
卷积神经网络(CNN)详解
神经网络不是具体的算法,而是一种模型构造的思路或者方式,全连接神经网络每一个神经元节点的输入都来自于上一层的每个神经元的输出,好处在于每个输入维度的信息都会传播到其后的任意一个结点中去,会最大程度地让整个网络中的节点都不会“漏掉”这个维度所贡献的因素。不过他的缺点更加明显,那就是整个网络由于都是“全连接”方式,所以$w$和$b$参数格外的多,这就使得训练过程中说要更新的参数权重非常多,整个网络训练的收敛会非常慢。于是发明了卷积神经网络(Convolutional Neural Network, CNN)。
卷积神经网络同样是一种前馈神经网络,他的神经元可以响应一部分覆盖范围内的周围单元,在大规模的模式识别有很好的性能表现,该网络可以避免对图片的复杂前期预处理,直接输入原始图像。
全连接网络的局限性
- 参数数量太多
- 没有利用像素之间的位置信息
- 网络层数限制
卷积网络的优点
- 局部连接:这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
- 权值共享:一组连接可以共享同一个卷积核权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
- 下采样:可以使用stride来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。
卷积的数学定义
函数$f$和$g$的卷积表示 经过翻转和平移的重叠部分的面积。
$$h(x)=f(x)*g(x)=\int_{-\infty }^{+\infty }f(t)g(x-t)dt$$
$f(t)$先不动,$g(-t)$相当于$g(t)$函数的图像沿着$y$轴$(t=0)$做一次翻转。$g(x-t)$相当于$g(-t)$的整个图像沿着$t$轴向右平移$x$个单位。卷积的值等于$f(t)$和$g(x-t)$相乘后与$y=0$轴围的面积。
卷积神经网络
Pytorch文档中Conv2d模块
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)输入:$(N, C_{in}, H_{in}, W_{in})$
输出:$(N,C_{out},H_{out},W_{out})$
$$H_{out}=\frac{H_{in}+2*padding[0]-dilation[0]*(K[0]-1)-1}{stride[0]}+1$$
$$W_{out}=\frac{W_{in}+2*padding[1]-dilation[1]*(K[1]-1)-1}{stride[1]}+1$$
conv2d.weight:$(C_{outut},\frac{C_{in}}{groups},K[0],K[1])$
conv2d.bias:$(C_{out},)$
- in_channels ( int ) — 输入图像中的通道数
- out_channels ( int ) — 卷积产生的通道数
- kernel_size ( int or tuple ) — 卷积核的大小
- stride ( int or tuple , optional ) — 卷积的步幅。默认值:1
- padding ( int or tuple , optional ) — 添加到输入两侧的零填充。默认值:0
- dilation ( int or tuple , optional ) — 内核元素之间的间距。默认值:1
- groups ( int , optional ) — 从输入通道到输出通道的阻塞连接数。默认值:1
- bias ( bool , optional ) — 如果True,则向输出添加可学习的偏差。默认:True
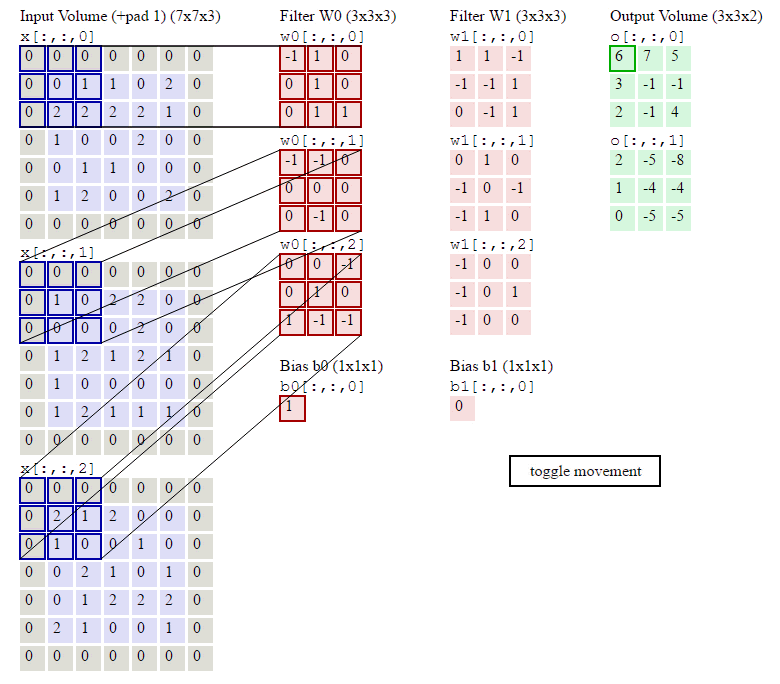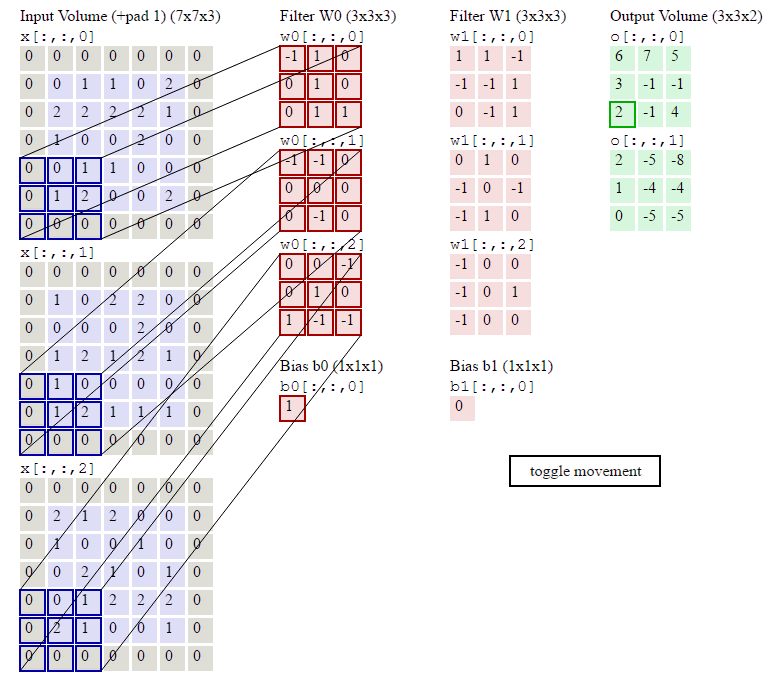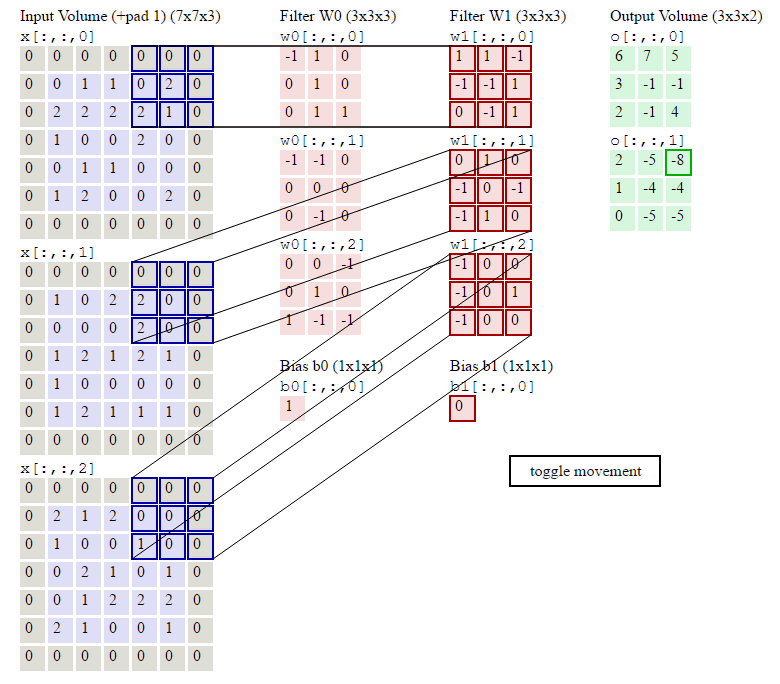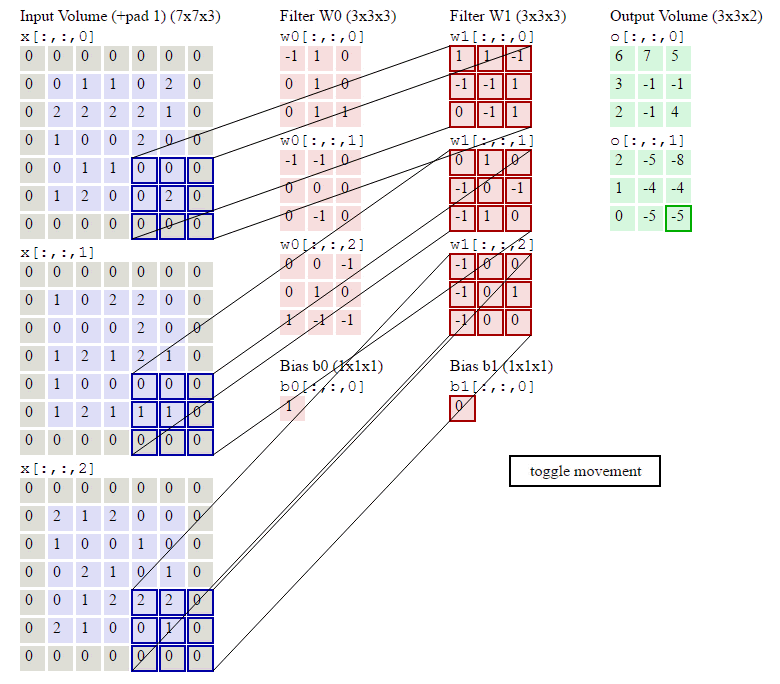
卷积神经网络中的卷积过程是:卷积核(卷积矩阵/滤波器)对输入矩阵进行从左到右,从上到下卷积乘积,得到feature map的过程。卷积神经网络的权重参数在卷积核上,卷积核的计算公式为:$f(x)=\sum _i^{keral\_size}w_ix_i+b$。
卷积过程如下所示:我们先假设有这样一幅图像 (通道数, 高度,宽度),大小为:(1, 5, 5)。卷积核大小为(3, 3),偏置项为0,卷积后,得到一个(1, 3, 3)的feature map(卷积输出)。
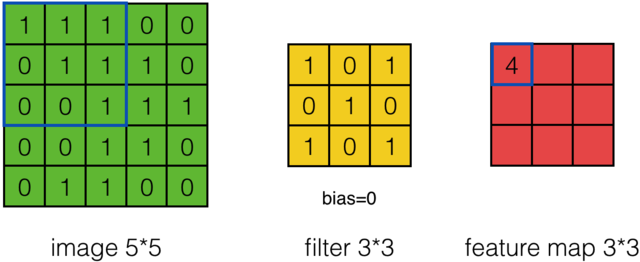
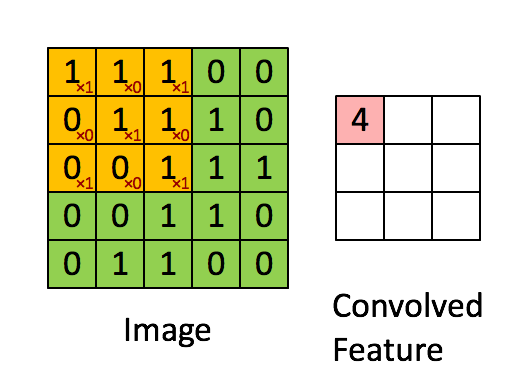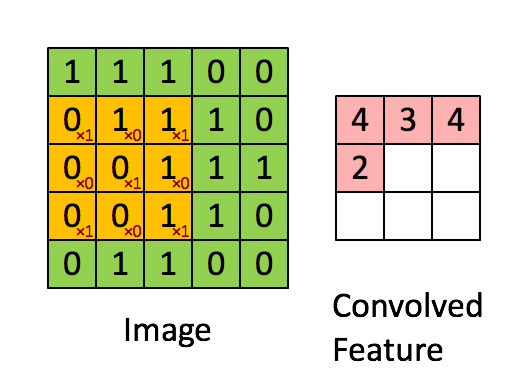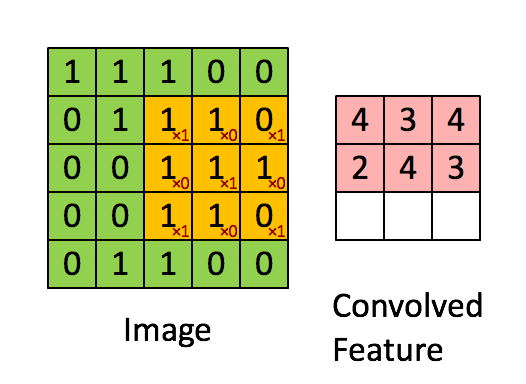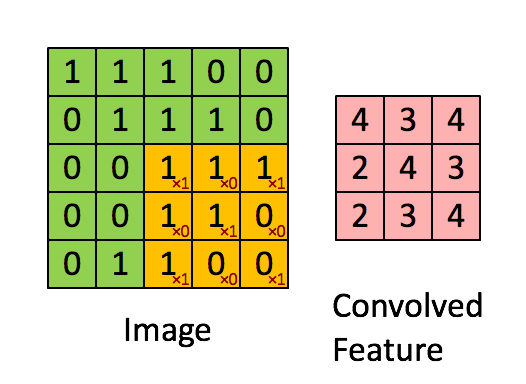
feature map的第一个值的计算过程为:
$$feature\ map(1)=(1*1)+(0*1)+(1*1)+(0*0)+(1*1)+(1*0)+(0*1)+(0*0)+(1*1)+0=4$$
由上图可知9个局部像素信息被压缩成1个,这当然属于有损压缩,还原肯定是还原不回去的了。这个抽样的过程就叫做特征提取,同时也是一种信息压缩。通过上面的公式可以发现卷积核影响$H_{out}$和$W_{out}$,卷积核的shape可以是3*3,也可以是1*1,不要求一定是方形的,但是一般要求卷积核大小是奇数,选择奇数大小的内核是因为中心像素周围存在对称性。
卷积层参数
卷积层的参数$w、b$首先会更新进行初始化,然后在降低损失函数的目的下不断更新网络参数,直至模型收敛。在 Conv2d 中,可训练参数是卷积核的值。卷积核的计算公式为:$f(x)=\sum _i^{keral\_size}w_ix_i+b$。
对于 3×3 卷积核,我们有 3*3=9 个可训练参数,我们可以包括或不包括偏置项(bisa)。偏置的作用是加到卷积乘积的总和上。这种bisa也是一个可训练 参数,它使我们的 3 x 3 内核的可训练参数数量增加到 10。
在卷积核的$f(x)=wx+b$输出后一般会跟一个激励函数紧随其后,现在的CNN网络中的激励函数非常喜欢用ReLU函数。为了减少篇幅,大家想要了解激活函数的可以移步:深度学习中的激活函数 (我总结的好辛苦的?)
输入输出通道数
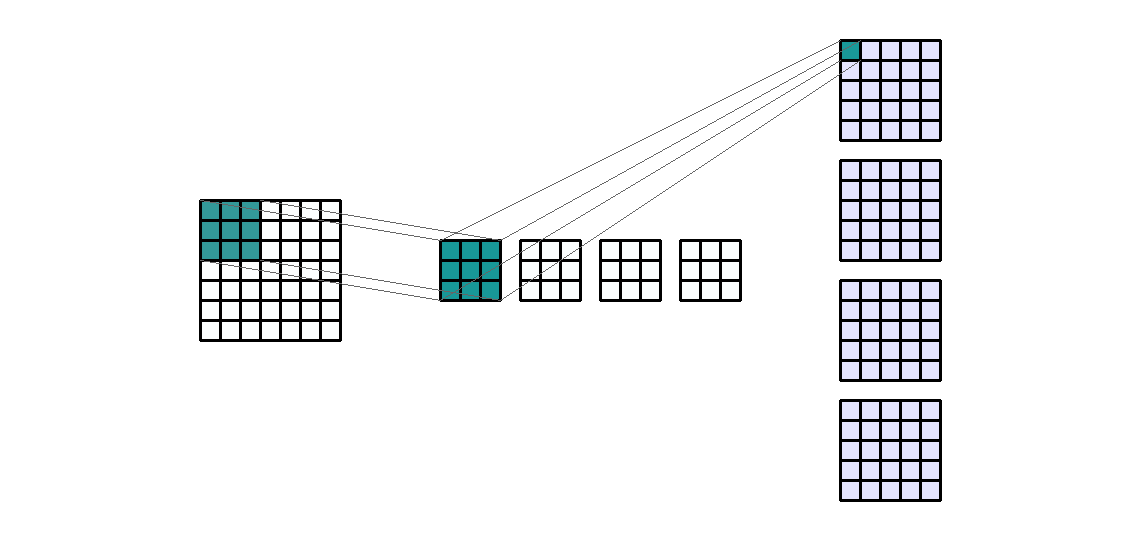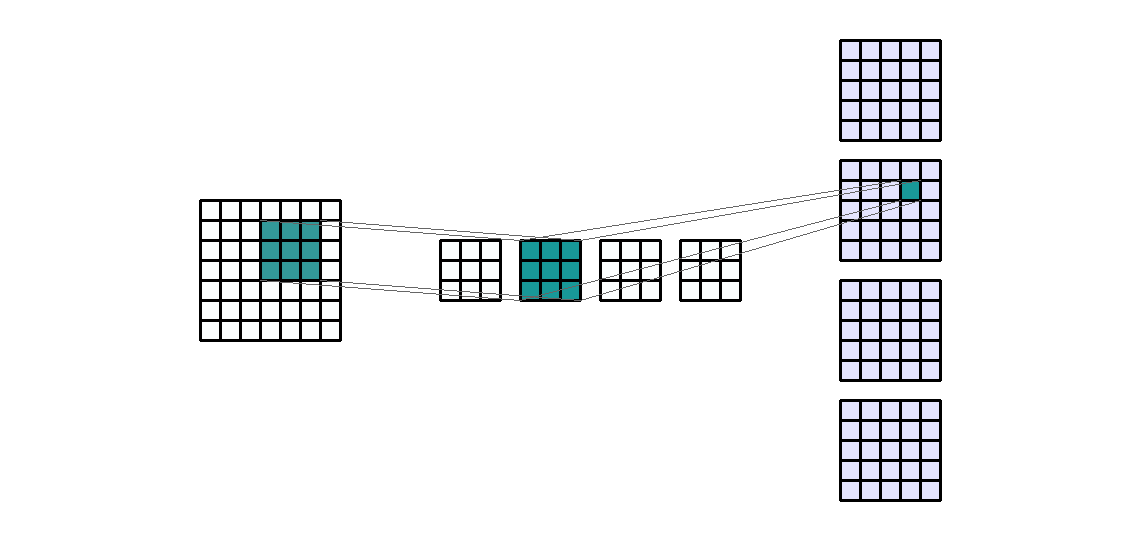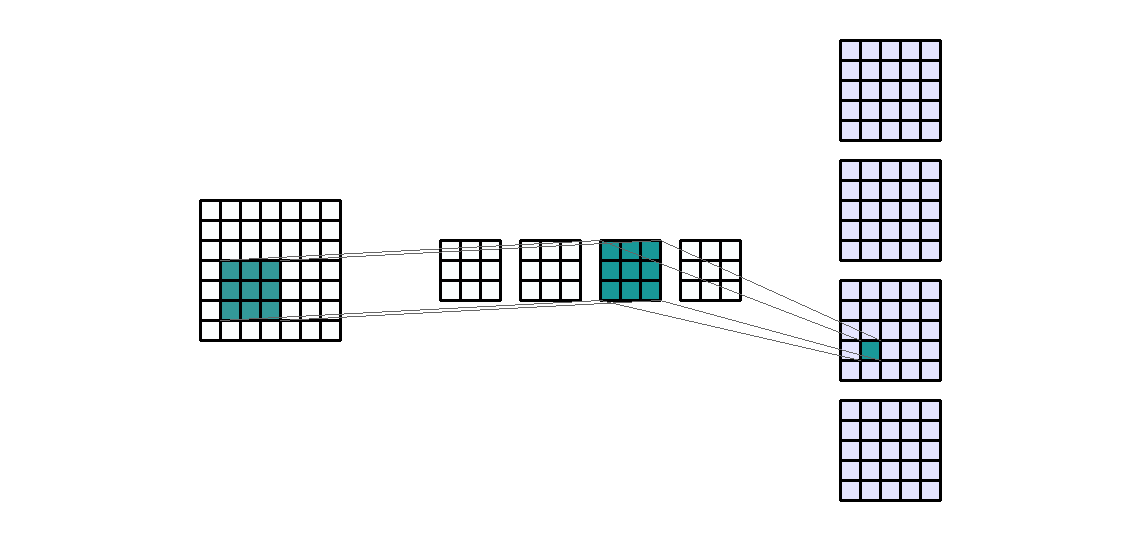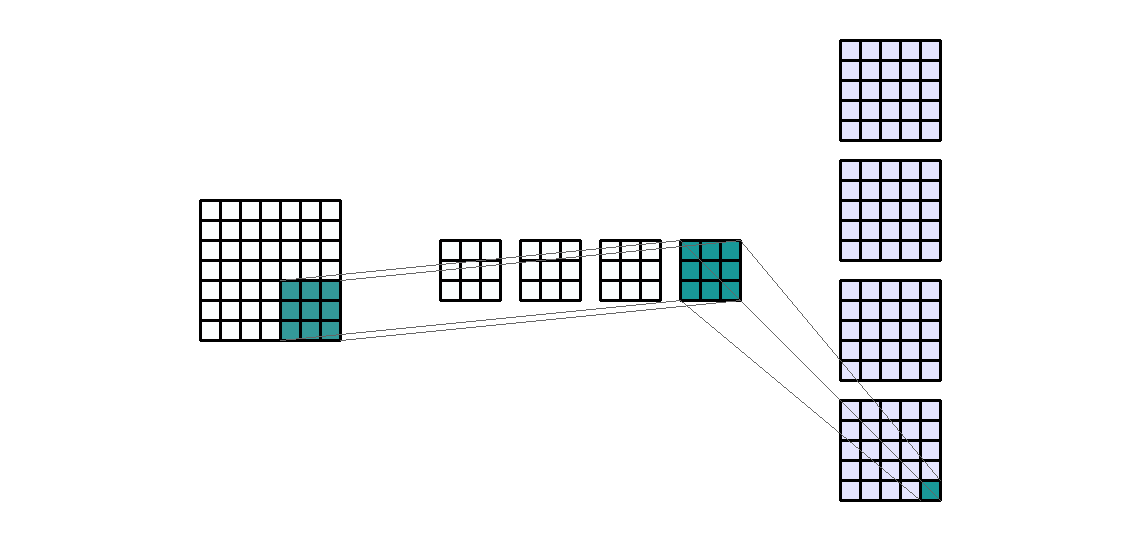 输入形状:(1, 7, 7) — 输出形状:(4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1 , 1) — G : 1
输入形状:(1, 7, 7) — 输出形状:(4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1 , 1) — G : 1
如上图所示,输入通道数是1,应用 4 个相同大小的不同过滤器,得到4个输出通道。这些通道是 4 个不同过滤器的结果。我们来计算以下卷积层的可训练参数:$\text{parameters }=C_{out}*C_{in}*K[0]*K[1]+bias=4*1*3*3+4=40$
import torch inputs = torch.randn(32, 1, 28, 28) model = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=(3, 3), stride=(1, 1), padding=0, dilation=1, groups=1, bias=True) # 40个参数 outputs = model((inputs)) print(outputs.shape) # [32, 3, 26, 26]
同样的,当输入有时多通道时,比如:RGB图像,有3个通道,我们可以在这 3 个通道的每一个上使用相同大小的过滤器提取信息,以获得四个新通道。
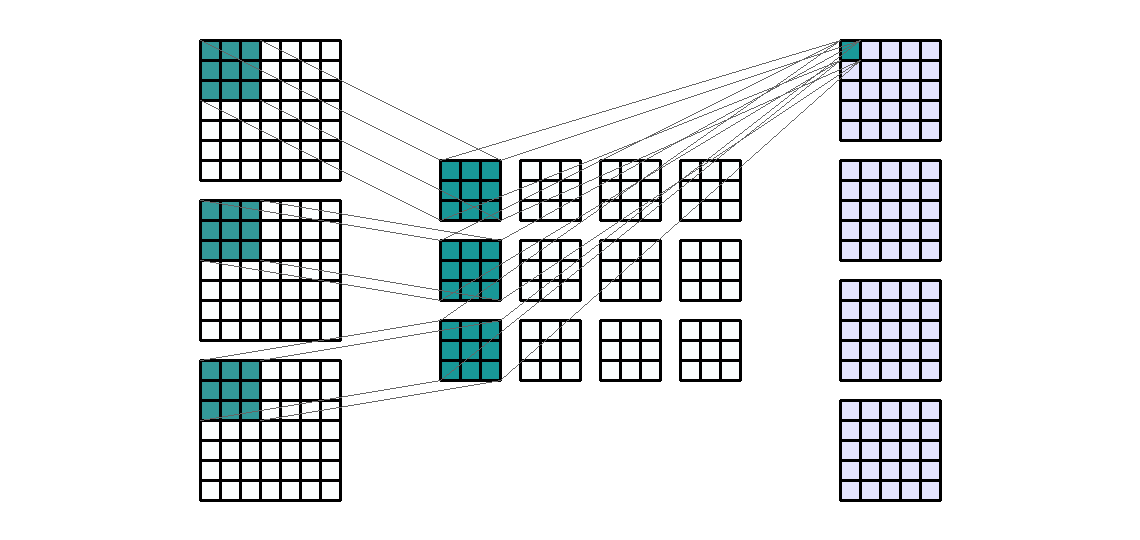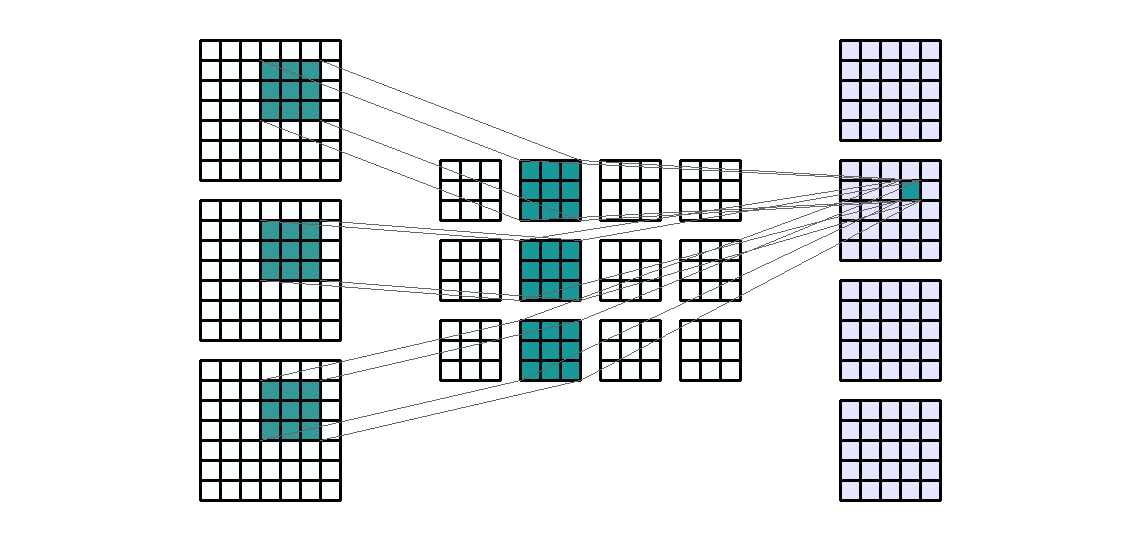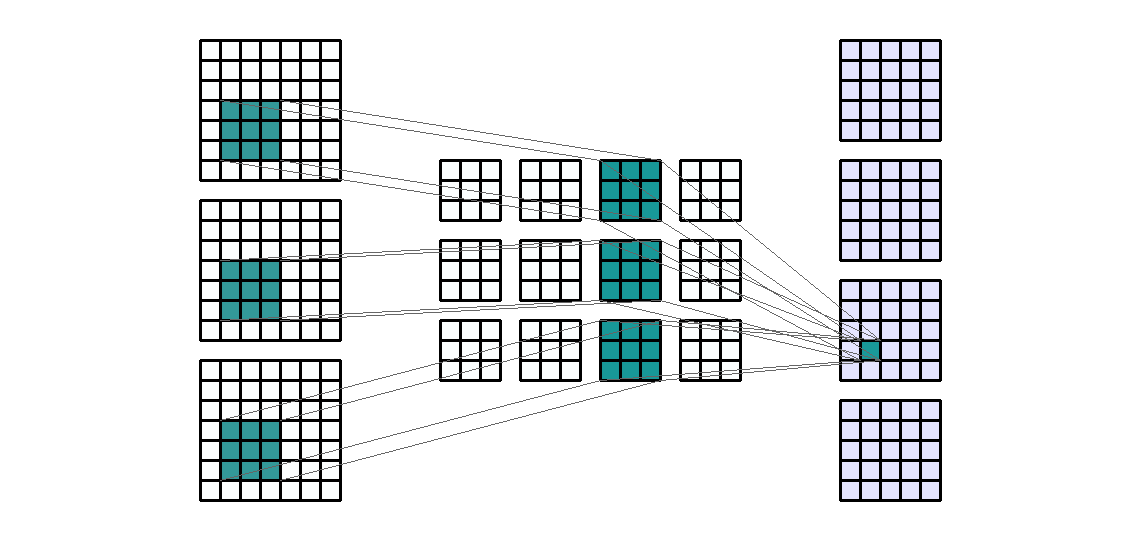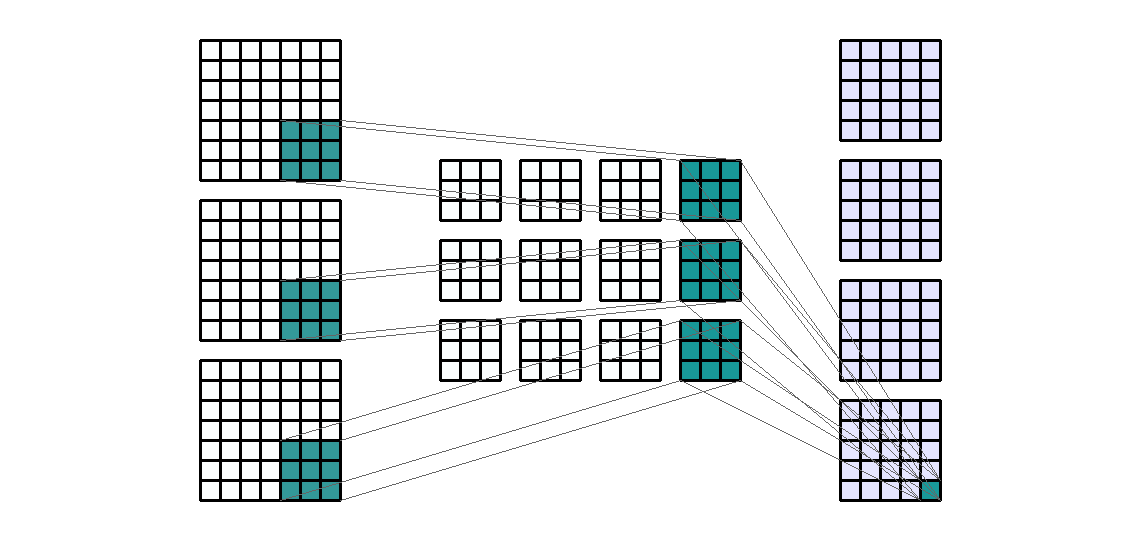
输入形状:(3, 7, 7) — 输出形状:(4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D : (1 , 1) — G : 1
对于 4 个输出通道和 3 个输入通道,每个输出通道是 3 个过滤输入通道的总和。也就是说,卷积层由4*3=12个卷积核组成。我们来计算以下卷积层的可训练参数:$\text{parameters }=C_{out}*C_{in}*K[0]*K[1]+bias=4*3*3*3+4=112$
import torch inputs = torch.randn(32, 3, 28, 28) model = torch.nn.Conv2d(in_channels=3, out_channels=4, kernel_size=(3, 3), stride=(1, 1), padding=0, dilation=1, groups=1, bias=True) # 112个参数 outputs = model((inputs)) print(outputs.shape) # [32, 4, 26, 26]
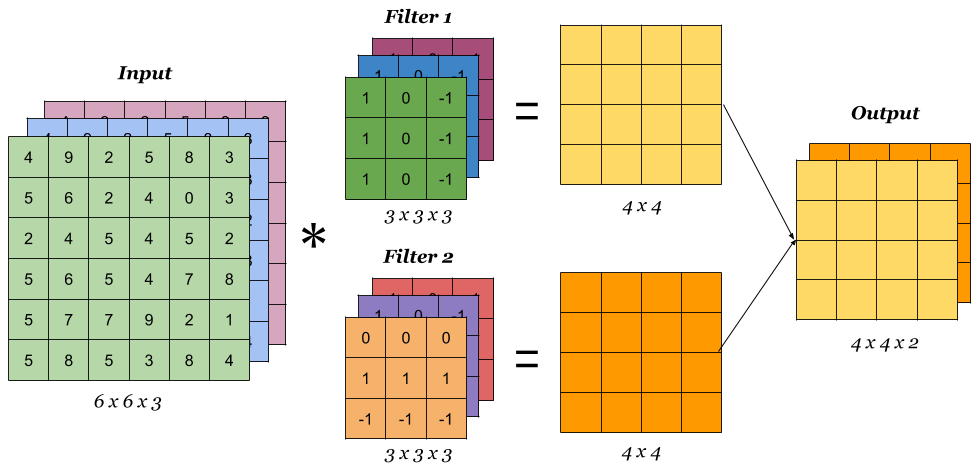
上面的动图虽然展示了卷积过程,但是没有空间立体效果,多滤波器卷积可以参看下图,滤波器的通道数等于输入数据的通道数,滤波器的个数等于输出通道数。
Stride(步幅)
Stride(步幅)定义为卷积核 每次滑动的大小。默认情况下,内核从左到右移动,从上到下 逐像素移动。但这种转变也可以改变。通常用于对输出通道进行下采样。例如,步幅为 (1, 3),过滤器水平方向每次移动3步,垂直方向每次移动1步,这导致输出W_{in}被下采样3倍。
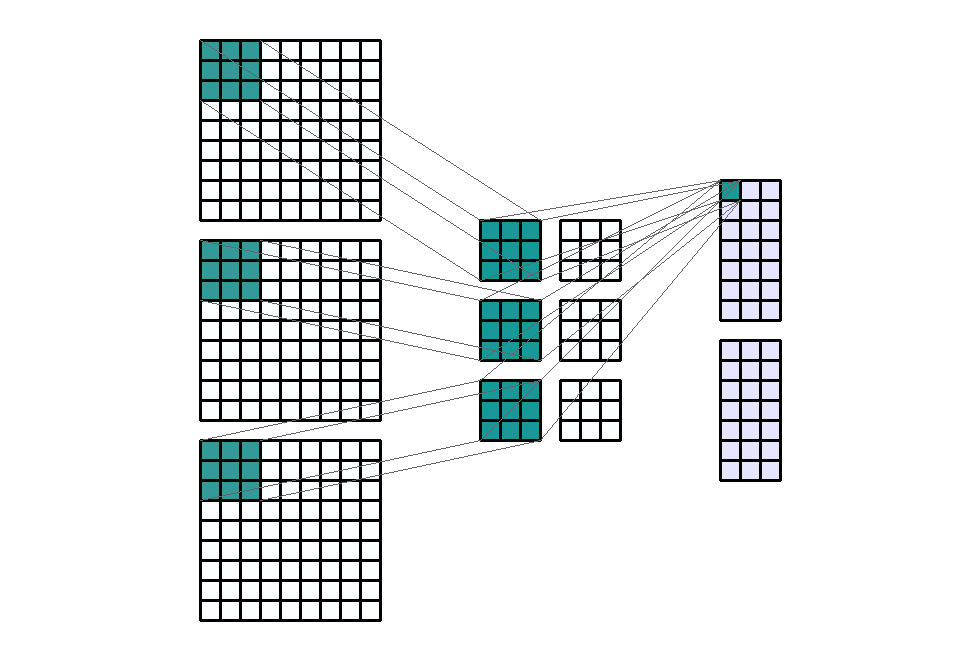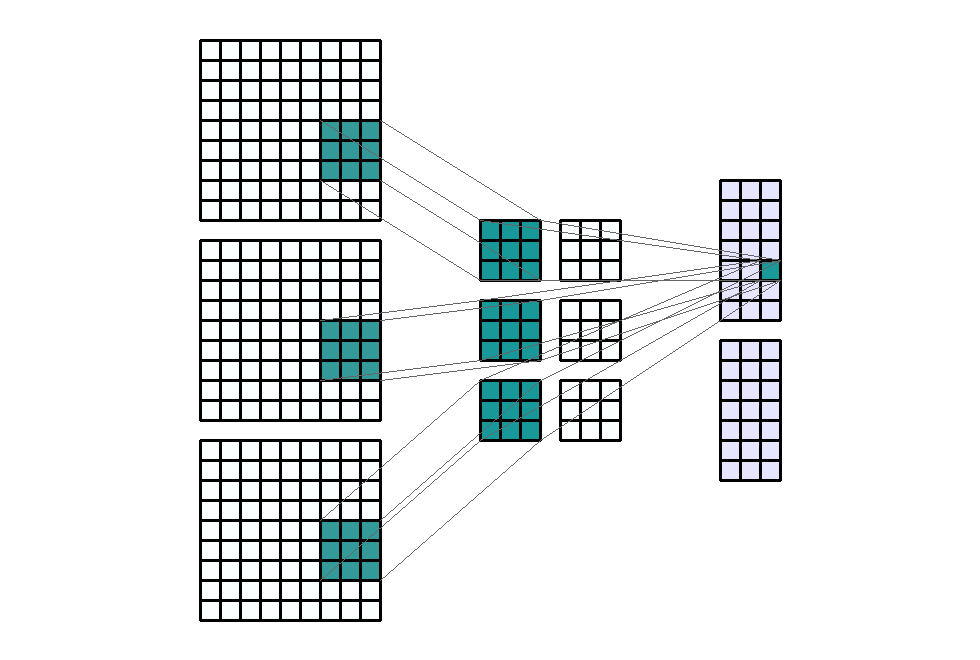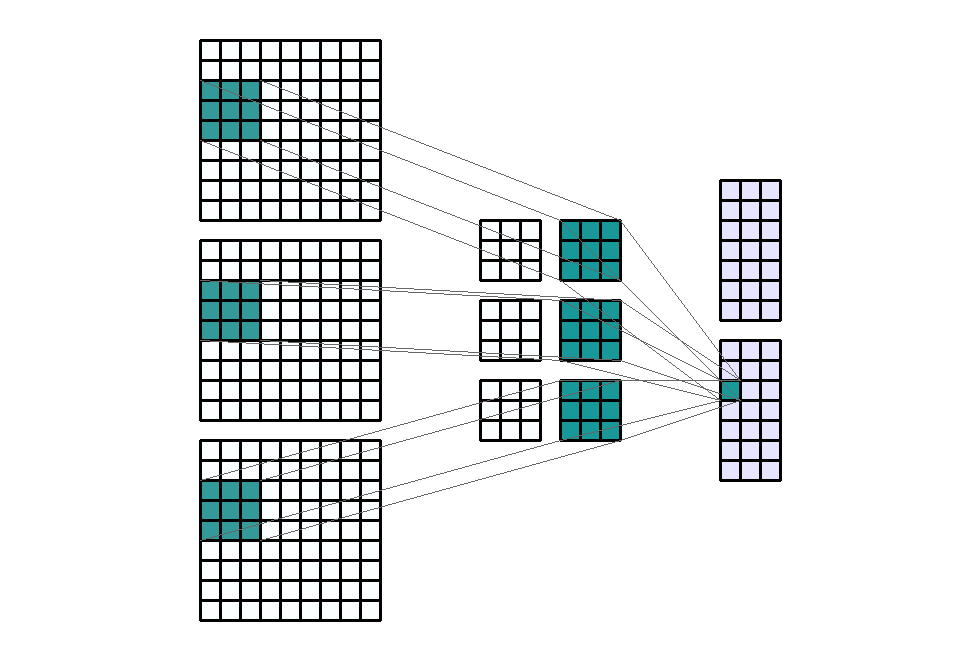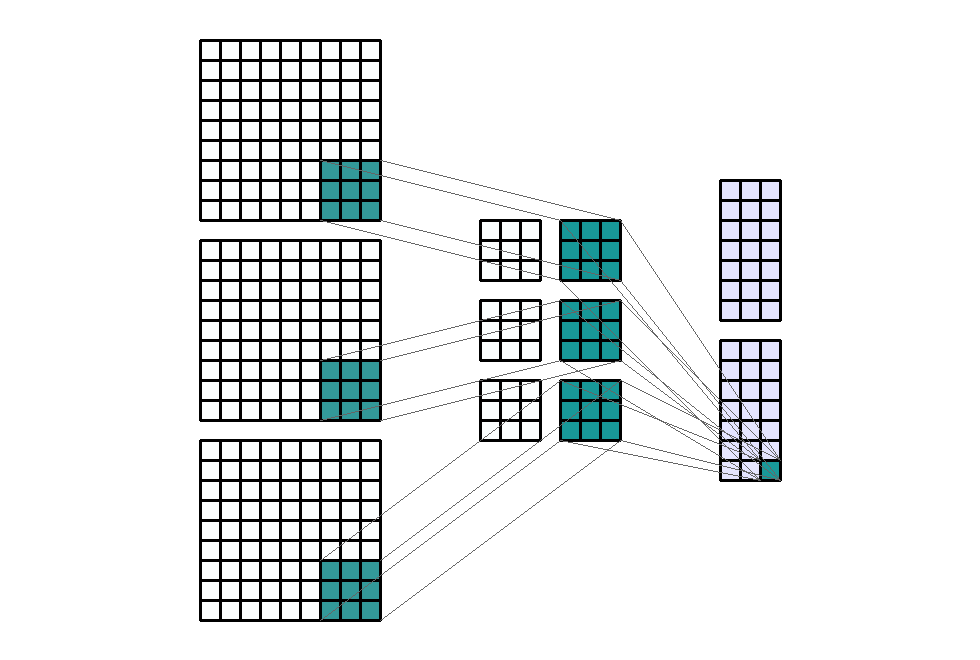
输入形状:(3, 9, 9) — 输出形状:(2, 7, 3) — K : (3, 3) — P : (0, 0) — S : (1, 3) — D : (1 , 1) — G : 1
当Stride比较大的时候,会跳过很多信息,但好处是处理时间大大的缩短。在设计网络的时候,先设置Stride=1,如果工作状况已经很理想,而希望通过加大Stride来获得一些性能的提升或者存储量的减少。那么可以通过适当的调整Stride=2,来获得速度的提升。另外stride对参数的数量没有影响。
import torch inputs = torch.randn(32, 3, 9, 9) model = torch.nn.Conv2d(in_channels=3, out_channels=4, kernel_size=(3, 3), stride=(1, 3), padding=0, dilation=1, groups=1, bias=True) # 112个参数 outputs = model((inputs)) print(outputs.shape) # [32, 4, 7, 3]
Padding(填充)
填充定义了在卷积滤波之前添加到输入通道两侧的像素数。通常,填充像素设置为0。
Padding大概有两种目的
- 保持边界信息。如果不加Padding的话,最边缘的信息其实仅仅被卷积核扫描了一遍,而图片中间的像素点信息被扫描了多遍,在一定程度上就爱你工地了边界上信息的参考程度。
- 保持输出和输入shape一致:如果输入的图片尺寸有差异,可以通过Padding来进行补齐,使得输出和输入的shape一致,以免频繁调整卷积核和其它层的工作模式。
dilation(扩张)
dilation在某种程度上是膨胀卷积核的宽度,默认情况下是1,它对应于卷积核内每个像素之间的偏移量。dilation一定程度上扩大了特征选取的范围,也就是通常人们所说的感受野。
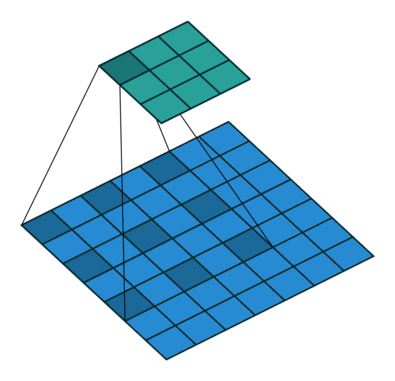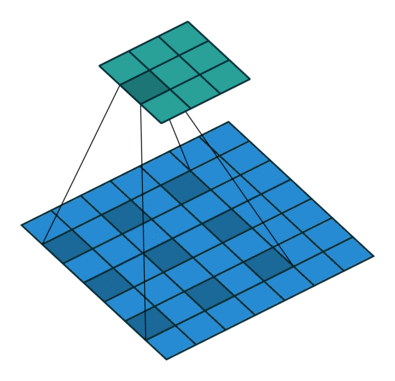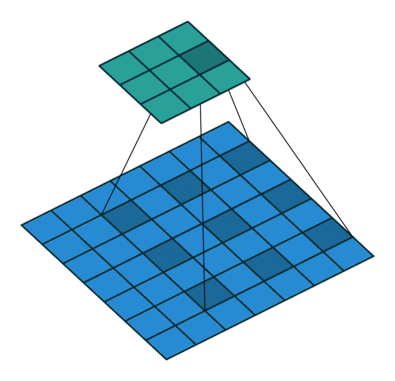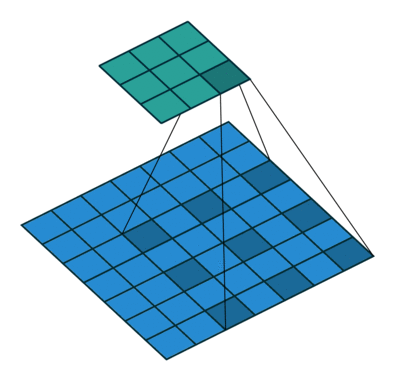
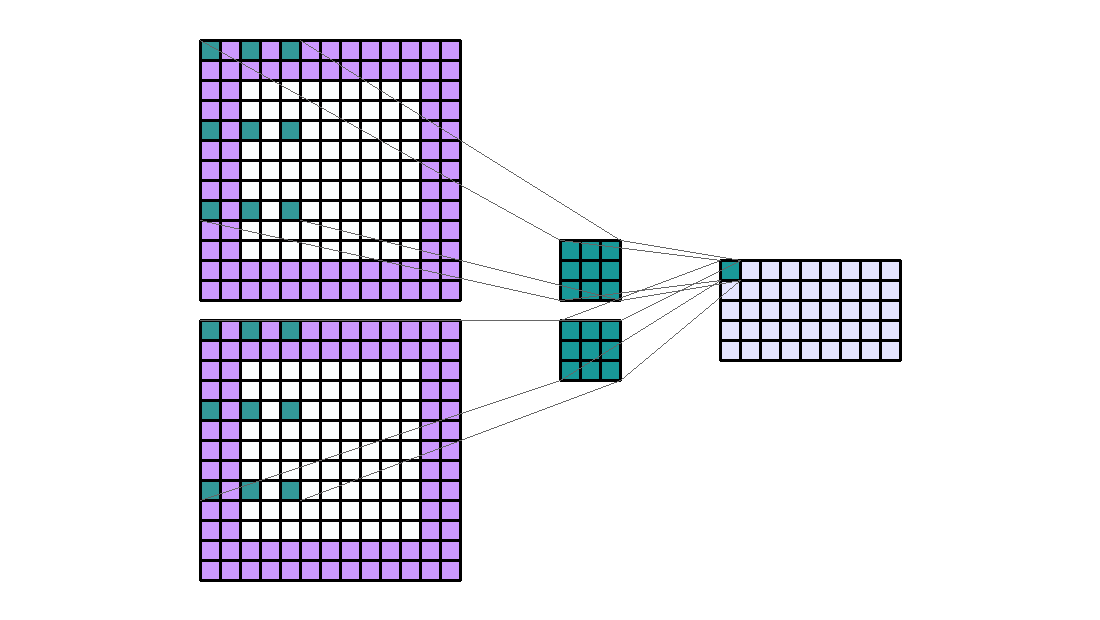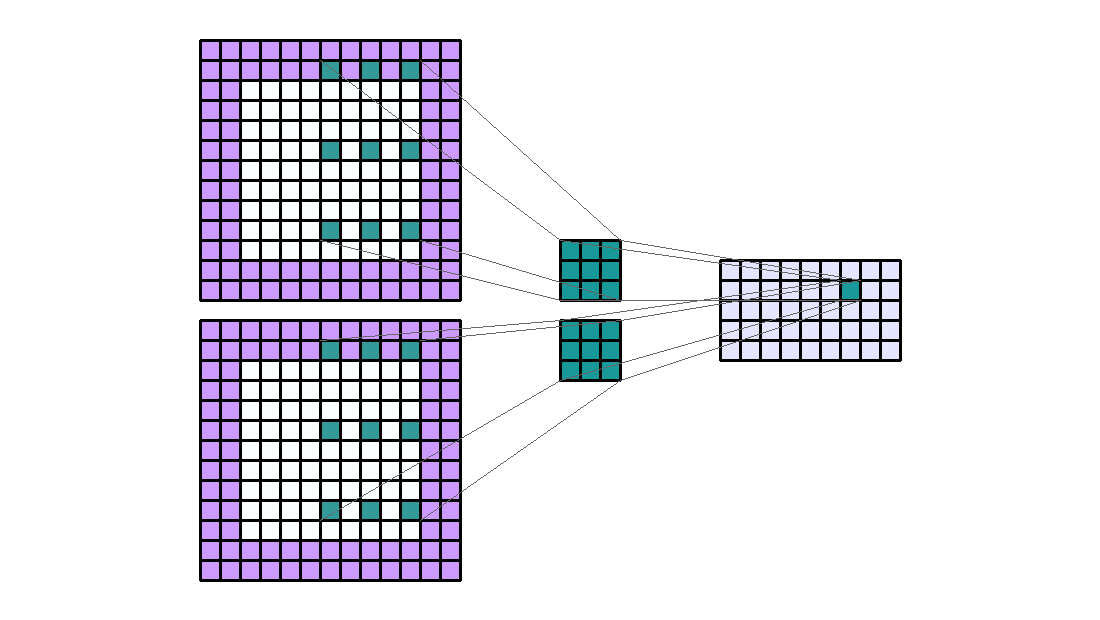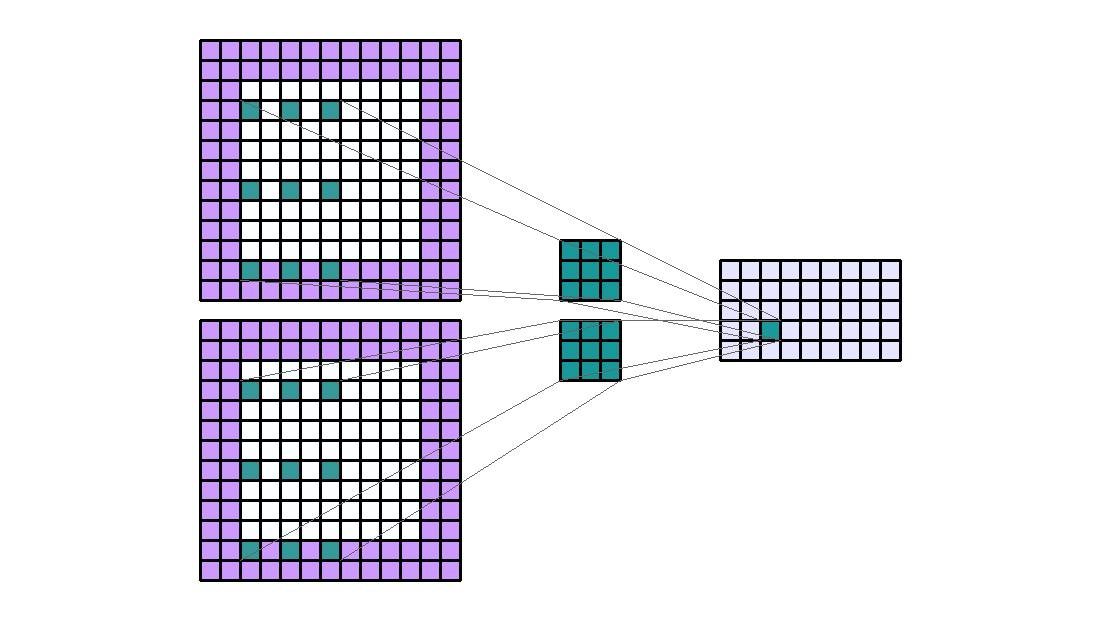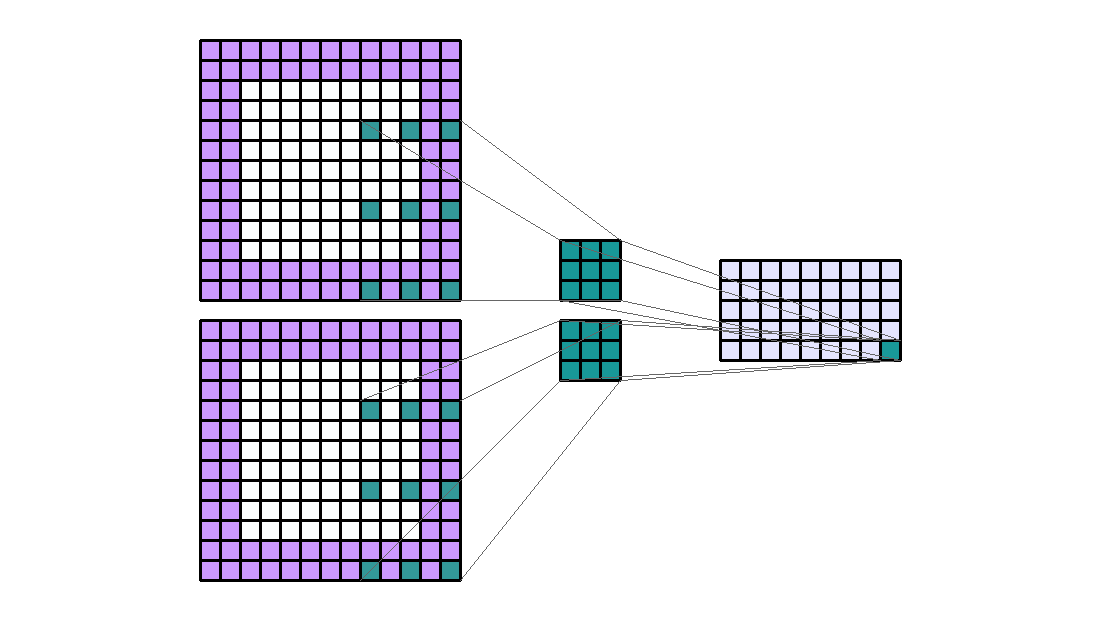
左图:dilation=2的卷积核
右图:输入形状:(2, 7, 7) — 输出形状:(1, 1, 5) — K : (3, 3) — P : (1, 1) — S : (1, 1) — D : (4 , 2) — G : 1
上图原本卷积核shape为(3, 3),dilation为(4,2),那么输入通道上内核的感受野会扩大为 H:(3-1)*4+1=9,W:(3-1)*2+1=5。卷积核的作用范围扩大,参数数量不变,有些被包括的点实际上并未参与运算,因此dilation对参数数量没有影响,对计算时间的影响非常有限。
分组(Groups)
组在特定情况下非常有用。例如,如果我们有几个串联的数据源。当没有必要将它们相互依赖时。输入通道可以单独分组和处理。最后,输出通道在最后连接起来。
如果有 2 个输入通道和 4 个输出通道 2 组。然后这就像将输入通道分成两组(因此每组有 1 个输入通道)并使其通过一个输出通道数量减半的卷积层。然后连接输出通道。
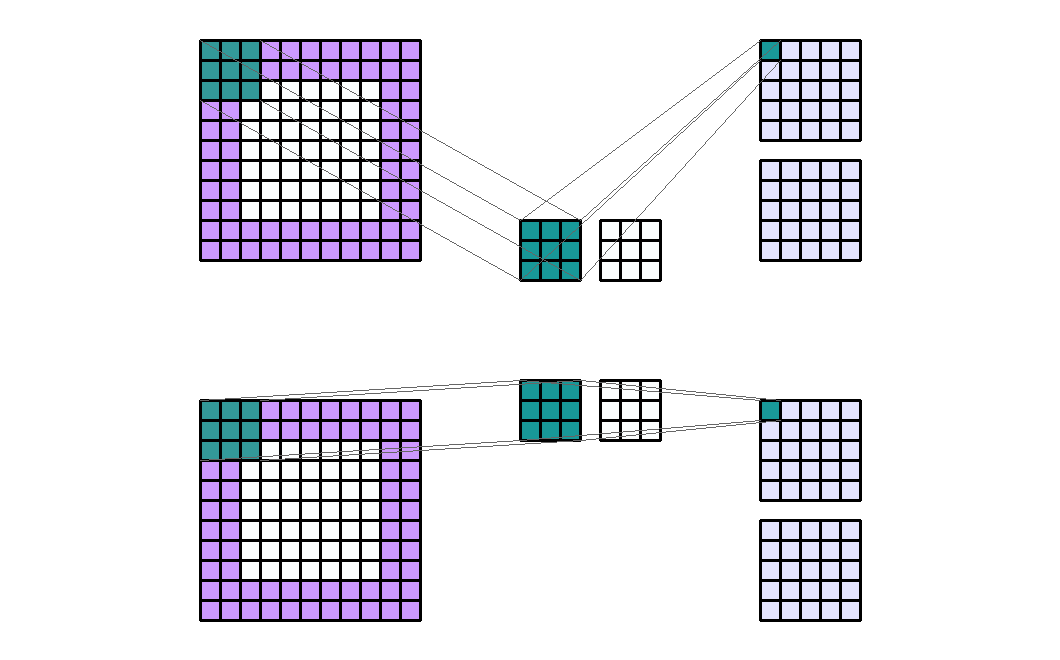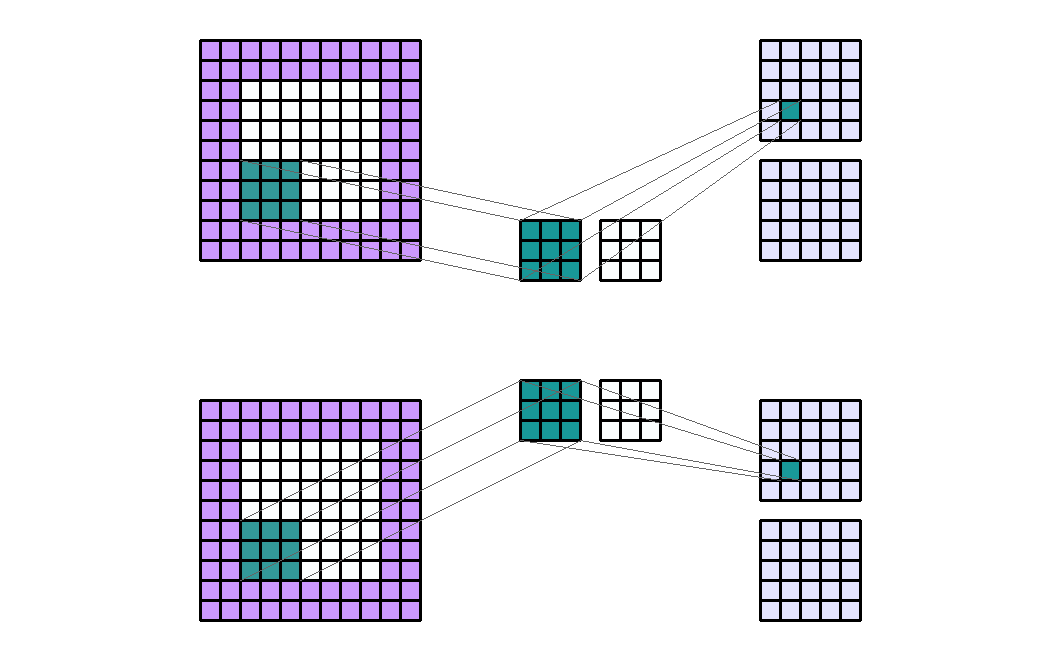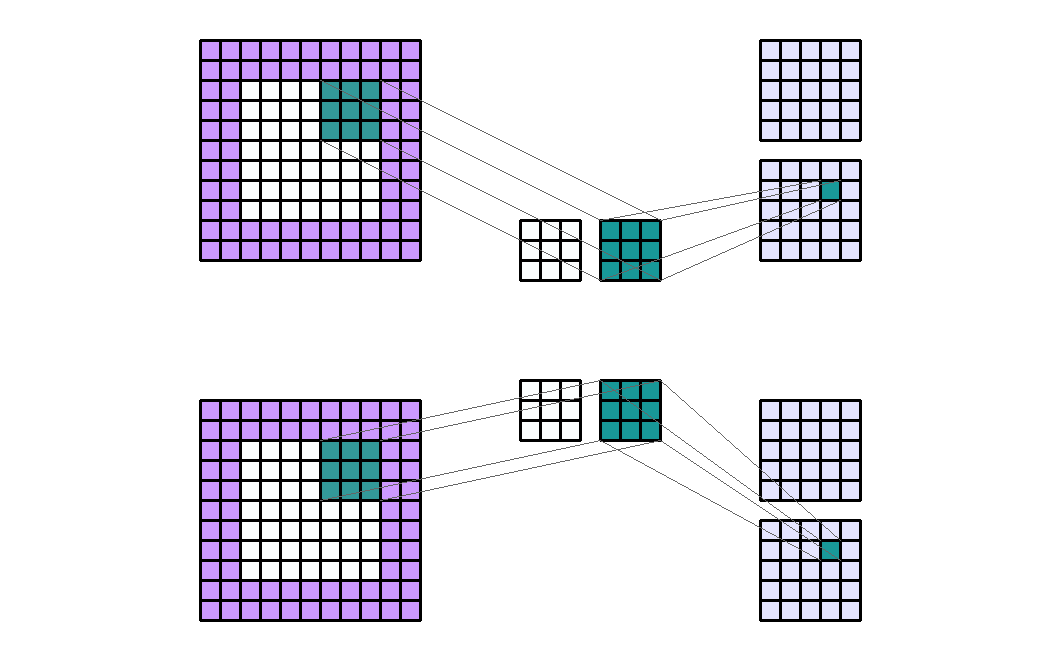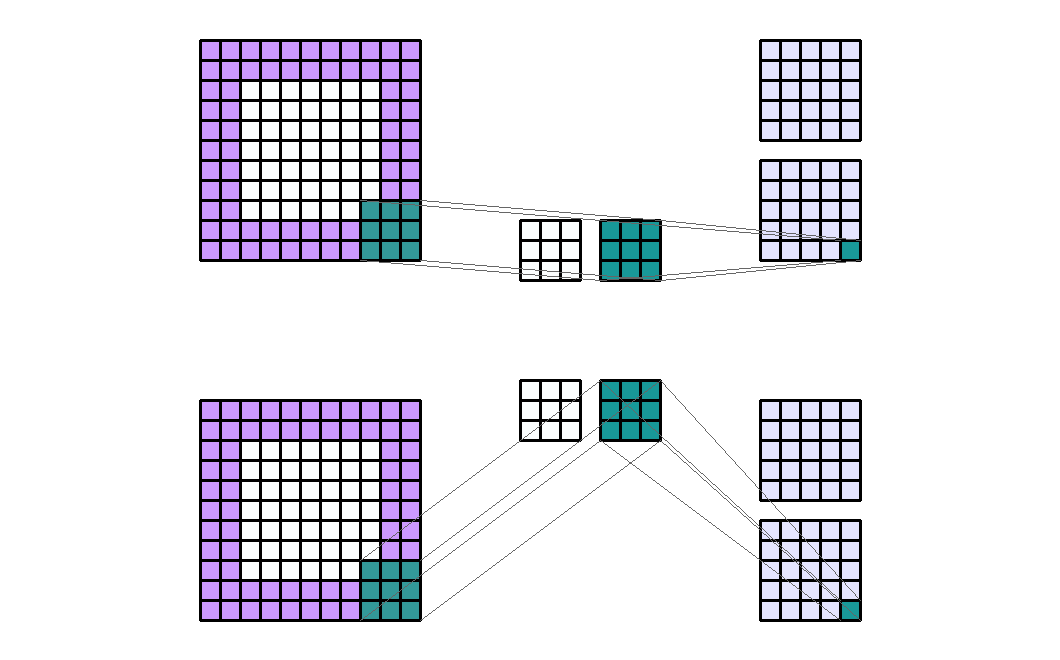
Input Shape : (2, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (2, 2) — S : (2, 2) — D : (1, 1) — G : 2
重要的是要注意组的数量必须完美地除以输入通道的数量和输出通道的数量(公约数)。
因此,group conv参数的数量等于 没有group参数量除以groups。关于 Pytorch 的计算时间,该算法针对组进行了优化,因此应该减少计算时间。但是,还应该考虑到必须与输出通道的组形成和连接的计算时间相加。
import torch inputs = torch.randn(32, 2, 7, 7) model = torch.nn.Conv2d(in_channels=2, out_channels=4, kernel_size=(3, 3), stride=(2, 2), padding=(2,2), dilation=(1,1), groups=2, bias=True) # 40个参数 outputs = model((inputs)) print(outputs.shape) # [32, 4, 5, 5]
池化层
池化层用于减小feature map的大小并加快计算速度,以及使其检测到的一些特征更加稳健。
池化的样本类型是max pooling和avg pooling,但现在 max pooling 更为常见。

池化层有超参数:size( f )、步幅( s )、类型(最大值或平均值)。但它没有参数;梯度下降没有什么可学的
在多通道输入上完成时,池化会减小高度和宽度($H_{out}$和$W_{out}$),但保持通道数不变:
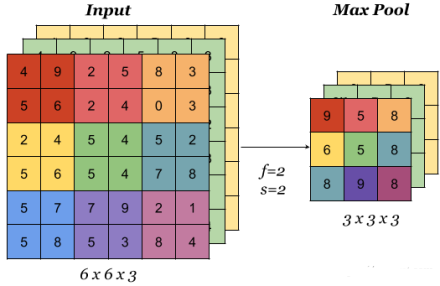
池化层有这么几种功能:
- 它进行了一次特征提取,减小了下一层数据的处理量
- 这个特征提取,能够有更大的可能性进一步获取更为抽象的信息,防止过拟合,也可以说提高了一定的泛化能力。
- 能够对输入的微小变化产生更大的容忍。
One-hot编码 OHE
独热编码(one-hot encoding):使用一个向量的每一个维度来标识一种性质的有无。
$$猫:\begin{pmatrix}1\\ 0\\ 0\\ 0\end{pmatrix}
狗:\begin{pmatrix}0\\ 1\\ 0\\ 0\end{pmatrix}
蛇:\begin{pmatrix}0\\ 0\\ 1\\ 0\end{pmatrix}
猪:\begin{pmatrix}0\\ 0\\ 0\\ 1\end{pmatrix}$$
参考文献
【pytorch文档】torch.nn.Conv2d
【github】卷积神经网络的动画
【github】本文卷积动画
【Medium】Conv2d: Finally Understand What Happens in the Forward Pass
【CS231n】Convolutional Neural Networks (CNNs / ConvNets)
【IndoML】Student Notes: Convolutional Neural Networks (CNN) Introduction
【知乎】从此明白了卷积神经网络(CNN)
然后我有一篇博客专门讲解了如何用tensorlfow和keras框架搭建DNN CNN RNN神经网络实现MNIST手写数字识别模型,地址链接
相关文章
- [Brief. Bioinformatics | 论文简读] 基于知识的BERT:像计算化学家一样提取分子特征的方法
- [KDD 2022 | 论文简读] 面向Top-K推荐的多方面量化强化二值化图表示学习
- [ICML 2022 | 论文简读] 面向图表示学习的结构感知的Transformer
- [Nat. Commun. | 论文简读] 将生物医学数据集成和格式化为 Bioteque 中预先计算的知识图谱嵌入
- [Nature Communication | 论文简读] 将生物医学数据集成和格式化为Bioteque中预先计算的知识图谱嵌入
- [arxiv | 论文简读] CLASSIC: 方面级情感分类任务的持续和对比学习
- 欢常见的Web安全方面问题
- 面试系列-kafka exactly once语义
- 面试系列-kafka消息相关机制
- 面试系列-kafka内部通信协议
- 面试系列-kafka高可用机制
- 面试系列-kafka偏移量提交
- 面试系列-kafka事务控制
- 面试系列-kafka基础组件及其关系
- 面试系列之-rocketmq重试队列和死信队列
- 面试系列之-rocketmq文件数据存储
- 面试系列之-rocketmq长轮询模式
- 面试系列之-rocketmq零拷贝原理
- 面试系列之-rocketmq组件及关系
- 面试系列之-rocketmq消息机制