无状态操作【Stateless】
过滤-filter:
作用:筛选出符合规则的元素
方法定义:
接收 断言函数式接口 Predicate,接收一个参数,返回boolean类型结果
Stream<T> filter(Predicate<? super T> predicate);
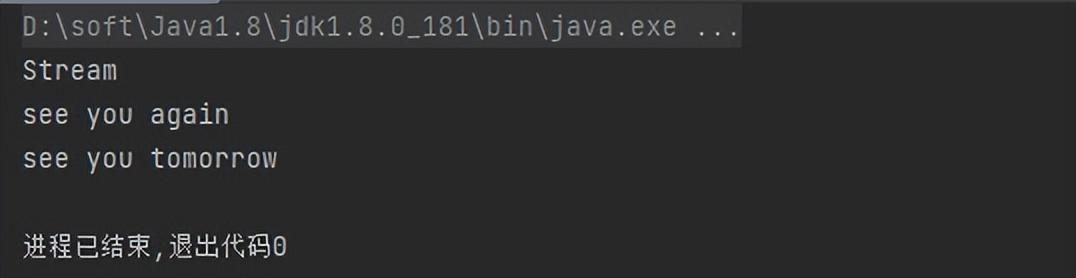
案例:获取字符串数组中,字符串长度大于5的元素
// 定义数组
String[] strArr = {"hello","am","Stream","see you again","see you tomorrow"};
// 过滤
Stream<String> result = Arrays.stream(strArr).filter(str -> str.length() > 5);
// 遍历
result.forEach(System.out::println);
运行结果:
映射-map、flatMap
map:对每一个元素进行指定操作后,返回新的元素,比如:数学运算,类型转换等操作
方法定义:
接收Function类型函数式接口,接收一个T类型参数,并返回一个R类型参数
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
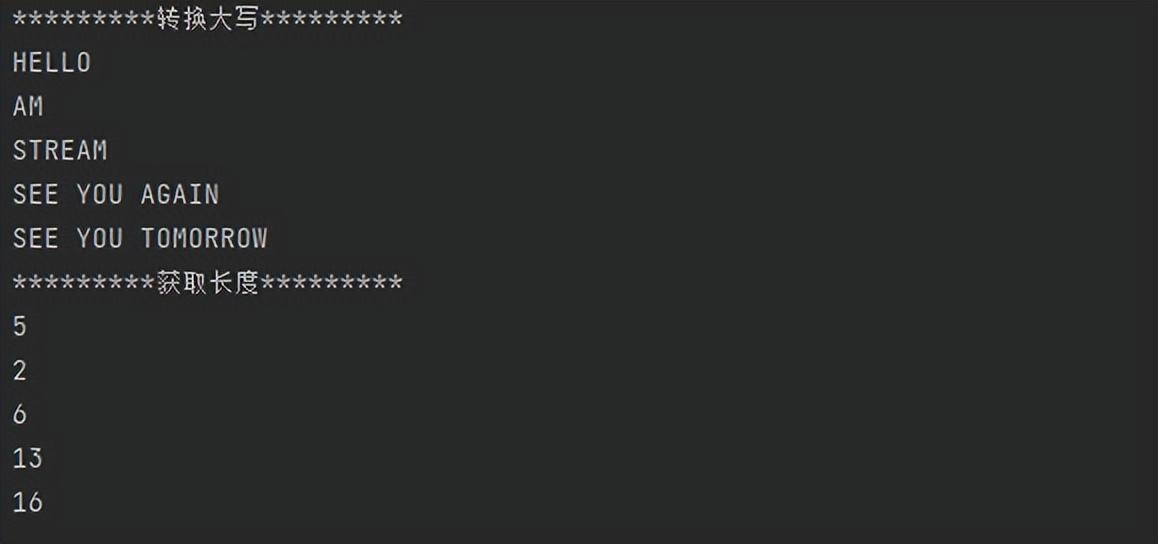
案例:
// 定义数组
String[] strArr = {"hello","am","Stream","see you again","see you tomorrow"};
// 转换为流对象
Stream<String> stream1 = Arrays.stream(strArr);
// 1、转换大写
Stream<String> upperCaseResult = stream1.map(str -> str.toUpperCase());
System.out.println("*********转换大写*********");
// 遍历
upperCaseResult.forEach(System.out::println);
// 2、获取每一个字符串长度
System.out.println("*********获取长度*********");
// 必须再次转换流,上一个流【stream1】执行了forEach的终止操作,已经关闭不能再使用
Stream<String> stream2 = Arrays.stream(strArr);
Stream<Integer> lengthResult = stream2.map(str -> str.length());
lengthResult.forEach(System.out::println);
运行结果:
flatMap:可以将流中的每一个值转换成另一个流,然后把所有的流连接起来再变成一个流,这个方法也可以叫压平
方法定义:
接收 Function 类型函数式接口,与map方法定义类似,但是可以接受一个流对象
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
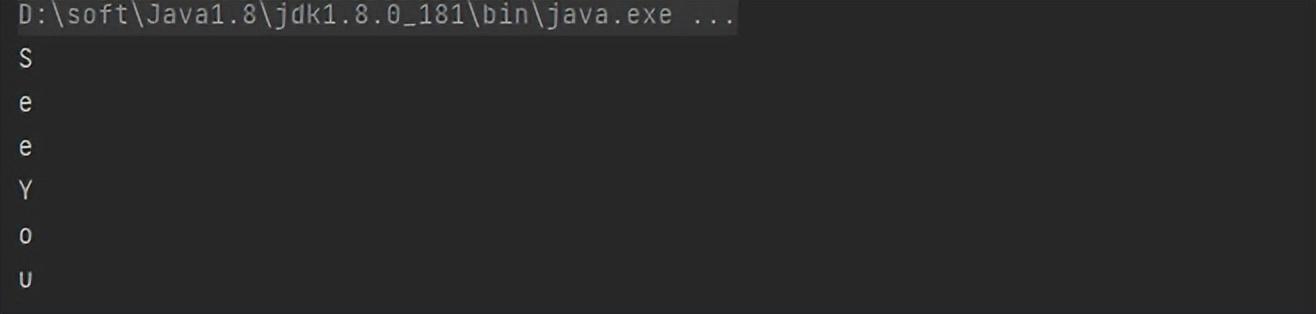
案例:给定单词列表[“See”,“You”],你想要返回列表[“S”,“e”,“e”, “Y”,“o”,“u”]
// 数组
String[] arr = {"See","You"};
// 转换流
Stream<String> stream = Arrays.stream(arr);
Stream<String> stringStream = stream.flatMap(str -> {
/*
将每一个单词按照 ""切割
第一次:See---》["s","e","e"]
第二次:You---》 ["Y","o","u"]
*/
String[] split = str.split("");
// 将字符串数组转换成流,
Stream<String> stream1 = Arrays.stream(split);
return stream1;
});
stringStream.forEach(System.out::println);
运行结果:
转换
转换类型方法有:mapToInt、mapToLong、mapToDouble、flatMapToDouble、flatMapToInt、flatMapToLong
以上这些操作是map和flatMap的特例版,也就是针对特定的数据类型进行映射处理,返回的是指定的InteStream、LongStream、DoubleStream类型的流对象,包含一些数学运算
方法定义:
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper);
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper);
案例:计算数组的总字符长度
这里通过 mapToInt为例,其他的方法 同理
// 定义数组
String[] strArr = {"hello","am","Stream"};
// 转换为流对象,使用 mapToInt 方法获取每一个字符串长度,返回的是IntStream类型的流
IntStream intStream = Arrays.stream(strArr).mapToInt(str -> str.length());
// 调用sum方法计算和
int sum = intStream.sum();
System.out.println(sum);
运行结果:

无序化-unordered
作用:unordered()操作不会执行任何操作来保障有序。它的作用是消除了流必须保持有序的约束,从而允许后续的操作,不必考虑排序,然后某些操作可以做一些特殊优化,注意:是“不保证有序”,不是“保证无序“
案例:
// 串行流
Stream.of(5, 2, 7, 3, 9, 1).unordered().forEach(System.out::println);
// 并行流
Stream.of(5, 2, 7, 3, 9, 1).parallel().unordered().forEach(System.out::println);
注意:
我们单单使用输出其实并不能看出什么端倪,在【JDK8】官方文档中有一句话对无序化做出了解释
对于顺序流,顺序的存在与否不会影响性能,只影响确定性。如果流是顺序的,则在相同的源上重复执行相同的流管道将产生相同的结果;
如果是非顺序流,重复执行可能会产生不同的结果。 对于并行流,放宽排序约束有时可以实现更高效的执行。
在流有序时, 但用户不特别关心该顺序的情况下,使用 unordered 明确地对流进行去除有序约束可以改善某些有状态或终端操作的并行性能。
有状态操作【Stateful】
去重-distinct
作用:根据对象的hashCode()方法和equals()方法来确定是否是相同元素,进行去重
方法定义:方法没有参数,返回一个去重后的流对象
案例:
- 基于【flatMap】案例,获取去重后的流,比如See You,其中e是重复的,我们对其去重
- 对"helloworld"字符串去重【经典面试题,看看使用JDK8特性是多么简单】
// 1、定义数组
String[] arr = {"See","You"};
// 获取流,压平数据并去重
Stream<String> distinct = Arrays.stream(arr).flatMap(str -> Arrays.stream(str.split(""))).distinct();
distinct.forEach(System.out::println);
// 2、字符串去重
Stream<String> stream = Stream.of("helloworld").flatMap(str -> Arrays.stream(str.split(""))).distinct();
stream.forEach(System.out::println);
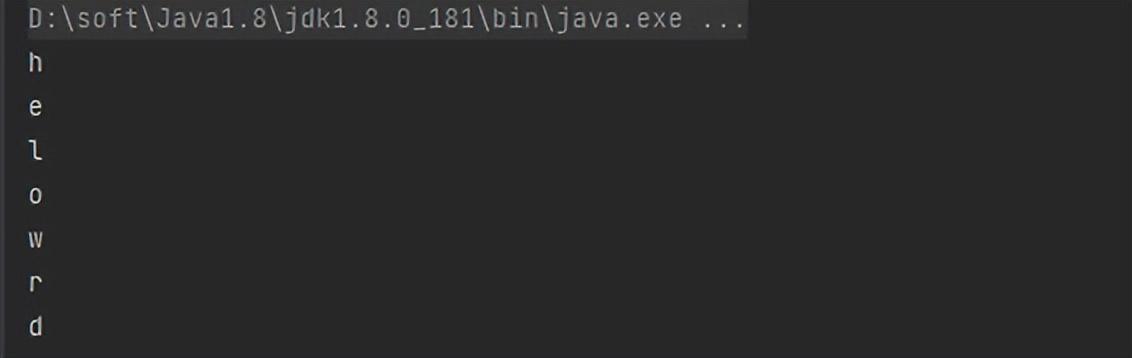
案例1运行结果:
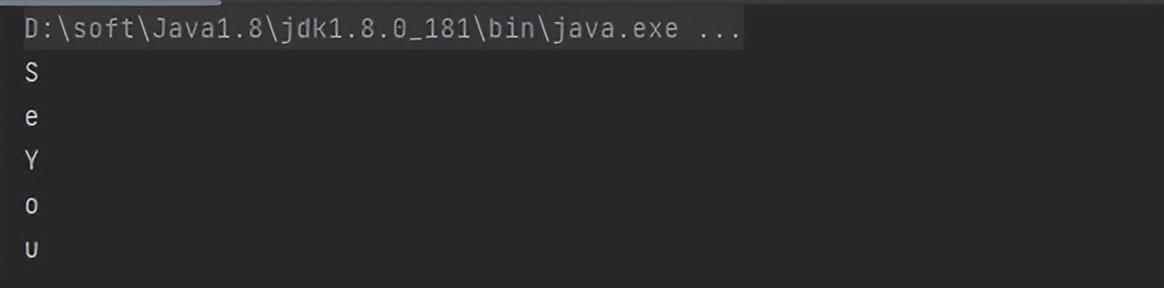
案例2运行结果:
排序-sorted
作用:对流进行排序,该方法有两个重载,一个无参,一个接收 Comparator比较器,传入比较器可以自定义排序
方法定义:
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
案例:对数组进行排序
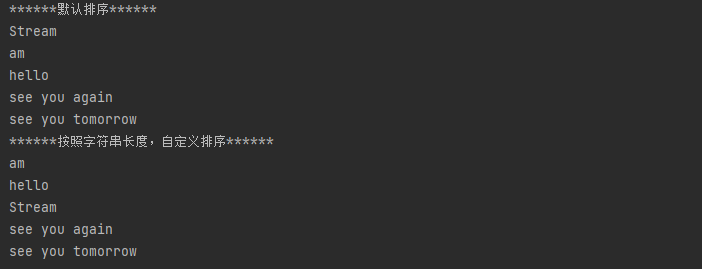
String[] strArr = {"hello","am","Stream","see you again","see you tomorrow"};
// 1、默认排序,按照ASCII码表排序,大写S=83,小写a=97
Stream<String> sorted1 = Arrays.stream(strArr).sorted();
System.out.println("******默认排序******");
sorted1.forEach(System.out::println);
// 2、按照字符串长度排序【自定义排序】
Stream<String> sorted2 = Arrays.stream(strArr).sorted((o1, o2) -> o1.length() - o2.length());
System.out.println("******按照字符串长度,自定义排序******");
sorted2.forEach(System.out::println);运行结果:
指定数量-limit
作用:获取流中n个元素,并返回一个流对象
方法定义:接收一个long类型的数量,返回Stream
Stream<T> limit(long maxSize);
案例:获取四个字符串
Stream.of("hello", "am", "Stream", "see you again", "see you tomorrow").limit(4).forEach(System.out::println);运行结果:

跳过-skip
作用:跳过n个元素,获取其后的所有元素,也可以理解为偏移量
方法定义:与limit类似,区别是功能不同
案例:跳过前两个字符串
Stream.of("hello", "am", "Stream", "see you again", "see you tomorrow").skip(2).forEach(System.out::println);运行结果:

peek
作用:不调整元素顺序和数量的情况下消费每一个元素,然后产生新的流,按文档上的说明,主要是用于对流执行的中间过程做debug的时候使用,因为Stream使用的时候一般都是链式调用的,所以可能会执行多次流操作,如果想看每个元素在多次流操作中间的流转情况,就可以使用这个方法实现
方法定义:接收一个 消费型Consumer函数接口,返回Stream对象
Stream<T> peek(Consumer<? super T> action);
案例:每次对流计算之后,看当前的计算结果
List<String> collect = Stream.of("hello", "am", "Stream", "see you again", "see you tomorrow")
.filter(str -> str.length() > 5)
.peek(System.out::println)
.map(str -> str.toUpperCase())
.peek(System.out::println)
.sorted(((o1, o2) -> o1.length() - o2.length()))
.collect(Collectors.toList());
System.out.println("***********遍历集合******************");
collect.forEach(System.out::println);运行结果:

至此【中间操作】介绍完毕,中间操作分为有状态和无状态,这写方法都可以配合连续使用
非短路操作【Unshort-circuiting】
遍历-forEach:
作用:跟普通的for循环类似,不过这个可以支持多线程遍历,但是不保证遍历的顺序
方法定义:接收一个 消费型Consumer函数接口,没有返回值,所以就不能继续往后操作了,直接终止流
void forEach(Consumer<? super T> action);
案例:遍历数组
String[] arr = {"hello", "am", "Stream", "see you again", "see you tomorrow"};
// 1、Lambda遍历
Arrays.stream(arr).forEach(str -> System.out.println(str));
// 2、方法引用遍历
Arrays.stream(arr).forEach(System.out::println);
// 3、对线程遍历
Arrays.stream(arr).parallel().forEach(System.out::println);
// 4、条件遍历,不推荐,建议使用 filter 过滤数据,这种写法看着代码很乱
Arrays.stream(arr).forEach(str -> {
if(str.equalsIgnoreCase("am")) {
System.out.println(str);
}
});转换数组-toArray:
作用:将流转换为数组
方法定义:
- 无参方法:转换为Object类型数组
- 有参方法:转换成指定类型的数组
Object [] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
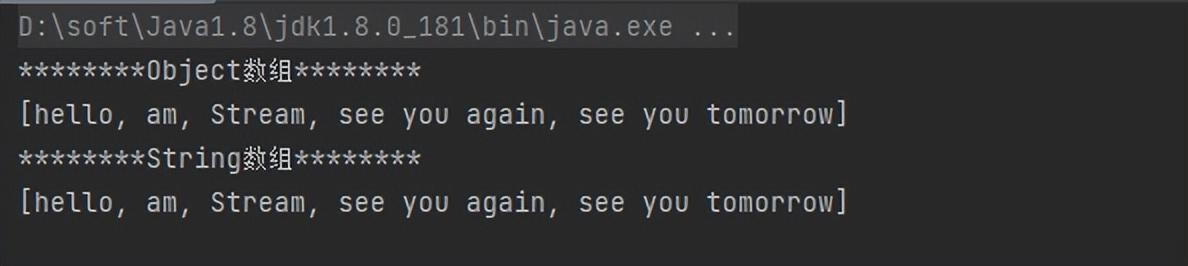
案例:对数组去重,将去重后的数据放到新数组中
String[] arr = {"hello", "am", "Stream", "hello","Stream", "see you again", "see you tomorrow"};
// 去重
Stream<String> distinct = Arrays.stream(arr).distinct();
// 1、转换为Object类型数组
Object[] array = distinct.toArray();
System.out.println("********Object数组********");
System.out.println(Arrays.toString(array));
// 2、转换为Strinbg类型数组
String[] stringArr = Arrays.stream(arr).distinct().toArray(String[]::new);
System.out.println("********String数组********");
System.out.println(Arrays.toString(stringArr));运行结果:
累加器-reduce:
作用:有三个重载方法,作用是对流内元素做累进操作
方法定义:
- 一个参数:对数据进行计算,返回一个Optional对象,接收BinaryOperator函数接口,BinaryOperator接口的抽象方法传入两个参数,并返回一个结果
- 两个参数:对数据进行计算,参数1为初始计算值,也就是参数1先和数组中数据进行一次计算,参数2是一个BinaryOperator接口,返回的是运算结果
- 三个参数:在第二个参数的基础上,追加了一个组合器参数,应用于并行计算,可以改变返回值类型
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
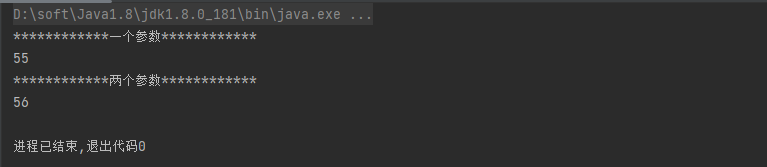
案例1:分别使用一个参数和两个参数的方法进行累加计算
Integer[] arr = {1,2,3,4,5,6,7,8,9,10};
// 1、一个参数的reduce方法
// 因为reduce方法接受的是 BinaryOperator接口,该借口的抽象方法需要两个参数,所以这里写了x,y两个,分别将数组中的值传进去做累加计算
Optional<Integer> reduce = Arrays.stream(arr).reduce((x, y) -> x + y);
// 通过get方法获取Optional数据
Integer integer = reduce.get();
System.out.println("************一个参数************");
System.out.println(integer);
// 2、同样每个数据累加,但是也会累加上第一个参数,在本案例中也就是结果多+1
Integer reduce1 = Arrays.stream(arr).reduce(1, (x, y) -> x + y);
System.out.println("************两个参数************");
System.out.println(reduce1);运行结果:
案例2:三个参数
1、单线程计算
Integer[] arr = {1,2,3,4,5};
Integer reduce = Arrays.stream(arr).reduce(0, (x, y) -> {
System.out.println(Thread.currentThread().getName() + "-x:" + x);
System.out.println(Thread.currentThread().getName() + "-y:" + y);
return x + y;
}, (a, b) -> {
System.out.println(Thread.currentThread().getName() + "-a:" + a);
System.out.println(Thread.currentThread().getName() + "-b:" + b);
return a + b;
});
System.out.println("结果:" + reduce);结果:
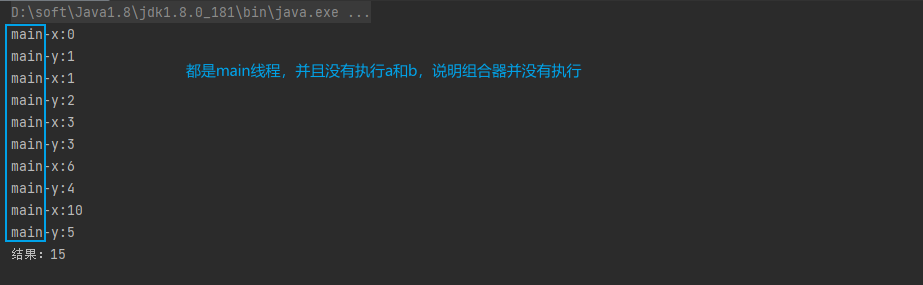
都是main线程在执行,并且没有执行a 和 b
2、多线程运算
使用 parallel() 方法转换为并行流
Integer[] arr = {1,2,3,4,5};
// 添加上 parallel() 方法转换为并行流即可
Integer reduce = Arrays.stream(arr).parallel().reduce(0, (x, y) -> {
System.out.println(Thread.currentThread().getName() + "-x:" + x);
System.out.println(Thread.currentThread().getName() + "-y:" + y);
return x + y;
}, (a, b) -> {
System.out.println(Thread.currentThread().getName() + "-a:" + a);
System.out.println(Thread.currentThread().getName() + "-b:" + b);
return a + b;
});
System.out.println("结果:" + reduce);结果:

可以看出创建了11条线程参与运算,转换为并行流后第三个参数方法才会执行,组合器的作用,其实是对参数2中的各个线程,产生的结果进行了再一遍的归约操作!
收集器-collect:
作用:是一个终止操作,将流中的元素转换为各种类型的结果
方法定义:
- 方法1:比较常用,将数据转换为指定的容器中,或者做求和、分组、分区、平均值等操作
- 方法2:可以用来实现filter、map操作
<R, A> R collect(Collector<? super T, A, R> collector);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
案例1:演示方法1的使用
Employee类准备
public class Employee {
private Long id;
private Integer age;
private String name;
private Double salary;
public Employee(Long id, Integer age, String name, Double salary) {
this.id = id;
this.age = age;
this.name = name;
this.salary = salary;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", age=" + age +
", name='" + name + '\'' +
", salary=" + salary +
'}';
}
}收集器演示:
使用数组和对象集合:一共演示 11 个方法,结果太长,可通过代码自行打印
public class StreamMain {
private static List<Employee> employees = new ArrayList<>();
static {
// 创建数据
employees.add(new Employee(1L,24,"苏小坡",5000.00));
employees.add(new Employee(2L,24,"苏小由",6000.00));
employees.add(new Employee(3L,25,"石小敢",6000.00));
employees.add(new Employee(4L,23,"张小毫",6800.00));
employees.add(new Employee(5L,23,"李小杰",6800.00));
employees.add(new Employee(6L,31,"杜小甫",8000.00));
employees.add(new Employee(7L,29,"辛小疾",8500.00));
}
public static void main(String[] args) {
String[] arr = {"hello", "am", "Stream", "hello","Stream", "see you again", "see you tomorrow"};
// 1、Collectors.toList(): 将数据转换为List集合
List<String> list = Arrays.stream(arr).collect(Collectors.toList());
// 2、Collectors.toSet(): 将数据转换为Set集合
Set<String> set = Arrays.stream(arr).collect(Collectors.toSet());
// 3、Collectors.toCollection(LinkedList::new): 将数据存储进指定的集合中
LinkedList<String> linkedList = Arrays.stream(arr).collect(Collectors.toCollection(LinkedList::new));
// 4、Collectors.counting(): 获取元素个数
Long count = Arrays.stream(arr).collect(Collectors.counting());
// 5、Collectors.summingInt():求和,方法接收一个 ToIntFunction 函数接口,接收一个值,返回一个值
// 还有:summingDouble,summingLong方法,计算Double和Long类型的和
Integer sumAge = employees.stream().collect(Collectors.summingInt(Employee::getAge));
Double sumSalary = employees.stream().collect(Collectors.summingDouble(Employee::getSalary));
Long sumId = employees.stream().collect(Collectors.summingLong(Employee::getId));
// 6、Collectors.averagingInt():求平均值
Double avgAge = employees.stream().collect(Collectors.averagingInt(Employee::getAge));
// 7、Collectors.joining():根据指定字符拼接
String joinName = employees.stream().map(Employee::getName).collect(Collectors.joining(","));
// 8、获取最大薪资【不建议使用】,推荐使用max方法
Optional<Employee> maxSalary = employees.stream().collect(Collectors.maxBy((o1, o2) -> o1.getSalary().compareTo(o2.getSalary())));
System.out.println(maxSalary.get());
// 8、获取最小薪资【不建议使用】,推荐使用min方法
Optional<Employee> minSalary = employees.stream().collect(Collectors.minBy((o1, o2) -> o1.getSalary().compareTo(o2.getSalary())));
System.out.println(minSalary.get());
// 9、Collectors.reducing():规约操作,这个方法也有三个重载,和reduce方法一样,此处对数据做指定运算,并指定一个初始值
Double totalSalary = employees.stream().collect(Collectors.reducing(0.0, Employee::getSalary, Double::sum));
System.out.println(totalSalary);
// 10、Collectors.groupingBy:分组,接收 Function 函数接口,相同的为一组
Map<Integer, List<Employee>> ageMap = employees.stream().collect(Collectors.groupingBy(Employee::getAge));
ageMap.forEach((k,v) -> {
System.out.println(k + "===>" + v);
});
// 10.2:自定义分组名称
Map<String, List<Employee>> ageMap2 = employees.stream().collect(
Collectors.groupingBy(
employee -> {
if (employee.getAge() >= 22 && employee.getAge() < 26) {
return "22岁-26岁:";
} else if (employee.getAge() >= 26 && employee.getAge() < 30) {
return "26岁-30岁:";
} else {
return "30岁以上:";
}
}
));
ageMap2.forEach((k,v) -> {
System.out.println(k + "===>" + v);
});
// 11、Collectors.partitioningBy,分区,接收 断言 Predicate 函数接口,符合条件的分到一起
// 分区可以认为是特殊的分组,只能分为两个区,一个是符合条件的true区,一个是不符合条件的false区,不能自定义
Map<Boolean, List<Employee>> map = employees.stream().collect(Collectors.partitioningBy(employee -> employee.getAge() > 25));
map.forEach((k,v) -> {
System.out.println(k + "===>" + v);
});
}
}案例2:三个参数的收集器,与reduce类似,串行时并不执行参数3,并行时,参数3作为一个汇总
public class StreamMain {
private static List<Employee> employees = new ArrayList<>();
static {
// 创建数据
employees.add(new Employee(1L,24,"苏小坡",5000.00));
employees.add(new Employee(2L,24,"苏小由",6000.00));
employees.add(new Employee(3L,25,"石小敢",6000.00));
employees.add(new Employee(4L,23,"张小毫",6800.00));
employees.add(new Employee(5L,23,"李小杰",6800.00));
employees.add(new Employee(6L,31,"杜小甫",8000.00));
employees.add(new Employee(7L,29,"辛小疾",8500.00));
}
public static void main(String[] args) {
// parallel():设置为并行,参数3会执行
HashSet<Employee> hashSet = employees.stream().parallel().collect(
() -> {
System.out.println("参数1----");
return new HashSet<>();
},
(a, b) -> {
// 累加器, a就是要返回的类型,这里是HashSet,b是每一次的值,就是Employee
System.out.println("参数2----a:" + a + "b:" + b);
// 每个员工涨薪20%
b.setSalary(b.getSalary() * 1.2);
// 将涨薪后的员工添加到HashSet中,返回
a.add(b);
}
,
(x, y) -> {
// 当串行时,此方法不运行
System.out.println("参数3----x:" + x + "y:" + y);
// x和y都是HashSet,这里做一次合并
x.addAll(y);
});
hashSet.forEach(System.out::println);
}
}最大值-max:
作用:获取流中最大值
方法定义:
根据提供的Comparator返回此流的最大元素
Optional<T> max(Comparator<? super T> comparator);
案例:获取数组中最大的数
Integer[] arr = {1,2,3,4,5};
Optional<Integer> max = Arrays.stream(arr).max(Integer::compareTo);
System.out.println(max.get());最小值-min:
作用:获取流中最小值
方法定义:
根据提供的Comparator返回此流的最小元素
Optional<T> min(Comparator<? super T> comparator);
案例:获取数组中最大的数
Integer[] arr = {1,2,3,4,5};
Optional<Integer> min = Arrays.stream(arr).min(Integer::compareTo);
System.out.println(min.get());元素个数-count:
作用:获取流中元素个数
方法定义:方法返回一个long类型数据
案例:获取数组中元素个数
Integer[] arr = {1,2,3,4,5};
// 获取长度:5
long count = Arrays.stream(arr).count();
System.out.println(count);
// 过滤后再获取长度:2
long count1 = Arrays.stream(arr).filter(x -> x > 3).count();
System.out.println(count1);短路操作【Short-circuiting】
任意匹配-anyMatch:
作用:Stream 中只要有一个元素符合传入的 predicate,返回 true;
方法定义:
boolean anyMatch(Predicate<? super T> predicate);
案例:薪资大于8000,如果有符合条件的就直接返回true,不再向下执行
boolean match = employees.stream().anyMatch(employee -> employee.getSalary() > 8000);
全部匹配-allMatch:
作用:Stream 中全部元素符合传入的 predicate,返回 true;
方法定义:
boolean allMatch(Predicate<? super T> predicate);
案例:薪资是否都大于3000,如果所有元素都符合条件就返回true
boolean match = employees.stream().allMatch(employee -> employee.getSalary() > 3000);
无一匹配-noneMatch:
作用:Stream 中没有一个元素符合传入的 predicate,返回 true
方法定义:
boolean noneMatch(Predicate<? super T> predicate);
案例:薪资是否有小于3000的,如果都没有则返回true
boolean match = employees.stream().noneMatch(employee -> employee.getSalary() < 3000);
第一个元素-findFirst:
作用:用于返回满足条件的第一个元素(但是该元素是封装在Optional类中)
方法定义:
案例:获取流中第一个员工
Optional<Employee> first = employees.stream().findFirst();
System.out.println(first.get());
任意元素-findAny:
作用:返回流中的任意元素(但是该元素也是封装在Optional类中)
方法定义:
案例:获取任意一个薪资大于6000的员工名字
Optional<String> any = employees.stream().filter(employee -> employee.getSalary() > 6000).map(Employee::getName).findAny();
System.out.println(any.get());
通过多次执行,findAny每次返回的都是第一个元素,怀疑和findFirst一样,其实不然,findAny()操作,返回的元素是不确定的,对于同一个列表多次调用findAny()有可能会返回不同的值。使用findAny()是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,如果是并行的情况,那就不能确保是第一个
比如并行:此时返回的值就不确定,但是少量数据时重复概率还是很大的,可能是因为Java编译器JIT做了优化,快速执行出一个结果
Optional<String> any = employees.parallelStream().filter(employee -> employee.getSalary() > 6000).map(Employee::getName).findAny();
System.out.println(any.get());
操作文件
通过java.nio.file.Files对象的lines方法对文件进行流处理
public class StreamMain {
public static void main(String[] args){
// 将文件转换为Path对象
Path path = new File("D:\\00-code\\stt-open\\stt-01-stream\\src\\main\\java\\com\\stt\\stream2\\stream.txt").toPath();
try {
// 使用nio中的Files对象将文件根据行转换为流
Stream<String> lines = Files.lines(path, StandardCharsets.UTF_8);
lines.forEach(System.out::println);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}运行结果:
定风波
苏轼
三月七日,沙湖道中遇雨。
雨具先去,同行皆狼狈,余独不觉,已而遂晴,故作此词。
莫听穿林打叶声,何妨吟啸且徐行。
竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生。
料峭春风吹酒醒,微冷,山头斜照却相迎。
回首向来萧瑟处,归去,也无风雨也无晴。
总结
- Stream配合Lambda可以非常方便操作计算数据,让冗余的代码变的整洁
- 尽量不要让sql去做复杂的查询,数据库主要作用是数据存储,复杂查询会降低性能
- 多数语言中比如Python、Scala等语言中都存在流操作,也有助于掌握其它语言
- Stream API的方法较多,知道有哪些处理方法,需要使用时可以点进源码看使用说明
- 需要多多使用,在项目中大胆使用,多多益善
