
联邦学习综述:挑战、方法和未来方向
联邦学习:挑战、方法和未来方向
本文可能在基础上拓展了很多新的应用场景和思路,值得参考,联邦学习中可以考虑的点其实有很多。
一、简介
随着移动设备等算力增强,信息传输的隐私问题日渐让人担忧。可以考虑在本地存储和使用模型但是集中训练机器学习模型的方式,比如手机用户的建模和个性化。联邦学习可以使得模型能够直接在远程设备进行训练。
智能手机
例如智能手机的输入法补全功能,用户处于隐私不想公开自己的数据,联邦学习可以在不泄露用户隐私信息的情况下完成该功能的大规模学习,采用所有用户的历史文本信息训练模型。

组织机构
比如医院包含很多病人的信息,能够预测健康情况,但是医院的隐私要求很严格,甚至是伦理问题,联邦学习能为这些应用解决问题,能够在保证隐私的情况下多方联合学习。
物联网
像一些无线车辆、智能家居等会有很多传感器,比如自动驾驶车辆需要更新交通数据模型,但是采用本地数据很难建模,因为没有其他设备间的联系,联邦学习可以在保证用户隐私的条件下训练模型,解决此类问题。
目标函数
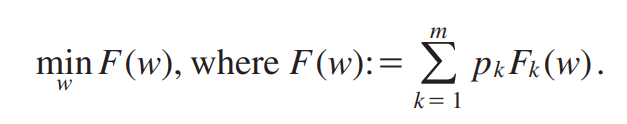
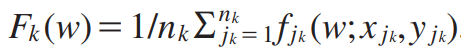
二、主要挑战
2.1 交互开销
由于带宽、能源等问题,网络上的交互要比本地计算慢得多,因此提高交互效率很重要,需要考虑的两个方面有:减少交互轮次或者减少每轮交互信息量。
2.2 系统不一致性
随硬件、网络和能源的不同,联邦网络的存储、计算和交互能力也不同,网络的大小或者设备系统限制导致每次只有一部分设备是激活的。或者有些设备在迭代过程中可能关机,退出激活态。因此联邦学习方法必须:考虑参与者数目较少问题、硬件不一致的容错率和对在交互网络中离线设备的鲁棒性。
2.3 数据不一致性
网络中不断产生分布差异很大的数据,比如在输入法补全任务中手机用户有很多使用的语言。设备间的数据不同,可能有一种潜在的统计结构表示不同设备的关系和分布。所以联邦学习可能存在一些问题,学习全局模型时,需要同时通过多任务学习框架学习本地模型,可能用到元学习的方法;从多任务和元学习角度能够使本地模型更加个性化,解决数据异质的问题。
2.4 隐私问题
联邦学习只共享模型更新信息,比如梯度,而不是原始数据。尽管如此,还是会泄露给第三方或者中央服务器信息。即使最近用于增加隐私保护的方法,如SMC和差分隐私等,但是会降低系统效率和模型效果。需要在这些方面进行权衡。
三、近期相关工作研究
3.1 交互效率
交互是联邦网络方法进展中的一个瓶颈,接下来从三个方面介绍:本地模型更新、压缩策略和分散训练。
本地模型更新
随机梯度下降法是分布式机器学习经常使用的方法,但是在交互上也有很多局限性,很多方法被提出增强分布式环境下的通信效率。
很多分布式本地更新的简单方法能够解决这些问题,这些方法采用对偶结构有效的将全局目标分解为子问题,每一轮并行的解决。
联邦学习最常用的方法是联邦平均(FedAvg),通过将本地SGD更新进行平均,尤其是对于非凸问题有很好的效果,但是不能在数据不一致的情况下保证收敛。
压缩策略
即使本地更新策略可以减少交互轮次,但是模型压缩策略如稀疏化或量化都能显著减少交互信息的长度。在联邦环境中,诸如参与设备少、本地数据分布不同和本地更新策略对这些压缩方法都有新的挑战。虽然很多工作都能够保证收敛,适用于分布式数据,但是没有考虑像设备参与度不高或者本地模型更新方法的联邦学习相关问题。

分散式训练
图中a是星形拓扑网络,b是分散式拓扑网络,分散式因为带宽低、延迟低比中央训练速度快,可以减少和中心服务器的高交互开销,最近一些工作介绍了一些不一致数据的本地更新策略,但是局限于线性模型或者假设所有设备均参与更新。

3.2 系统不一致性
异步交互
同步交互很简单,能够保证串行计算模型,但是由于设备不同很难实现。异步策略可以减少不一致环境的问题,尤其是公共存储系统。即使异步参数服务器在分布式数据中心和成功,但是对联邦学习来说,延迟可以长达几小时、几天甚至无限期。
动态采样
有一种方法可以动态的在每轮选参与设备,用一个预定义窗口整合尽可能多的设备,选择的设备虽然少但是要有代表性,能表示统计结构。
容错率
在训练迭代完成之前可能有一些设备掉线,一个可行的策略是忽略那些掉线的设备,像FedAvg,会引入偏置,例如那些偏远地区的设备由于网络问题更容易掉线,所以模型会更倾向于那些网络条件好的设备。
代码计算是容差的另外一种方法,其引入算法冗余。例如,梯度编码可以修复真实梯度,但是也在联邦环境中有很多挑战,比如隐私政策和大规模网络下的设备间信息交换。
3.3 统计不一致性
不一致数据建模
借鉴元学习和多任务学习的方法。
- MOCHA是为联邦背景设计的优化结构,允许通过学习每个设备相关的模型进行个性化,而且能够证明收敛性,但是受限于网络规模,只适用于凸目标。
- 像星形拓扑一样的贝叶斯网络,即使可以解决非凸函数,但是大规模联邦开销很大。
- 多任务信息的元学习
- 多元化解决方案,自适应的选择全局或局部模型
- 不可知论联邦学习,中央模型的优化对最大最小优化策略的混合客户分布组成的任意目标分布都适用
- q-FFL,有较高loss的设备给予更高的相对权重,使得最后的准确率分布偏差减小
- 除了平衡问题,我们注意到像可解释性和问责对联邦学习来说更重要,由于规模和不一致问题可能还有很多挑战。
非独立同分布的数据保证收敛
网络中的数据不是独立同分布的话,像FedAvg等方法在本地数据更新太多时会有偏差,平行SGD也一样。
像之前所说的,系统简单的丢弃那些掉线的设备会导致统计不一致性,FedProx在FedAvg上做了一个小的修改,允许在满足约束的条件下跨多个设备执行部分工作,实际上相当于在FedAvg基础上协调叫本地epoch。但是epoch数在系统限制下调节时不现实的,近似项有两个好处:使得训练较好的本地模型更新更接近原始全局模型,还能安全的联合所选的部分更新的设备模型。因此,FedProx对凸和非凸函数都能保持收敛。但是这些保障收敛的方法都不现实:他们使得带宽增加提高网络负担,将本地数据上传到服务器会有隐私问题。
3.4 隐私
机器学习中的隐私
差分隐私是最常见的,有很强的理论保证,一个数据的改变并不能导致输出分布的变化,所以很难看出某个样本是否在学习过程中被使用。样本级别的隐私保护可以在很多学习任务中完成,基于梯度的学习中,可以随机排列每次迭代的即时输出。
需要在模型准确率和差分隐私之间权衡的话,在结果增加噪声会减少准确率。
还有同态加密方法,但是只能局限于训练线性模型。当用户数据分布不同时,可以采用SFC或者SMC加密,即使SMC不能保证信息泄露,但是可以和其它像差分隐私结合来提高安全保证。对于大规模学习来说,它们会增加交互和计算开销。
隐私联邦学习
隐私可以分为两方面:全局隐私和局部隐私,全局隐私需要在模型更新时保证第三方或者中央服务器不能获取信息,局部隐私要保证更新对服务器来说是安全的。

四、未来方向
4.1 交互策略
即使one-shot和分治交互策略在传统数据中心设定中有发掘,但是这些方法没有考虑大型统计异质的网络。
4.2 减少通信
需要很好的衡量准确率和交互方法,最有效的方法是Pareto frontier的改进,准确率有所提高。
4.3 异步新模型
可以研究设备何时被唤醒,什么时候从中心节点获取新的任务和执行本地计算。
4.4 异质性诊断
- 如何快速推断联邦网络中的异质水平?
- 是否可以加强诊断确定系统相关异质的数量?
- 是否能利用现有或新的异质性定义,在经验或者理论上设计具有改进收敛性的联邦优化方法?
4.5 粒度隐私约束
可能需要更细粒度的定义隐私,每个设备甚至设备的数据点都是不同的。开发一个解决混合隐私(设备级别和样本级别)的方法是今后一个研究方向。
4.6 超监督学习
也许在很多联邦网络中的数据都是没有标签或是弱标签的,非监督学习或者其它半监督学习也可能和尺度、异质性和隐私具有相同的挑战性。
4.7 产生式联合学习
实际环境中运行联合学习模型时还存在许多问题,如概念漂移(数据生成模型随时间变化)、日变化(设备一天或者一周不同时间出现不同行为)和冷启动问题(新设备进入网络)等。
4.8 基准
由于联邦学习是一个新兴领域,我们必须保证其以现实世界的环境、假设和数据作为基础,利用现有工具实现是很重要的。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合