
带你读Paper丨分析ViT尚存问题和相对应的解决方案
摘要:针对ViT现状,分析ViT尚存问题和相对应的解决方案,和相关论文idea汇总。
本文分享自华为云社区《【ViT】目前Vision Transformer遇到的问题和克服方法的相关论文汇总》,作者:苏道 。
首先来看ViT始祖级论文:
An image is worth 16x16 words: Transformers for image recognition at scale
论文地址:https://arxiv.org/abs/2010.11929
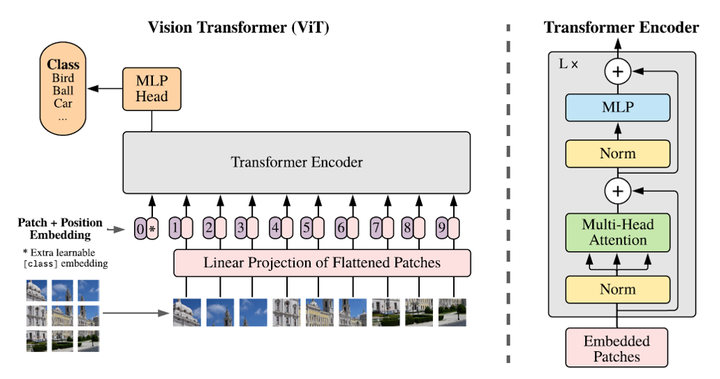
他使用全Transformer结构,将图像区域划分为一个个小方块作为Patch作为输入。左图是ViT的总体架构,右边是Transformer Encoder中每个Block的外形。我们可以看到,他基本就是原始Transformer的结构,除了他把norm放在前面,有文章表明norm放在前面更加容易训练一点。
使用Transformer可以在每一层都得到图片的全局信息,但是他也不是十全十美的,他有以下的这些缺点:
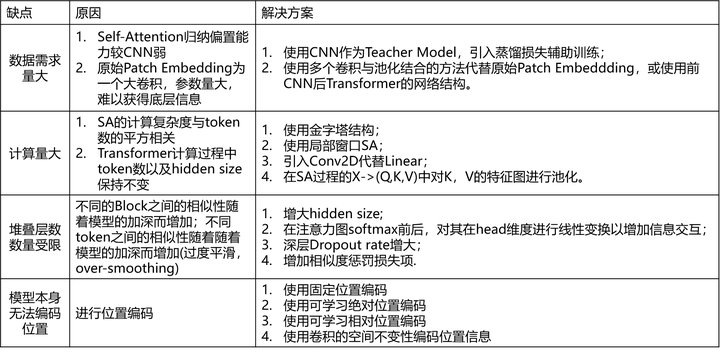
1、数据需求量大: Self-Attention归纳偏置能力较CNN弱。归纳偏置怎么说呢,就是模型对没遇到的数据做的一些假设,CNN具有空间不变性的假设,所以他可以用一个权重去滑窗处理整个特征图,而RNN具有时间不变性的假设。但是Self-Attetnion没有这些假设,所以他需要更多的数据去自动学习到这些假设,但是这样有一个好处就是可能学到的假设会更灵活一些。
那针对这个问题,我们可以使用一个CNN网络作为Teacher网络,添加蒸馏损失去帮助他学习。
Patch Embedding本质是一个卷积核与滑动步长都为Patch size的大卷积和,想Vit为16的卷积核,那肯定是不够稳定的,所以后来的一些研究会使用几个卷积与池化相结合或者干脆前几个block是残差块的方式来代替。
2、计算量大:计算复杂度与token的平方相关,如果输入特征图为56*56的特征图,那么会涉及3000+长宽的矩阵运算,计算量很大,同时在原始Transformer计算过程中token数以及hidden size保持不变,所以后来的研究者采用了几个方法是解决计算量大的问题。参考resnet结构使用金字塔的结构,越高层的token数量越少;使用局部窗口sa,分别考虑特征图的一部分做sa,再想办法把这些局部信息进行交互;使用卷积来代替fc,以减少参数;在生成Q,K,V过程中,对K,V的特征图或者是token做池化,减少计算复杂度。
3、堆叠层数数量受限:存在过度平滑问题,不同的Block之间的相似性随着模型的加深而增加;不同token之间的相似性随着随着模型的加深而增加。解决方法主要是增大hidden size,不过这个方法参数增加量也会很大;在注意力图softmex前后,在head维度进行线性变换以增加信息交互,增加注意力图的多样性;在深层dropout增大以增加特征的多样性;或者增加相似度惩罚损失项。
4、模型本身无法编码位置:那就需要各种各样的位置编码,以下列出了一些位置编码,有固定的与可学习的,有绝对的和相对的,还有利用卷积的特性使用卷积去作为位置编码的。
具体可见下表
上述改进点相关论文大家可以查下表:


相关文章
- 技术实践丨体验量子神经网络在自然语言处理中的应用
- 如何解决回归任务数据不均衡的问题?
- 应对全场景AI框架部署挑战,MindSpore“四招”让你躺平
- 教你三种jQuery框架实现元素显示及隐藏动画方式
- 一文你带快速认识Vue-Router路由
- AI如何提升10倍筛药效率?6月18日华为云携手中科院上海药物所揭开谜底
- 我的编辑器能玩贪吃蛇,一起玩不?
- 教你在Kubernetes中快速部署ES集群
- 毕昇 JDK:为啥是ARM 上超好用的 JDK
- 带你剖析鸿蒙轻内核任务栈的源代码
- 一文教会你认识Vuex状态机
- 解读8大场景下Kunpeng BoostKit 使能套件的最佳能力和实践
- 解读革命性容器集群CCE Turbo:计算、网络、调度全方位加速
- GaussDB(DWS)发生数据倾斜不要慌,一文教你轻松获取表倾斜率
- 五层验证系统,带你预防区块链业务漏洞
- 从原理到实践,手把手带你轻松get数仓双集群容灾
- 搞定研发知识管理,你的企业就能跑快一步
- 支持边云协同终身学习特性,KubeEdge子项目Sedna 0.3.0版本发布!
- 华为云IoT设备接入服务全体验
- 踩准时钟节拍、玩转时间转换,鸿蒙轻内核时间管理有妙招