
Python微博移动端爬虫实例(附代码)
2023-03-07 09:52:13 时间
本文简要讲述用Python爬取微博移动端数据的方法。可以看一下Robots协议。另外尽量不要爬取太快。如果你毫无节制的去爬取别人数据,别人网站当然会反爬越来越严厉。至于为什么不爬PC端,原因是移动端较简单,很适合爬虫新手入门。有时间再写PC端吧!
环境介绍
Python3/Windows-10-64位/微博移动端
网页分析
以获取评论信息为例(你可以以自己的喜好获得其他数据)。如下图:
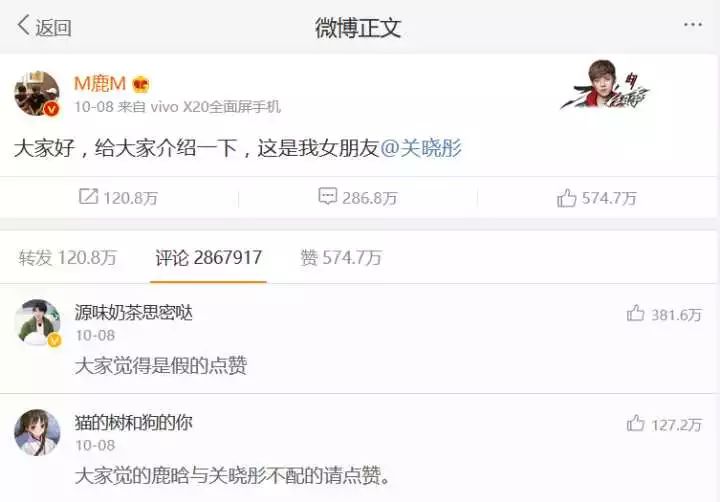
在这里就会涉及到一个动态加载的概念,也就是我们只有向下滑动鼠标滚轮才会加载出更多的评论数据。这也是网页经常使用的方式。接下来就应该找到评论信息的真实网址,找到真实网址的方法就是打开浏览器的开发者工具,火狐/谷歌是F12键。打开如下:
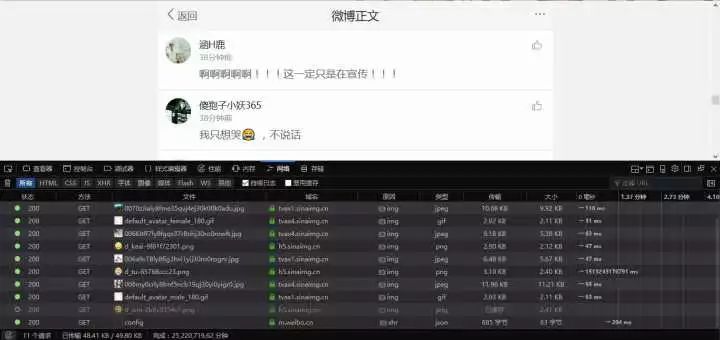
打开以后点击网络,网络用来记录浏览器和服务器交换的信息。接下来将鼠标滚轮缓慢向下滚动,在这个过程中就会弹出类似于上图的信息,也就是评论信息加载出来了。找到评论信息,应该会在***条。如下图:
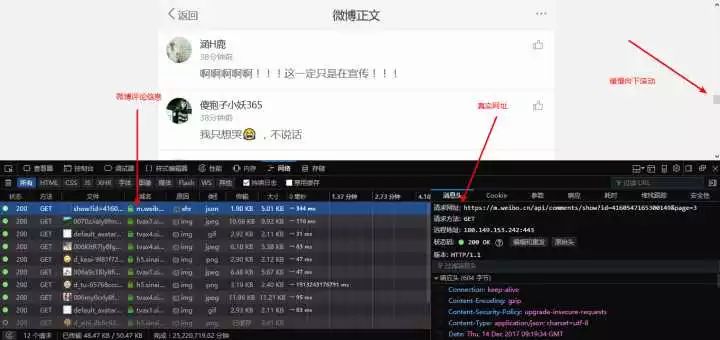
真实网址:https://m.weibo.cn/api/comments/show?id=4160547165300149&page=3
将网址在火狐里面打开如下图:
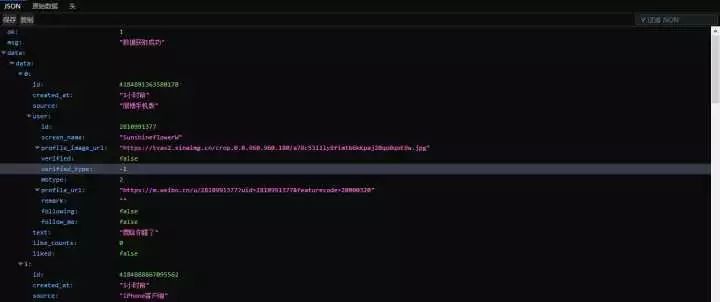
上面的网址其实pages=3就代表第三页,所以只需模拟网址即可,pages=4,5,6。。。。
另外由于是Json文件,所以提取数据非常方便,只需用切片操作即可。
相关文章
- GRPC: 如何添加 API 日志拦截器/中间件?
- 用Python画中国地图,实现各省份数据可视化
- 用Python做疫情数据分析,多维度解析传播率和趋势,未来是乐观的
- Python的import语句笔记
- 这4种统计代码执行耗时,才足够优雅!
- GreenPlum的那些事《五》——浅谈GPDB中的资源队列
- 前后端分离 Vue + Egg.js + Mysql 的 JS全栈实践。动态菜单,RBAC权限模型,WebSocket实现站内信。已部署到线上!!!
- Pychram
- Spring中的定时器都会了?
- Python自学之路—位运算
- Python自学之路—条件、循环语句
- Python自学之路—变量与运算
- 开始着手用Python写一个游戏脚本
- python爬虫爬取QQ号
- HaaS轻应用之Python篇|阿里云产品内容精选(三十七)
- 作为2021年计算机初学者你必须要知道的上云那些事
- 一张图带你搞懂Node事件循环
- 全国41611个景点,用Python告诉你哪些地方更值得一游!
- python 来查 肯德基 address
- python 批量修改文件名