
【论文笔记】—低照度图像增强—ZeroShot—RUAS网络—2021-CVPR
论文介绍
题目:Retinex-Inspired Unrolling With Cooperative Prior Architecture Search for Low-Light Image Enhancement
DOI:10.1109/CVPR46437.2021.01042
时间:2020年12月10号上传于arxiv
会议:2021-CVPR
机构:大连理工大学
论文网址: https://arxiv.org/abs/2012.05609
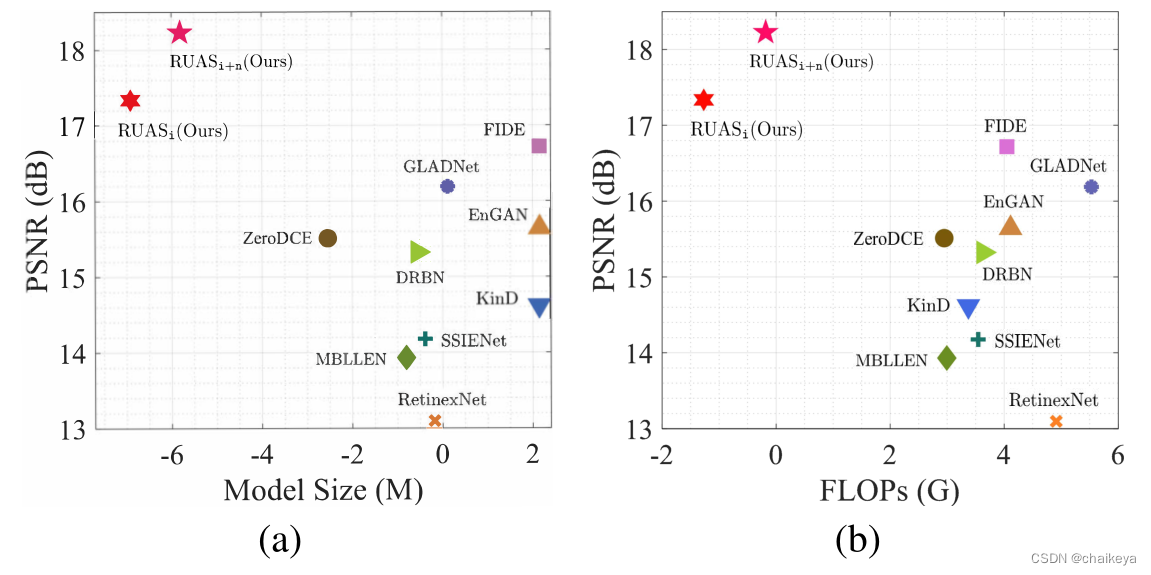
代码网址: https://github.com/dut-media-lab/RUAS下图表示LOL数据集上近些年各经典CNN模型的平均定量性能(PSNR)和模型大小(图a)、FLOPs(图b)的关系。
RUASi只需要非常小的模型大小、浮点计算次数次数和时间。
提出问题
已经建立的深度学习模型大多依赖于重要的体系结构工程,并且承受着很高的计算负担。
解决方案
本文提出了一个新的原则性框架,通过注入弱光图像的知识和搜索轻量级的优先架构,为现实场景中的微光图像构建轻量级但有效的增强网络,命名为RUAS。
首先,设计了基于Retinex规则的优化模型,来描述微光图像固有的曝光不足结构。
然后,通过展开相应的优化过程,建立增强网络的整体传播结构。
最后,设计了一种合作的无参考双层学习策略,用于合作搜索先验结构,从紧凑的搜索空间中发现特定的体系结构,以获得照明图和所需图像。
创新点
1、零样本,不需要训练。
2、使用了结构搜索的方法,得到一个高效的网络结构。
RUAS网络结构
首先,通过展开Retinex-inspired 模型的优化过程来建立增强网络。
然后,引入了一个基于蒸馏池的先验模块搜索空间。
最后,提出了一种合作的双层搜索策略,以发现所需的光照估计和噪声去除架构。
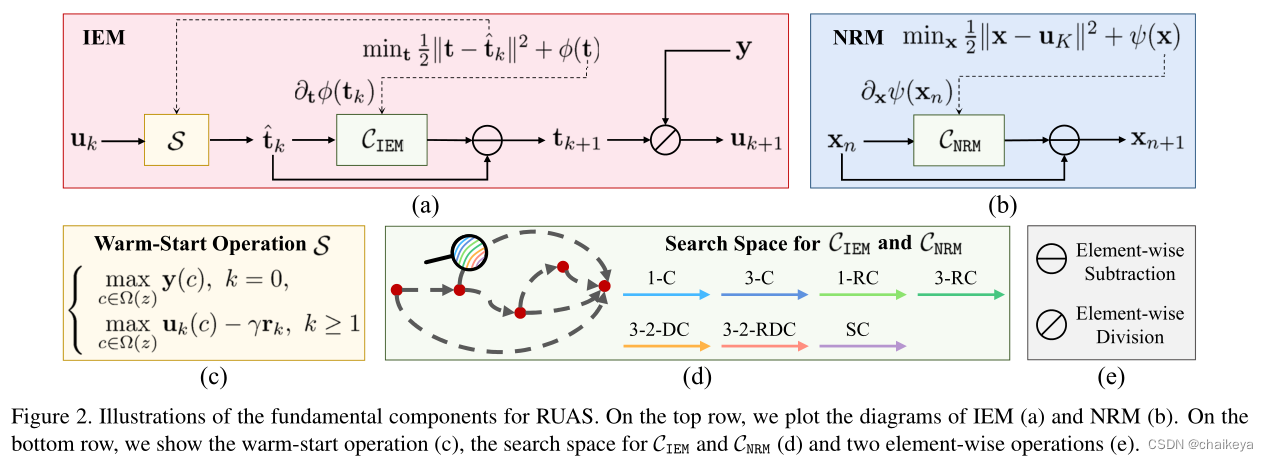
(a)照明估计模块IEM——用于估计照明映射 t
(b)噪声去除模块NRM——用于微光场景中抑制噪声,NRM是基于IRM的输出定义的。
(c)热启动操作
(d)CIEM和CNRM的搜索空间
(e)element-wise subtraction—逐元素减法、element-wise division—逐元素除法
实验原理
1、Retinex-Inspired 优化展开
RUAS增强网络基于Retinex规则:
![]()
y-捕获图像、x-期望的恢复图像、t-光照图像、⊗ 按元素的乘法
Retinex原理:S = R ⊗ L (S-捕获图像 R-反射图像 L-光照图像)
核心:从S图像中估测L分量,并去除L分量,得到原始反射分量R 。
1.1 照明估计模块IEM
1、定义一个中间图像u。在IEM的第k阶段,首先估计(热启动)初始照明图^tk:
![]()
![]()
Ω(z) 是以像素z为中心的区域,,c是该区域内的位置索引(对于三个颜色通道)。残差rk:rk = uk – y (惩罚参数0 < γ ≤ 1)
原理:照明至少是某个位置的最大值,可以用来处理非均匀照明。
引入残差,是为了在传播过程中自适应地抑制
的一些过度曝光像素。
2、进一步优化^tk ,其中 φ(·)表示 t 的正则化项:
![]()
不同于直接和前一项作用的经典迭代优化方法,本文只需一步:
![]()
在这里,将 CIEM(tk)写为 ∂tφ(tk) 的参数化(即 CNN 架构)。将每次迭代参数化为单独的 CNN 的选择提供了极大的灵活性。
^tk的优化受LIME的启发,[9] LIME: Low-light image enhancement via illumination map estimation. paper
3、输出uk:
![]()
tk是最后阶段的估计照度图, ⊘表示按元素除法。
1.2 噪声去除模块NRM
动机:抑制现实世界低光场景中的噪声,不能简单地通过预/后处理去除曝光不足图像中的强噪声。
定义了一个正则化模型:
![]()
其中ψ表示x上的先验正则化。采用IEM中使用的相同展开策略:
![]()
在这里,将 CNRM(xn) 写为 ∂xψ(xn) 的参数化(即 CNN 架构),并将 NRM(具有 N 个阶段)的输出并行表示为 xN。
2、协同架构搜索
作用:用于合作发现IEM和NRM的体系结构。
2.1 为弱光先验提供紧凑的搜索空间
首先定义弱光先验模块(CIEM和CNRM)的搜索空间。通过使用特征蒸馏技术[17],我们将搜索空间定义为一个蒸馏单元,它是一个有向无环图,有五个节点,每个节点连接到下一个和最后一个节点(如图2(d))。与最后一个节点的连接只是实现了特征信息的提取。
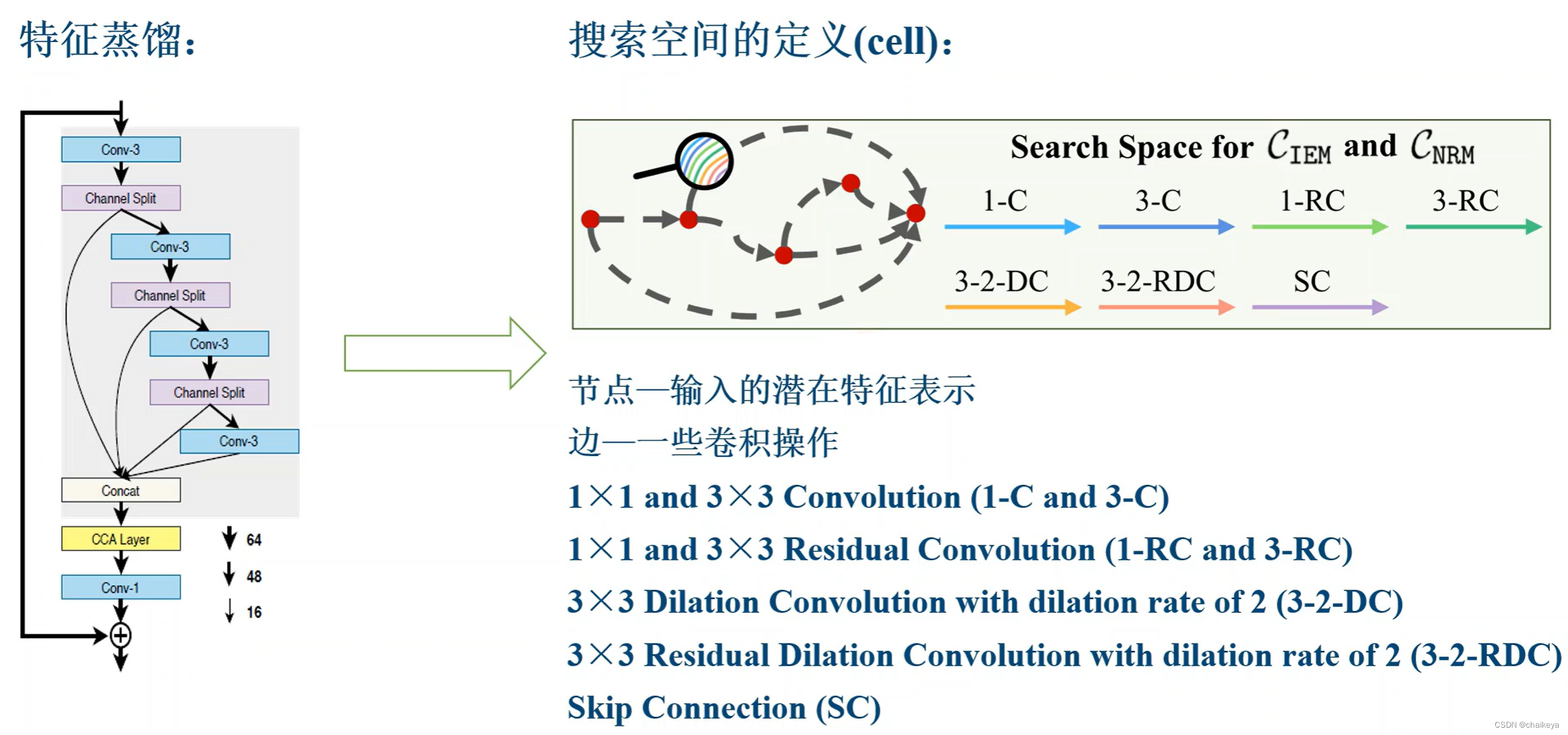
知识蒸馏
2014年Hinton等人发表的《Distilling the Knowledge in a Neural Network》首次提出了蒸馏学习的概念。蒸馏学习即教师模型(大参数,深网络)蒸馏出一个学生模型(小参数,浅网络),使学生模型具有接近教师模型的效果,以达到模型压缩的目的。
深度学习中的知识蒸馏技术(上)、深度学习中的知识蒸馏技术(下)
残差卷积
深度残差网络ResNet:【论文笔记】—深度残差网络—ResNet—2015-CVPR_chaikeya的博客-CSDN博客
空洞卷积
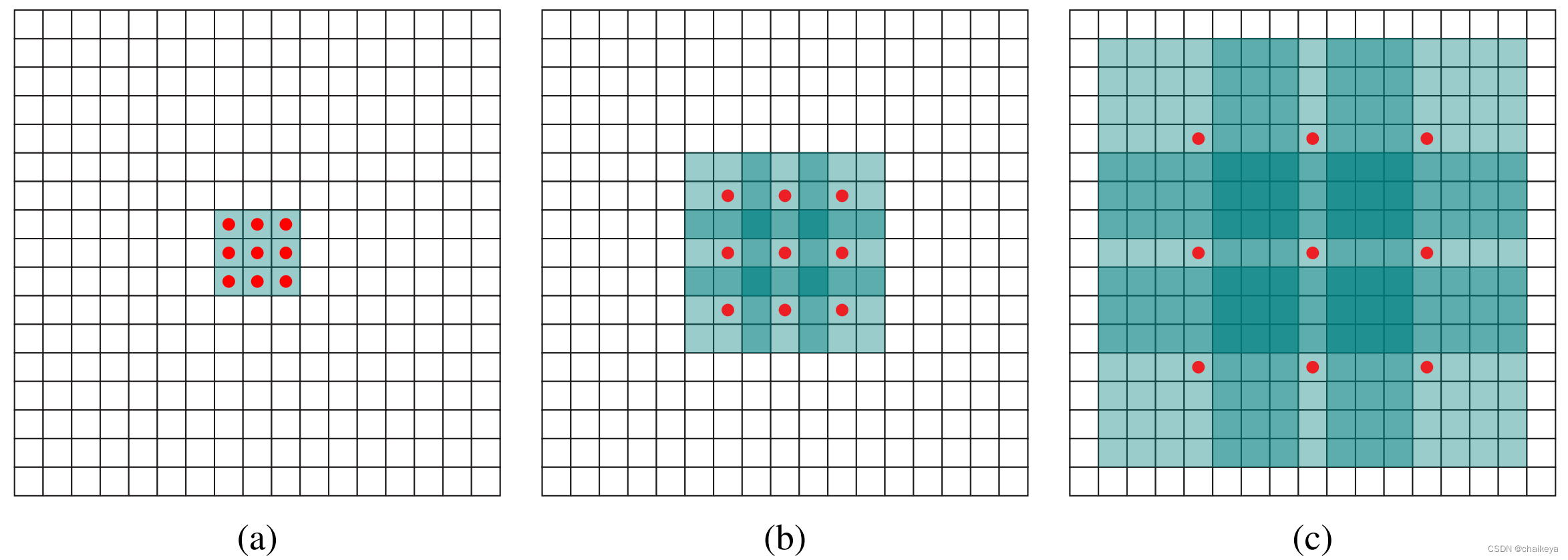
Dilated Convolution(空洞卷积/膨胀卷积)是在标准的 convolution map 里注入空洞(在kernel各个像素点之间加入0值像素点),以此来扩大感受野。膨胀卷积与普通的卷积相比:除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,指的是卷积核的点的间隔数量,主要用来表示膨胀的大小。在普通卷积中,可以认为它的dilated rate = 1。
(a)扩张率为1的3×3卷积核。
(b)扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,而且仅需要9个参数。
(c)扩张率为4的3×3卷积核.
注意:空洞的地方填充为0.
Dilated Convolution 论文出处:《MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS》paper

通过采用differentiable NAS[16,39,15] 中使用的连续松弛技术,我们引入向量化形式 α = {αt, αn} 来分别对 CIEM 和 CNRM 的搜索空间(表示为 A)中的架构进行编码。 用 ω = {ωt, ωn} 表示与架构 α 相关的权重参数。搜索任务简化为在所有混合运算中联合学习α和ω。
自动化机器学习(AutoML) 领域一个重要的方向就是神经网络结构搜索。目前比较主要的有两个分支:基于强化学习的方法(比如 NAS)和基于可微分神经网络结构搜索的方法(比如 DARTS)。从效果上来看,前者效果上较好;但是从计算资源上来看,前者一般需要较大规模的计算资源。
Neural Architecture Search基本遵循这样一个循环:首先,基于一些策略规则创造简单的网络,然后对它训练并在一些验证集上进行测试,最后根据网络性能的反馈来优化这些策略规则,基于这些优化后的策略来对网络不断进行迭代更新。
1、NAS
2017年《Neural Architecture Search with Reinforcement Learning》提出,NAS 的目标是找到一个合适的神经网络结构,用于在某个或者某类任务上有更好的泛化性能。如下图所示,这篇文章使用了一个 RNN 的控制器,用该控制器采样得到某一个神经网络结构 A,在该神经网络结构下训练数据并且得到相应的验证集上的准确率 R,使用该准确率来表征本次搜索得到的神经网络结构的好坏,进而将此作为信号来训练 RNN 控制器。大致结构如下图所示。
2、DARTS
NAS方法搜索空间都是离散的,而可微分方法将搜索空间松弛化使其变成连续的,则可以使用梯度的方法来解决。
《DARTS+: Improved Differentiable Architecture Search with Early Stopping》论文笔记
《DARTS: Differentiable Architecture Search》论文笔记

2.2 可微分合作搜索
传统:基于梯度的NAS方法——只能以端到端的方式学习ω和α,完全忽略了重要的光增强因素(照明和噪声)
本文:我们解决此问题的主要思想是发现能够在现实世界的嘈杂场景中正确揭示曝光不足图像的弱光先验信息的体系结构。
通过合作搜索IEM和NRM的体系结构。
将这两个模块的搜索过程描述为一个合作博弈,旨在解决以下关于αt(IEM)和αn(NRM)的模型:
![]()
验证数据集上的合作损失Lval = IEM损失 + β NRM损失 ,即:
![]()
其中, 和
分别表示IEM和NRM的损失,β ≥ 0是一个权衡参数。由于NRM是基于IEM的输出定义的(参见图2),因此在这里我们还应该考虑αt作为Lval^n中αn的参数。
事实上,通过类比生成性对抗性学习任务[7],应该理解等式(4)中的优化问题实际上考虑的是合作(“min-min”),而不是对抗性(“min-max”)目标。
[7]Generative Adversarial Nets. 【论文笔记】—生成对抗网络—GAN—2014-NIPS_chaikeya的博客-CSDN博客
至于(和
),我们假设它们只与体系结构αt(和αn)相关, 可通过最小化以下模型获得:
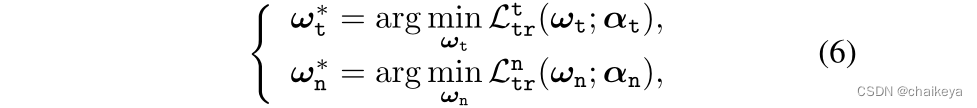
其中,和
分别是IEM和NRM的训练损失。
因此,我们的搜索策略意味着一个两层优化问题,等式(4)和等式(6)分别作为上层和下层子问题。此外,在搜索过程中,等式(4)中的上层子问题应进一步分离为两个合作任务。
2.3 无参考双层学习
首先根据一系列无参考损失确定训练和验证目标。
对于IEM,定义了一个损失
![]()
在训练和验证数据集上分别为和
,其中,第一项是保真度,第二项中RTV(·)表示相对总变化项[38](参数ηt>0)。
这种损失鼓励IEM输出照明,可以同时保持整体结构和平滑纹理细节。
对于NRM,引入了类似的损耗
![]()
在训练和验证数据集上分别为和
,其中我们使用标准总变化TV(·)作为正则化[25](参数ηn>0)。
整个搜索过程总结: IEM和NRM是交替同时搜索的。
也就是说,为IEM(步骤4-7)更新αt(使用当前的αn),为NRM(步骤9-12)更新αn(基于更新的αt)。对于每个模块,仅采用广泛使用的一步有限差分技术[5]来近似计算上层变量的梯度(步骤5和10)。

有限差分:利用网格节点逼近导数,并建立有限个未知数的代数方程组来求解各个网格上节点的值。
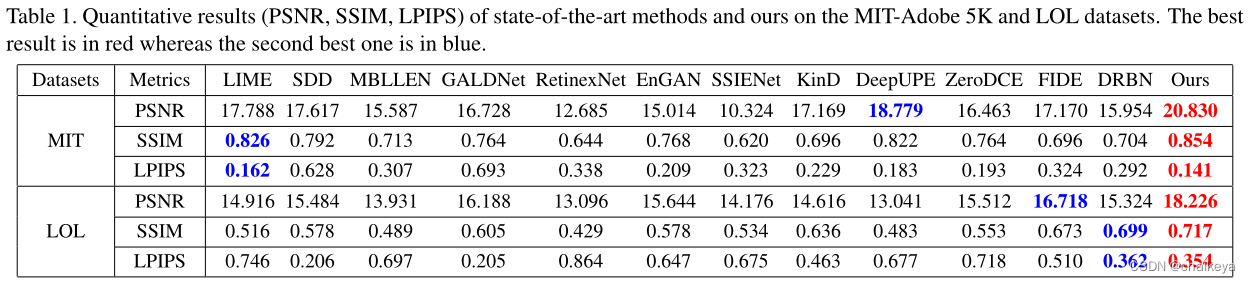
定量分析
表1定量结果评价(PSNR、SSIM、LPIPS)。No.1红色,No.2蓝色。
其中LOL数据集包含阻碍增强的敏感噪声。
评价指标
- 峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR):值越大,就代表失真越少。
- 结构相似度指数 (Structural Similarity Index, SSIM):范围为0到1。当两张图像一模一样时,SSIM的值等于1。
- 学习感知图像块相似度 (Learned Perceptual Image Patch Similarity, LPIPS): 值越低表示两张图像越相似。
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS):也称为“感知损失”(perceptual loss),用于度量两张图像之间的差别。来源于CVPR2018《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》,该度量标准学习生成图像到Ground Truth的反向映射强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPIPS 比传统方法(比如L2/PSNR, SSIM, FSIM)更符合人类的感知情况。LPIPS的值越低表示两张图像越相似,反之,则差异越大。
d为 x0与x之间的距离。从L层提取特征堆(feature stack)并在通道维度中进行单位规格化(unit-normalize)。利用向量WL 来放缩激活通道数,最终计算L2距离。最后在空间上平均,在通道上求和。
————————————————
版权声明:本文为CSDN博主「江南酷哥lazy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43466026/article/details/119898304

数据集
【LOL】:包含低光/正常光图像对的低光数据集 2018

【MIT-Adobe FiveK】:使用输入/输出图像对数据库学习摄影全局色调调整(具有约4%的低光图像)2011

定性分析
图3 DarkFace数据集上展示了黑暗面数据集上的三组视觉比较[41]。
虽然有些方法能够成功地增强亮度,但它们无法恢复清晰的图像纹理。

Dark Face(低光照条件下的人脸检测数据集):DARK FACE: Face Detection in Low Light Condition
DARK FACE数据集提供了6,000张在夜间,在教学楼,街道,桥梁,立交桥,公园等拍摄的真实世界低光图像,所有这些都标有人脸的边界框,作为主要的训练和/或验证集。我们还提供从相同设置收集的 9,000 张未标记的低光图像。此外,我们还提供了一组独特的789对低光/正常光图像,这些图像是在可控的真实照明条件下捕获的(但不必要地包含人脸),这些图像可以用作参与者离散化时训练数据的一部分。将有一个由4,000张低光图像组成的保持测试集,并带有人脸边界框的注释。
图4 LOL数据集上所有比较的方法都没有呈现出生动真实的颜色。
KinD和DRBN确实消除了噪声,但引入了一些未知的伪影。
本文RUAS呈现了生动的颜色,并消除了不必要的噪音。

图5 ExtremelyDarkFace数据集上一些深层网络确实改善了亮度,但许多不利的人工制品变得明显可见。
FIDE和DRBN甚至破坏了颜色系统,例如外套应该是红色的。
本文RUAS改善了亮度,在细节恢复和噪声消除方面都有很大优势。

验证内存和计算效率
表2 和一些最近提出的基于CNN的方法比较模型大小、触发器和运行时间。
选取LOL数据集中的100个大小为600×400的测试图像。No.1红色,No.2蓝色。
RUASi+n是带有噪音消除模块的完整版本。尽管其耗时略高于EnGAN,但这是因为EnGAN忽略了引入显式噪声消除模块。

下图表示LOL数据集上最先进模型的平均定量性能(PSNR)、模型大小(图a)、FLOPs(图b)。
结论:RUASi只需要非常小的模型大小、浮点计算次数和时间。
一、FLOPS
FLOPS:全称:FLoating point Operations Per Second的缩写,即每秒浮点运算次数,或表示为计算速度。是一个衡量硬件性能的指标。通俗点讲 显卡算力,对应英伟达官网的那些:GPU算力排行榜。二、FLOPs
FLOPs:FLoating point OPerationS 即 浮点计算次数,包含乘法和加法,只和模型有关,可以用来衡量其复杂度。多提一嘴,论文里面的FLOPs有的计算也并不明确,包括很多 Github 开源代码里面采用的 MACs,也就是考虑一次乘+加法运算为一次 MAC,粗略换算的话:FLOPs = 2 × MAC。建议发表的论文还是按照 FLOPs 来给出,因为我看的大部分文章都是用的这个,而不是 MACs。
————————————————
版权声明:本文为CSDN博主「乄洛尘」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38929105/article/details/123847385
消融实验
图6 消融研究不同热启动策略的效果。
子图(b)-(d)不同设置的增强结果和相应的估计照明图。
(c)引入w/o剩余校正的更新策略确实提供了正的过度曝光抑制。
(d)引入残余校正机制,暴露更舒适(灯罩)
结论:本论文设计的热启动策略确实抑制了传播过程中的过度曝光。

图7 噪声场景下NRM对微光图像贡献的消融研究。
在执行RUASi后,图像细节得到了增强。然而,也出现了可见的噪声,对图像质量造成了有害的损害。通过引入NRM,本文的 RUASi+n成功地去除了不需要的噪声,从而提高了视觉质量和数值分数。
结论:该实验充分验证了在一些复杂的现实场景中引入NRM的必要性。

图8 在MIT Adobe 5K数据集上使用不同的启发式设计架构分析性能。
结论:本论文的搜索架构实现了最高的峰值信噪比(PSNR)和更少的推理时间。
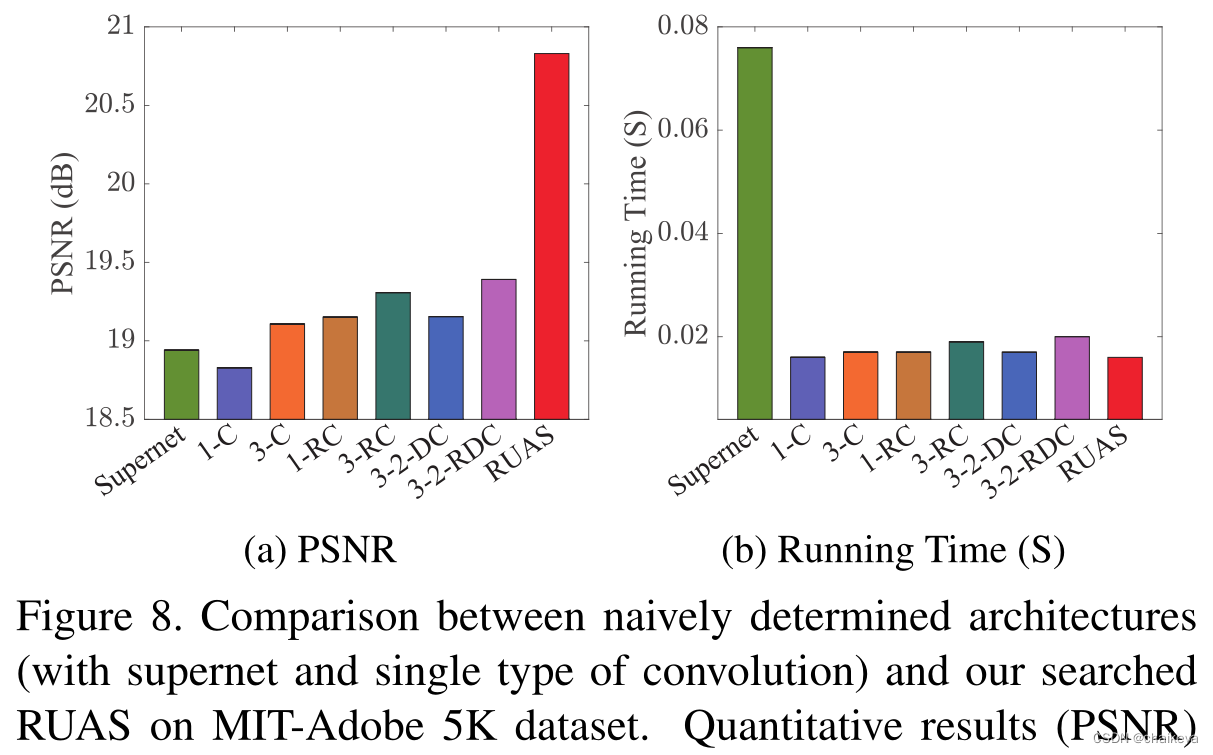
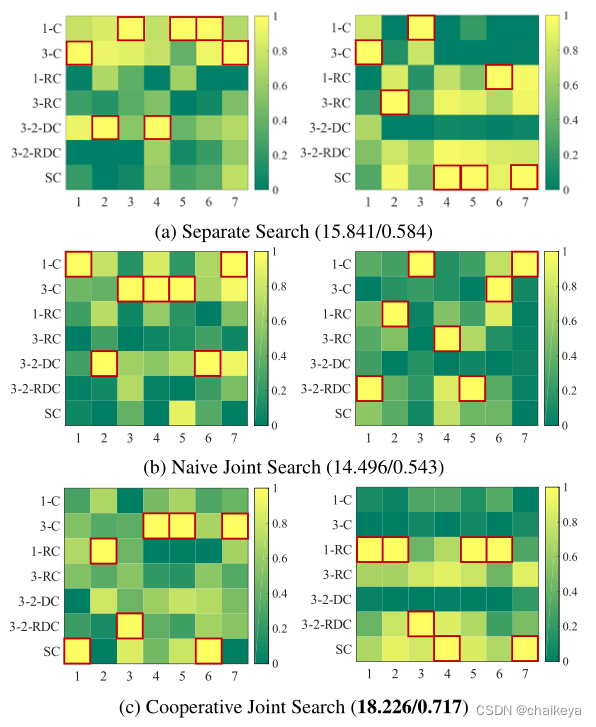
图9 对不同的搜索策略进行了评估。
(a)单独的搜索策略——逐个搜索这两个部分。在搜索NRM时,IEM的搜索过程已经结束。
(b)简单的联合搜索——将IEM和NRM视为整个架构的一部分,只需搜索一次所有架构。
(c)本文的搜索策略——将光照估计和去噪连接起来,以实现有价值的合作。
结论:本文搜索到的NRM包含更多的剩余卷积和跳连接。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合