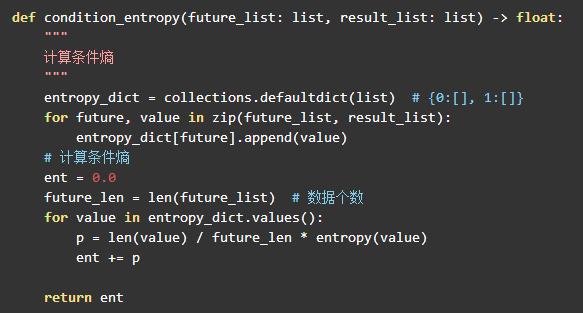
其中参数 future_list 是某一特征向量组成的列表,result_list 是 label 列表。
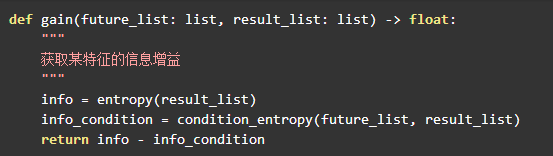
信息增益
根据信息增益的计算方法:
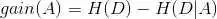
对应的python代码:
 ..
..
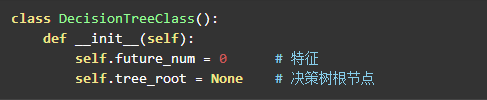
定义决策树的节点
作为树的节点,要有左子树和右子树是必不可少的,除此之外还需要其他信息:
树的节点会有两种状态,叶子节点中 results 属性将保持当前的分类结果。非叶子节点中, col 保存着该节点计算的特征索引,根据这个索引来创建左右子树。
has_calc_index 属性表示在到达此节点时,已经计算过的特征索引。特征索引的数据集上表现是列的形式,如数据集(不包含结果集):
有三条数据,三个特征,那么***个特征对应了***列 [1, 0, 0] ,它的索引是 0 。
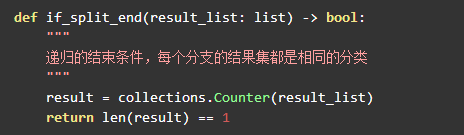
递归的停止条件
本章将构造出完整的决策树,所以递归的停止条件是所有待分析的训练集都属于同一类:
从训练集中筛选***的特征
因此计算节点就是调用 best_index = choose_best_future(node.data_set, node.labels, node.has_calc_index) 来获取***的信息增益的特征索引。
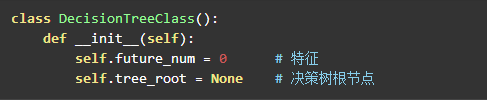
构造决策树
决策树中需要一个属性来指向树的根节点,以及特征数量。不需要保存训练集和结果集,因为这部分信息是保存在树的节点中的。
创建决策树
这里需要递归来创建决策树:
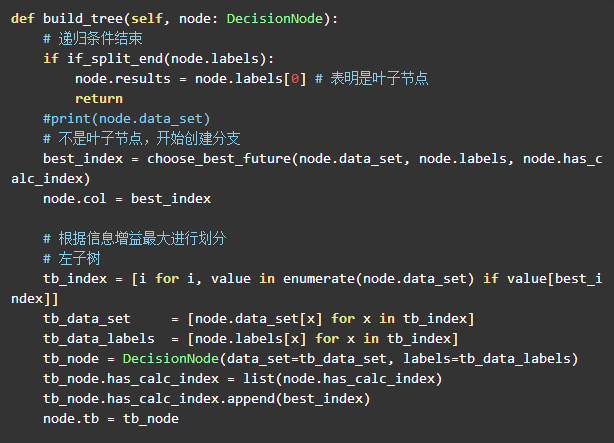

根据信息增益的特征索引将训练集再划分为左右两个子树。
训练函数
也就是要有一个 fit 函数:

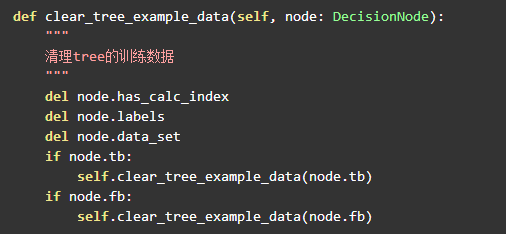
清理训练集
训练后,树节点中数据集和结果集等就没必要的,该模型只要 col 和 result 就可以了:
预测函数
提供一个预测函数:
测试
数据集使用前面《应用篇》中的向量化的训练集:
相关文章
- 图像处理工具Python扩展库,你了解吗?
- 十个常用的损失函数解释以及Python代码实现
- 30 个数据科学工作中必备的 Python 包
- 如何在 Windows 上安装 Python
- 几行 Python 代码就可以提取数百个时间序列特征
- 使用Python快速搭建接口自动化测试脚本实战总结
- 哪种编程语言最适合开发网页抓取工具?
- 不要在 Python 中使用循环,这些方法其实更棒!
- 震惊!用Python探索《红楼梦》的人物关系!
- 如何最简单、通俗地理解Python模块?
- 酷炫,Python实现交通数据可视化!
- 为什么急于寻找Python的替代者?
- 30 个数据工程必备的Python 包
- 去字节面试被面这题能答上来吗?谈谈你对时间轮的理解?
- 火山引擎在行为分析场景下的 ClickHouse JOIN 优化
- 用Python爬取了某宝1166家月饼数据进行可视化分析,终于找到最好吃的月饼~
- 在 Linux 上试试这个基于 Python 的文件管理器
- Python列表解析式到底该怎么用?
- 如何快速把你的 Python 代码变为 API
- 十个Python初学者常犯的错误