
SQL优化-三
一:分析MySQL In查询为什么所有不生效
结论:IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描
navicat可视化工具使用explain函数查看sql执行信息
1.1 场景1:当IN中的取值只有一个主键时
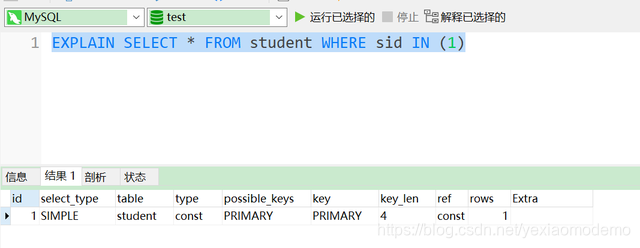
我们只需要注意一个最重要的type 的信息很明显的提现是否用到索引:
type结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
all:全表扫描
index:另一种形式的全表扫描,只不过他的扫描方式是按照索引的顺序
range:有范围的索引扫描,相对于index的全表扫描,他有范围限制,因此要优于index
ref: 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
const:通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以及何时转化,这个取决于优化器
一般来说,得保证查询至少达到range级别,最好能达到ref,type出现index和all时,表示走的是全表扫描没有走索引,效率低下,这时需要对sql进行调优。
当extra出现Using filesor或Using temproary时,表示无法使用索引,必须尽快做优化。
possible_keys:sql所用到的索引
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
rows: 显示MySQL认为它执行查询时必须检查的行数。
这里可以参考之前写的一篇:用MySQL 执行计划分析 DATE_FORMAT 函数对索引的影响
1.2 场景2:扩大IN中的取值范围
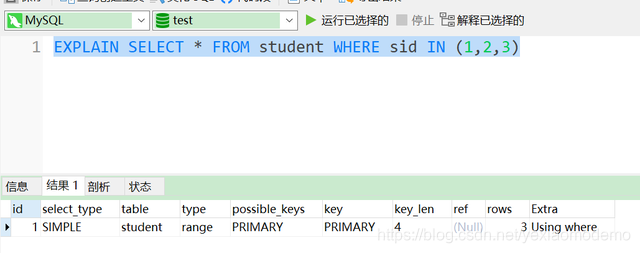
此时仍然走了索引,但是效率降低了
1.3 场景3:继续扩大IN的取值范围
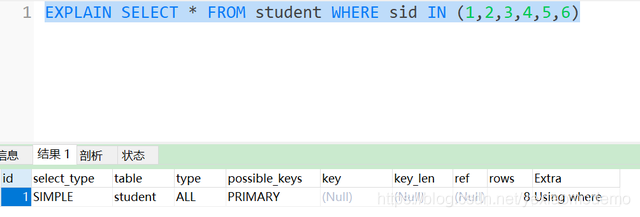
看上面的图,发现此时已经没有走索引了,而是全表扫描。
在说一下结论
结论:IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描。
By the way:如果使用了 not in,则不走索引。
上述内容转载自:
二:MySQL 需要 IN查询但是很慢怎么办 ?
从上文得知我们的IN查询索引不生效,以及不生效的原因。
2.1 这是一个常用的IN查询
- SELECT id, order_index, data_order_start, update_time, create_time, gov_frame_id
- FROM gov_price_category_detail
- WHERE
- gov_frame_id IN (
- SELECT id FROM gov_price_frame WHERE deleted=1 AND is_spider=0 AND city IN ( '长沙市' ) GROUP BY id
- )
- AND deleted=1
- AND data_order_start < 51

2.2 我们把IN查询 改造成 inner 查询
- SELECT gcd.id, gcd.order_index, gcd.data_order_start, gcd.update_time, gcd.create_time, gcd.gov_frame_id
- FROM gov_price_category_detail gcd , ( SELECT gp.id FROM gov_price_frame gp WHERE gp.deleted=1 AND gp.is_spider=0 AND gp.city IN ( '长沙市' ) GROUP BY gp.id ) gpf
- WHERE
- gpf.id = gcd.gov_frame_id
- AND gcd.deleted=1
- AND gcd.data_order_start < 51

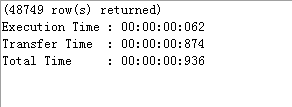
3.3 优化后速度对比
原始SQL速度信息: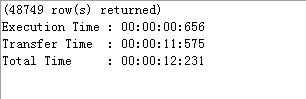
优化后SQL速度信息:
上一篇:《记一次MySQL 查询慢索引不生效过程 二》
相关文章
- 忙活了一年的开源社区,终于赶上了春节前的末班车!
- ChatGPT 会开源吗?
- 7 款殿堂级的开源 CMS(内容管理系统)
- 请收下这 10 个安全相关的开源项目
- MySQL 5.7 升级到 8.0
- 越折腾越好用的 3 款开源 APP
- 10 款更先进的开源命令行工具
- 对开源框架跃跃欲试,却在写的时候犯了难?
- 一大波开源小抄来袭
- 物联网?快来看 Arduino 上云啦
- 想做钢铁侠?听说很多大佬都是用它入门的
- 写给小白的开源编译器
- 支持中文!秒建 wiki 知识库的开源项目,构建私人知识网络
- 一款开源的文件搜索神器,终于不用记 find 命令了
- 用一个文件,实现迷你 Web 框架
- 一个文件的开源项目,开启你的开源之旅
- 3.6 万颗星!开源 Web 服务器后起之秀,自带免费 HTTPS 开箱即用
- 狠人!标星 3.4 万的项目说删就删,几行代码搞崩数万个开源项目
- 那些年的开源项目,你跑起来了吗?
- 重玩 40 年前的经典游戏小蜜蜂,这次通关了源码