
Spark基本概念解析
1:实验配置
虚拟机cdh1(4G内存,1CPU*2CORE)
虚拟机cdh2(4G内存,1CPU*2CORE)
虚拟机cdh3(4G内存,1CPU*2CORE)
spark配置:
conf/spark-env.sh
- export SPARK_MASTER_IP=cdh1
- export SPARK_WORKER_CORES=2
- export SPARK_WORKER_INSTANCES=2
- export SPARK_MASTER_PORT=7077
- export SPARK_WORKER_MEMORY=1200m
- export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
conf/slaves
- cdh2
- cdh3
2:启动spark
在这里spark作为一个资源管理器的存在,类似YARN、Mesos的角色,为Spark Application提供资源。
在本配置里,这个standalone spark所拥有的资源是:2个Worker Node,每个Worker Node提供2Core、2个INSTANCE(也就是启动2个worker 实例)、1.2G内存。所以总的资源是:4个Worker,8个Core,4.8G内存。可以通过http://cdh1:8080获取相应的信息:
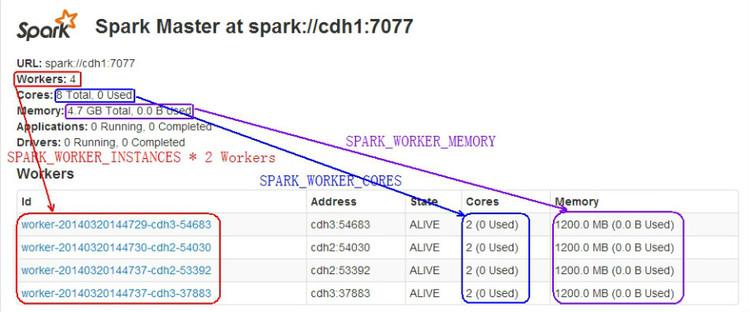
3:启动spark-shell
spark-shell 是一个spark application,运行时需要向资源管理器申请资源,如standalone spark、YARN、Mesos。本例向standalone spark申请资源,所以在运行spark-shell时需要指向申请资源的standalone spark集群信息,其参数为MASTER。如果未在spark-env.sh中申明MASTER,则使用命令MASTER=spark://cdh1:7077 bin/spark-shell启动;如果已经在spark-env.sh中申明MASTER,则可以直接用bin/spark-shell启动。
由于spark-shell缺省的情况下,会申请所有的CPU资源,也就是8个Core,本实验先看看使用3个Core的情况。至于spark-shell申请内存资源是通过Application中SparkContext中配置-->环境变量SPARK_MEM-->缺省值512M这样的优先次序来决定,本例中未做任何设置 ,故每个Executor使用的是512M。
[hadoop@cdh1 spark09]$ bin/spark-shell -c 3
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!