
【基于熵权-模糊综合评价法】《基于熵权-模糊综合评价法的施工项目风险评价研究》论文笔记(内附MATLAB代码)
原文链接:基于熵权-模糊综合评价法的施工项目风险评价研究 - 中国知网 (cnki.net)
【基于熵权-模糊综合评价法】《基于熵权-模糊综合评价法的施工项目风险评价研究》论文笔记(内附MATLAB代码)
文章目录
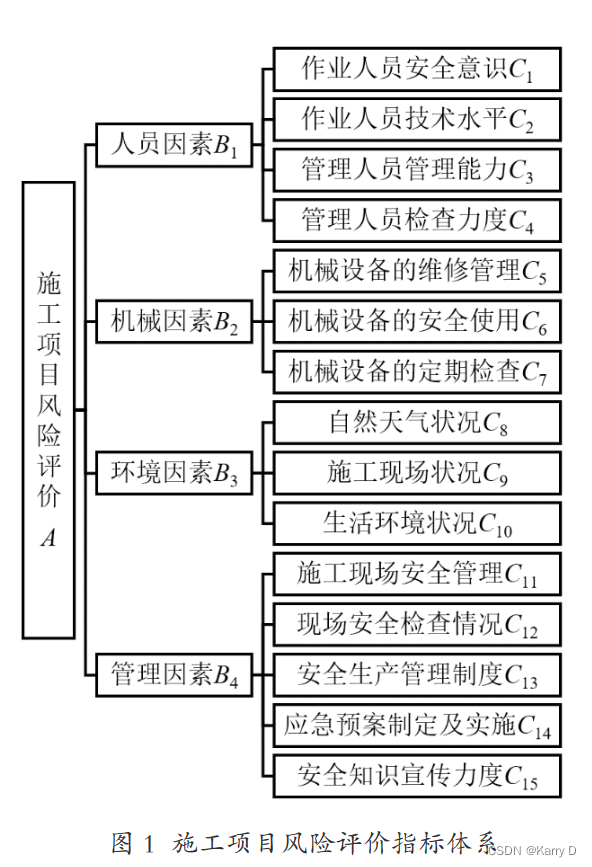
1.施工项目风险评价指标体系
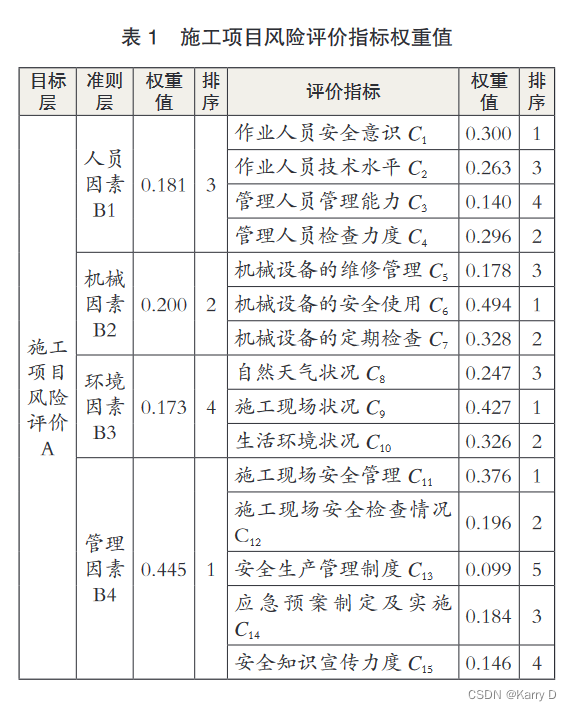
通过查询评价体系相关文献 [6],结合现场实际调研情况,本文从人员因素、机械因素、环境因素、管理因素 4 个角度确定一级指标,确定作业人员安全意识、作业人员技术水平、管理人员管理能力、管理人员检查力度等 15 个方面为二级指标, 从而构建出该施工项目的风险评价指标体系,如图 1 所示。
2.构建风险评价模型
本文施工项目风险评价主要由熵权法和模糊综合评价法两部分组成。熵权法采用邀请建筑行业内的专家来对评价对象指标进行打分,从而来计算各指标因素的权重值;模糊综合评价法的主要步骤是确定权重的向量、建立评价集、进而得到隶属度矩阵,从而进行模糊计算。最终,将上述二者相结合,根据最大隶属度的原则,综合分析得到该施工项目的风险评价等级。
3.实例分析
为验证熵权 - 模糊综合法在评价实际施工项目的普适性与可操作性,选取某学生公寓施工项目为研究对象,依据上述施工项目风险评价指标体系, 评价出该施工项目的安全等级。
3.1 工程概况
某学生公寓施工项目为钢筋混凝土结构,建筑面积共 23411.65m2,建筑总高 28m,地上 7 层以及地下 1 层,施工人员、管理人员人数较多,施工项目现场由施工区及生活区组成,大型设备较多,门口设有安全通道及门禁设备,根据施工现场实际情况确定评价体系中的“人员因素”“机械因素”“环境因素”以及“管理因素”。
3.2 计算评价指标权重
以“人员因素”为例,计算评价指标权重 如下:
(1)构造评价矩阵
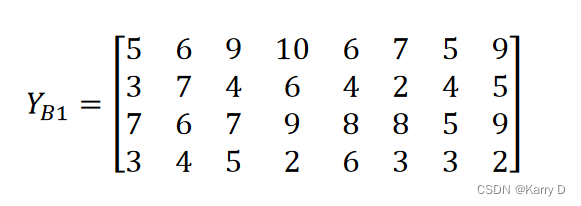
(2)评价矩阵归一化处理

(3)计算指标信息熵值
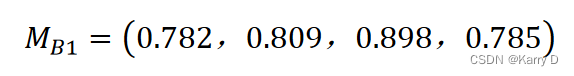
(4)计算各指标权重
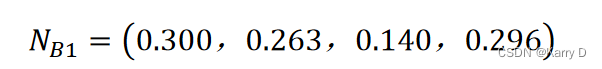
3.3 类比得出施工项目风险评价指标权重值
4.代码实现
%熵权法 R矩阵替换后可使用
R=[5 6 9 10 6 7 5 9;3 7 4 6 4 2 4 5;7 6 7 9 8 8 5 9;3 4 5 2 6 3 3 2];
R=R';
[rows,cols]=size(R); % 输入矩阵的大小,rows为对象个数,cols为指标个数
k=1/log(rows); % 求k
Rmin = min(R);
Rmax = max(R);
A = max(R) - min(R);
y = R - repmat(Rmin,rows,1);
for j = 1 : size(y,2)
y(:,j) = y(:,j)/A(j);
end
%2 求Y(i,j) %归一化处理
S = sum(y,1);
Y = zeros(rows,cols);
for i = 1 : size(Y,2)
Y(:,i) = y(:,i)/S(i);
end
%3
lnYij=zeros(rows,cols); % 初始化lnYij
% 计算lnYij
for i=1:rows
for j=1:cols
if Y(i,j)==0;
lnYij(i,j)=0;
else
lnYij(i,j)=log(Y(i,j));
end
end
end
ej=-k*(sum(Y.*lnYij,1)); % 计算熵值Hj
%4
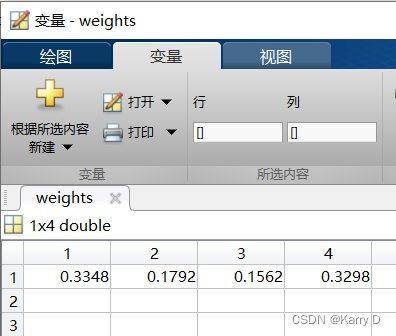
weights=(1-ej)/(cols-sum(ej)); %权重weights5.结果分析
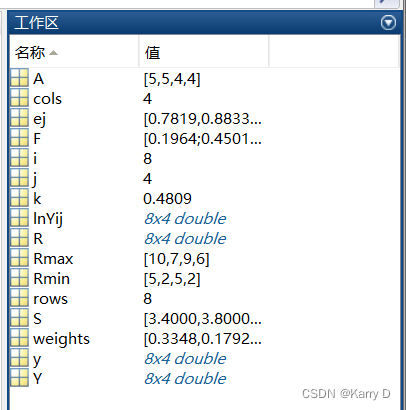
5.1 运行结果:工作区变量
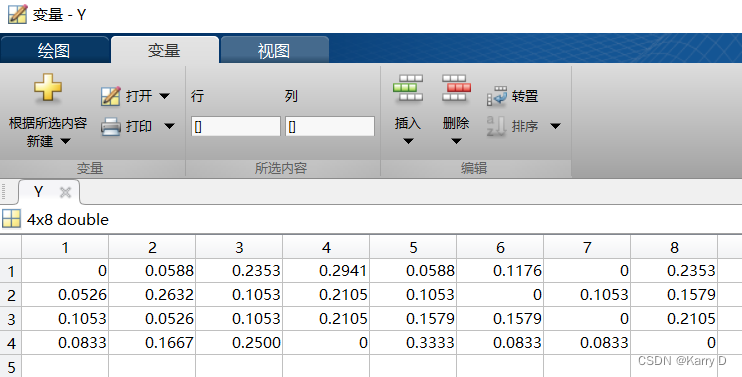
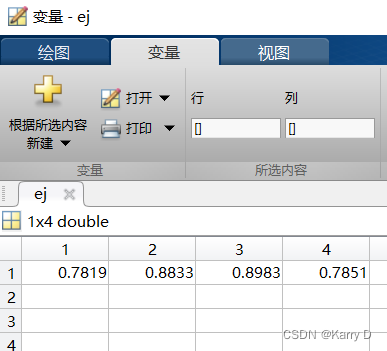
5.2 以“人员因素”为例 结果对比
%归一化处理
%指标信息熵值
%各指标权重
5.3 分析
采用熵权法进行客观权重计算的步骤为:①根据评价等级对指标重要性进行打分,然后构建评价矩阵;②将评价矩阵进行归一化处理,得到归一化评价矩阵;③根据信息熵计算公式,计算各个指标的信息熵;④根据熵权计算公式,计算各个指标的客观权重值 。
代码也是根据这个思路进行的复现。
6.总结
(1)本文运用熵权法与模糊综合评价法,针对人员因素、机械因素、环境因素、管理因素 4 个指标层,作业人员安全意识等 15 个准则层建立某施工项目指标体系进行风险评价,得出的评价等级 为“安全”,与实地考察情况相符。
(2)熵权 - 模糊综合法对于该类施工项目具有普遍适用性,在一定程度上可以弥补 AHP 方法主观性较强的缺陷,可操作性强,便于其他学者理解使用,可供其他建筑施工项目借鉴。
相关文章
- Spark:星星之火即将燎原
- 数据挖掘中易犯的11大错误
- 未来预测:Hadoop将无法独自处理大数据
- 深入理解Redis主键失效原理及实现机制
- 无所不能的大数据:预测本届世界杯赛事结果
- 2014世界杯冠军预测图:基于大数据与JavaScript
- Splunk推出Hunk 6.1 面向Hadoop与NoSQL Data Stores
- 为什么大数据与传统商业智能有所不同
- Spark基本概念解析
- Spark的Standalone模式部署
- Spark集群部署
- Apache Spark三种分布式部署方式比较
- 大数据时代的数据库集群技术漫谈
- 对比Hadoop 分析Spark受多方追捧的原因
- Apache Spark是大数据领域的下一个大家伙吗?
- 使用Windows Azure搭建Hadoop集群
- 淘宝主搜索离线集群完成Hadoop 2.0升级
- 大数据史记2013:盘点中国2013行业数据量
- Hadoop虽然强大,但不是万能的
- 大数据之路(二)大数据结构化数据存储应用模式