
RabbitMQ安装笔记
安装Erlang语言包
//在Linux系统上执行命令: wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-22.3.4.12-1.el7.x86_64.rpm/ //Erlang的rpm包下载完成,安装已下载的rpm包 yum localinstall erlang-22.3.4.12-1.el7.x86_64.rpmdownload.rpm
安装RabbitMQ
//在Linux系统上执行命令: wget --content-disposition https://packagecloud.io/rabbitmq/rabbitmq-server/packages/el/7/rabbitmq-server-3.8.13-1.el7.noarch.rpm/download.rpm //RabbitMQ的rpm包下载完成,安装已下载的rpm包 yum localinstall rabbitmq-server-3.8.13-1.el7.noarch.rpm
常用命令记录
# 启动rabbitmq systemctl start rabbitmq-server #设置开机自动启动 systemctl enable rabbitmq-server # 查看rabbitmq状态 systemctl status rabbitmq-server //默认情况下,rabbitmq没有安装web端的客户端软件,需要安装才可以生效 # 安装RabbitMQWeb管理界面插件(请在服务器上开放15672端口(配置默认访问端口)【打开阿里云安全组以及防火墙的15672端口】) rabbitmq-plugins enable rabbitmq_management # 安装完毕以后,需要重启服务 systemctl restart rabbitmq-server //rabbitmq有一个默认的账号密码guest,但该情况仅限于本机localhost进行访问,所以需要添加一个远程登录的用户 # 添加用户 rabbitmqctl add_user 用户名 密码 示例:rabbitmqctl add_user admin admin # 设置用户角色,分配操作权限 rabbitmqctl set_user_tags 用户名 角色 示例:rabbitmqctl set_user_tags admin administrator # 为用户添加资源权限(授予访问虚拟机根节点的所有权限) rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*" 示例:rabbitmqctl set_permissions -p / admin "." "." ".*" PS:角色有四种: administrator:可以登录控制台、查看所有信息、并对rabbitmq进行管理 monToring:监控者;登录控制台,查看所有信息 policymaker:策略制定者;登录控制台指定策略 managment:普通管理员;登录控制 //其他指令: # 修改密码 rabbitmqctl change_ password 用户名 新密码 # 删除用户 rabbitmqctl delete_user 用户名 # 查看用户清单 rabbitmqctl list_users
Docker安装RabbitMQ(基于已有docker)
# 安装启动rabbitmq容器
docker run -d --name myRabbitMQ -e RABBITMQ_DEFAULT_USER=zsr -e RABBITMQ_DEFAULT_PASS=123456 -p 15672:15672 -p 5672:5672 rabbitmq:3.8.14-management
RabbitMQ集群搭建
【1】介绍
在RabbitMQ中,一个节点的服务其实也是作为一个集群来处理的,在web控制台的admin-> cluster 中可以看到集群的名字,并且可以在页面上修改。而多节点的集群有两种方式:默认的普通集群模式 与 镜像模式。
【2】默认的普通集群模式:
1)这种模式使用Erlang语言天生具备的集群方式搭建。这种集群模式下,集群的各个节点之间只会有相同的元数据,即队列结构,而消息不会进行冗余,只存在一个节点中。消费时,如果消费的不是存有数据的节点, RabbitMQ会临时在节点之间进行数据传输,将消息从存有数据的节点传输到消费的节点。
2)很显然,这种集群模式的消息可靠性不是很高。因为如果其中有个节点服务宕机了,那这个节点上的数据就无法消费了,需要等到这个节点服务恢复后才能消费,而这时,消费者端已经消费过的消息就有可能给不了服务端正确应答,服务起来后,就会再次消费这些消息,造成这部分消息重复消费。 另外,如果消息没有做持久化,重启就消息就会丢失。
3)并且,这种集群模式也不支持高可用,即当某一个节点服务挂了后,需要手动重启服务,才能保证这一部分消息能正常消费。
4)所以这种集群模式只适合一些对消息安全性不是很高的场景。而在使用这种模式时,消费者应该尽量的连接上每一个节点,减少消息在集群中的传输。
【3】镜像模式:
1)这种模式是在普通集群模式基础上的一种增强方案,这也就是RabbitMQ的官方HA高可用方案。需要在搭建了普通集群之后再补充搭建。其本质区别在于,这种模式会在镜像节点中间主动进行消息同步,而不是在客户端拉取消息时临时同步。
2)并且在集群内部有一个算法会选举产生master和slave,当一个master挂了后,也会自动选出一个来。从而给整个集群提供高可用能力。
3)这种模式的消息可靠性更高,因为每个节点上都存着全量的消息。而他的弊端也是明显的,集群内部的网络带宽会被这种同步通讯大量的消耗,进而降低整个集群的性能。这种模式下,队列数量最好不要过多。
【4】搭建普通集群:
1)需要同步集群节点中的cookie。
默认会在 /var/lib/rabbitmq/目录下生成一个.erlang.cookie。【使用ls -a可查看】
里面有一个字符串。我们要做的就是保证集群中三个节点的这个cookie字符串一致。
2)将worker1的服务加入到worker2的集群中。(我们实验中将worker1和worker3加入到worker2的RabbitMQ集群中,所以将worker2的.erlang.cookie文件分发到worker1和worker3)
//首先需要保证worker1上的rabbitmq服务是正常启动的。 然后执行以下指令: [root@worker1 rabbitmq]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@worker1 ... [root@worker1 rabbitmq]# rabbitmqctl join_cluster --ram rabbit@worker2 Clustering node rabbit@worker1 with rabbit@worker2 [root@worker1 rabbitmq]# rabbitmqctl start_app Starting node rabbit@worker1 ... --ram 表示以Ram节点加入集群。RabbitMQ的集群节点分为disk和ram。disk节点会将元数据保存到硬盘当中,而ram节点只是在内存中保存元数据。 1、由于ram节点减少了很多与硬盘的交互,所以,ram节点的元数据使用性能会比较高。但是,同时,这也意味着元数据的安全性是不如disk节点的。在我们这个集群中,worker1和worker3都以ram节点的身份加入到worker2集群里,因此,是存在单点故障的。如果worker2节点服务崩溃,那么元数据就有可能丢失。在企业进行部署时,性能与安全性需要自己进行平衡。 2、这里说的元数据仅仅只包含交换机、队列等的定义,而不包含具体的消息。因此,ram节点的性能提升,仅仅体现在对元数据进行管理时,比如修改队列queue,交换机exchange,虚拟机vhosts等时,与消息的生产和消费速度无关。 3、如果一个集群中,全部都是ram节点,那么元数据就有可能丢失。这会造成集群停止之后就启动不起来了。RabbitMQ会尽量阻止创建一个全是ram节点的集群,但是并不能彻底阻止。所以,综合考虑,官方其实并不建议使用ram节点,更推荐保证集群中节点的资源投入,使用disk节点。 然后同样把worer3上的rabbitmq加入到worker2的集群中。 加入完成后,可以在worker2的Web管理界面上看到集群的节点情况,也可以用后台指令查看集群状态 rabbitmqctl cluster_status
3)注意点:上述的worker1等已经在服务器上配置了本地域名IP映射:
//在文件/etc/hosts 127.0.0.1 localhost # 新加入域名IP映射 //xxx.xxx.xxx.xxx代表自己的哪三台服务器的公网ip xxx.xxx.xxx.xxx worker1 xxx.xxx.xxx.xxx worker2 xxx.xxx.xxx.xxx worker3
【5】镜像模式:
1)完成了普通集群的搭建。 再此基础上,可以继续搭建镜像集群。通常在生产环境中,为了减少RabbitMQ集群之间的数据传输,在配置镜像策略时,会针对固定的虚拟主机virtual host来配置。
RabbitMQ中的vritual host可以类比为MySQL中的库,针对每个虚拟主机,可以配置不同的权限、策略等。并且不同虚拟主机之间的数据是相互隔离的。
2)先创建一个/mirror的虚拟主机,然后再添加给对应的镜像策略:
[root@worker2 rabbitmq]# rabbitmqctl add_vhost /mirror Adding vhost "/mirror" ... [root@worker2 rabbitmq]# rabbitmqctl set_policy ha-all --vhost "/mirror" "^" '{"ha-mode":"all"}' Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/mirror" ...
同样,这些配置的策略也可以在Web控制台操作。另外也提供了HTTP API来进行这些操作:
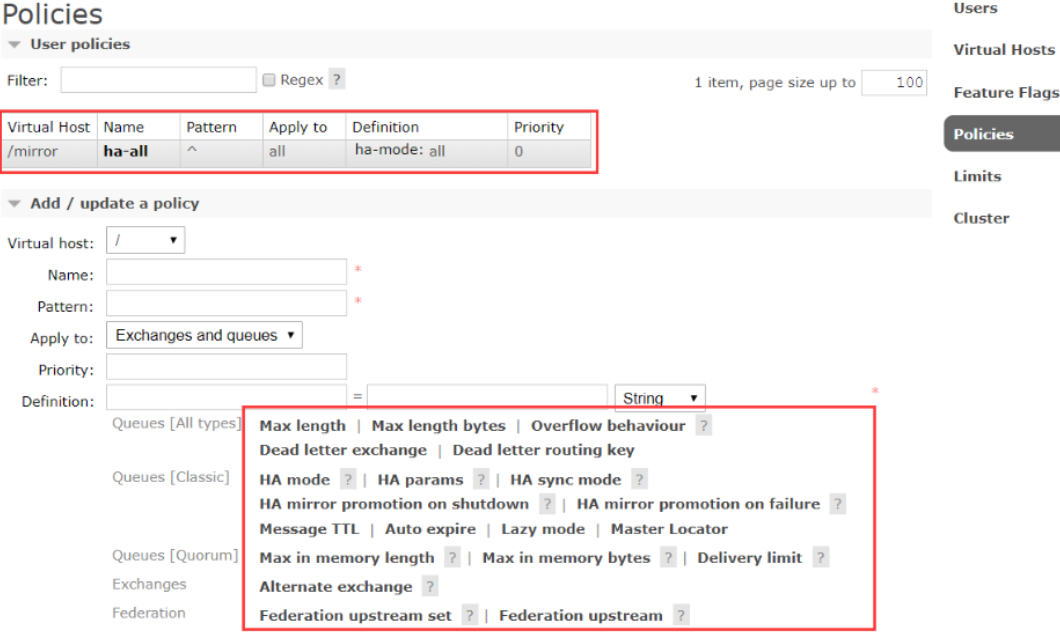
这些参数需要大致了解下。其中,pattern是队列的匹配规则, ^表示全部匹配。 ^ ha \ 这样的配置表示以ha开头。通常就用虚拟主机来区分就够了,这个队列匹配规则就配置成全匹配。 然后几个关键的参数: HA mode: 可选值 all , exactly, nodes。生产上通常为了保证高可用,就配all all : 队列镜像到集群中的所有节点。当新节点加入集群时,队列也会被镜像到这个节点。 exactly : 需要搭配一个数字类型的参数(ha-params)。队列镜像到集群中指定数量的节点。如果集群内节点数少于这个数字,则队列镜像到集群内的所有节点。如果集群内节点少于这个数,当一个包含镜像的节点停止服务后,新的镜像就不会去另外找节点进行镜像备份了。 nodes: 需要搭配一个字符串类型的参数。将队列镜像到指定的节点上。如果指定的队列不在集群中,不会报错。当声明队列时,如果指定的所有镜像节点都不在线,那队列会被创建在发起声明的客户端节点上。 还有其他很多参数,可以后面慢慢再了解。
通常镜像模式的集群已经足够满足大部分的生产场景了。虽然他对系统资源消耗比较高,但是在生产环境中,系统的资源都是会做预留的,所以正常的使用是没有问题的。但是在做业务集成时,还是需要注意队列数量不宜过多,并且尽量不要让RabbitMQ产生大量的消息堆积。
这样搭建起来的RabbitMQ已经具备了集群特性,往任何一个节点上发送消息,消息都会及时同步到各个节点中。而在实际企业部署时,往往会以RabbitMQ的镜像队列作为基础,再增加一些运维手段,进一步提高集群的安全性和实用性。
例如,增加keepalived保证每个RabbitMQ的稳定性,当某一个节点上的RabbitMQ服务崩溃时,可以及时重新启动起来。另外,也可以增加HA-proxy来做前端的负载均衡,通过HA-proxy增加一个前端转发的虚拟节点,应用可以像使用一个单点服务一样使用一个RabbitMQ集群。这些运维方案有兴趣可以自己了解下。
负载均衡-HAProxy
1)介绍
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。HAProxy支持从4层至7层的网络交换,即覆盖所有的TCP协议。就是说,Haproxy 甚至还支持 Mysql 的均衡负载。
HAProxy的特点是: 1、HAProxy是支持虚拟主机的,,并能支持上万级别的连接; 2、能够补充Nginx的一些缺点比如Session的保持,cookie的引导等工作; 3、支持url检测后端的服务器出问题的检测会有很好的帮助; 4、它跟LVS一样,本身仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的; 5、HAProxy可以对mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,不过在后端的MySQL slaves数量超过10台时性能不如LVS,所以我向大家推荐LVS+Keepalived; 6、能够提供4层,7层代理。HAProxy支持两种主要的代理模式:"tcp"也即4层(大多用于邮件服务器、内部协议通信服务器等),和7层(HTTP)。在4层模式 下,HAProxy仅在客户端和服务器之间转发双向流量,7层模式下,HAProxy会分析协议,并且能通过允许、拒绝、交换、增加、修改或者删除请求 (request)或者回应(response)里指定内容来控制协议,这种操作要基于特定规则; 7、HAProxy的算法现在也越来越多了,具体有如下8种: ①roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的; ②static-rr,表示根据权重,建议关注; ③leastconn,表示最少连接者先处理,建议关注; ④source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注; ⑤ri,表示根据请求的URI; ⑥rl_param,表示根据请求的URl参数'balance url_param' requires an URL parameter name; ⑦hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求; ⑧rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
2)安装HAProxy
//安装HAProxy yum -y install haproxy
3)修改配置文件【目录在/etc/haproxy/haproxy.cfg】
示例:
###########全局配置######### global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy # 改变当前工作目录 stats socket /run/haproxy/admin.sock mode 660 level admin # 创建监控所用的套接字目录 pidfile /var/run/haproxy.pid # haproxy的pid存放路径,启动进程的用户必须有权限访问此文件 maxconn 4000 # 最大连接数,默认4000 user haproxy # 默认用户 group haproxy # 默认用户组 daemon # 创建1个进程进入deamon模式运行。此参数要求将运行模式设置为"daemon # Default SSL material locations ca-base /etc/ssl/certs crt-base /etc/ssl/private # Default ciphers to use on SSL-enabled listening sockets. # For more information, see ciphers(1SSL). This list is from: # https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/ ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+3DES:!aNULL:!MD5:!DSS ssl-default-bind-options no-sslv3 ###########默认配置######### defaults log global mode http # 默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK option httplog # 采用http日志格式 option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器 # 或者监控系统为了探测该 服务是否存活可用时,需要定期的连接或者获取某 # 一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接; # 官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用 # 该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来 timeout connect 5000 # 连接超时时间 timeout client 50000 # 客户端连接超时时间 timeout server 50000 # 服务器端连接超时时间 option httpclose # 每次请求完毕后主动关闭http通道 option httplog # 日志类别http日志格式 #option forwardfor # 如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip option redispatch # serverId对应的服务器挂掉后,强制定向到其他健康的服务器 timeout connect 10000 # default 10 second timeout if a backend is not found maxconn 60000 # 最大连接数 retries 3 # 3次连接失败就认为服务不可用,也可以通过后面设置 errorfile 400 /etc/haproxy/errors/400.http errorfile 403 /etc/haproxy/errors/403.http errorfile 408 /etc/haproxy/errors/408.http errorfile 500 /etc/haproxy/errors/500.http errorfile 502 /etc/haproxy/errors/502.http errorfile 503 /etc/haproxy/errors/503.http errorfile 504 /etc/haproxy/errors/504.http #################################################################### listen http_front bind 0.0.0.0:1080 #监听端口 stats refresh 30s #统计页面自动刷新时间 stats uri /haproxy?stats #统计页面url stats realm Haproxy Manager #统计页面密码框上提示文本 stats auth admin:admin #统计页面用户名和密码设置 #stats hide-version #隐藏统计页面上HAProxy的版本信息 #####################我把RabbitMQ的管理界面也放在HAProxy后面了############################### listen rabbitmq_admin bind 0.0.0.0:8004 server node1 192.168.0.31:15672 server node2 192.168.0.32:15672 server node3 192.168.0.33:15672 #################################################################### listen rabbitmq_cluster bind 0.0.0.0:5672 option tcplog mode tcp timeout client 3h timeout server 3h option clitcpka balance roundrobin #负载均衡算法(#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数) #balance url_param userid #balance url_param session_id check_post 64 #balance hdr(User-Agent) #balance hdr(host) #balance hdr(Host) use_domain_only #balance rdp-cookie #balance leastconn #balance source //ip server node1 192.168.0.31:5672 check inter 5s rise 2 fall 3 #check inter 2000 是检测心跳频率,rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用 server node2 192.168.0.32:5672 check inter 5s rise 2 fall 3 server node3 192.168.0.33:5672 check inter 5s rise 2 fall 3
核心点:
listen rabbitmq_cluster bind 0.0.0.0:5672 //绑定本地5672,转发到下面三台服务器 mode tcp balance roundrobin #负载均衡算法,简单轮训 server node1 192.168.0.31:5672 check inter 5000 rise 2 fall 3 #check inter 是检测心跳频率,rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用 server node2 192.168.0.32:5672 check inter 5000 rise 2 fall 3 server node3 192.168.0.33:5672 check inter 5000 rise 2 fall 3
相关文章
- C++笔记(12) 标准模板库STL
- C++笔记(13)数组的引用和引用的数组
- Opencv笔记(11)随机数发生器cv::RNG
- 【Effective C++】设计与声明
- 【Effective C++】资源管理
- Xshell和Xftp - 下载安装
- 【论文笔记】YOLO系列
- Jmeter系列(7)- 分析源码,创建下单、用户注销接口请求
- Jmeter系列(6)- 分析源码,创建登录、浏览商品接口请求
- 【Effective C++】构造/析构/赋值运算
- Jmeter系列(3) - 静默压测
- Jmeter系列(3)- 常用断言之响应断言
- 【Effective C++】让自己习惯C++
- Jmeter系列(2)- 代理服务器录制脚本
- 【论文笔记】ResNet深度残差网络
- Jmeter系列(1) - 踩坑之代理服务器录制失败
- SourceTree使用详解-摘录收藏
- C#笔记 picturebox功能实现(滚动放大,拖动)
- 【论文笔记】R-CNN系列之代码实现
- 【论文笔记】R-CNN系列之论文理解