
机器学习中的数学——距离定义(二十六):Wasserstein距离(Wasserstei Distance)/EM距离(Earth-Mover Distance)
分类目录:《机器学习中的数学》总目录
相关文章:
· 距离定义:基础知识
· 距离定义(一):欧几里得距离(Euclidean Distance)
· 距离定义(二):曼哈顿距离(Manhattan Distance)
· 距离定义(三):闵可夫斯基距离(Minkowski Distance)
· 距离定义(四):切比雪夫距离(Chebyshev Distance)
· 距离定义(五):标准化的欧几里得距离(Standardized Euclidean Distance)
· 距离定义(六):马氏距离(Mahalanobis Distance)
· 距离定义(七):兰氏距离(Lance and Williams Distance)/堪培拉距离(Canberra Distance)
· 距离定义(八):余弦距离(Cosine Distance)
· 距离定义(九):测地距离(Geodesic Distance)
· 距离定义(十): 布雷柯蒂斯距离(Bray Curtis Distance)
· 距离定义(十一):汉明距离(Hamming Distance)
· 距离定义(十二):编辑距离(Edit Distance,Levenshtein Distance)
· 距离定义(十三):杰卡德距离(Jaccard Distance)和杰卡德相似系数(Jaccard Similarity Coefficient)
· 距离定义(十四):Ochiia系数(Ochiia Coefficient)
· 距离定义(十五):Dice系数(Dice Coefficient)
· 距离定义(十六):豪斯多夫距离(Hausdorff Distance)
· 距离定义(十七):皮尔逊相关系数(Pearson Correlation)
· 距离定义(十八):卡方距离(Chi-square Measure)
· 距离定义(十九):交叉熵(Cross Entropy)
· 距离定义(二十):相对熵(Relative Entropy)/KL散度(Kullback-Leibler Divergence)
· 距离定义(二十一):JS散度(Jensen–Shannon Divergence)
· 距离定义(二十二):海林格距离(Hellinger Distance)
· 距离定义(二十三):α-散度(α-Divergence)
· 距离定义(二十四):F-散度(F-Divergence)
· 距离定义(二十五):布雷格曼散度(Bregman Divergence)
· 距离定义(二十六):Wasserstein距离(Wasserstei Distance)/EM距离(Earth-Mover Distance)
· 距离定义(二十七):巴氏距离(Bhattacharyya Distance)
· 距离定义(二十八):最大均值差异(Maximum Mean Discrepancy, MMD)
· 距离定义(二十九):点间互信息(Pointwise Mutual Information, PMI)
Wasserstein距离也被称为推土机距离(Earth Mover’s Distance,EMD),用来表示两个分布的相似程度。Wasserstein距离衡量了把数据从分布 p p p移动成”分布 q q q时所需要移动的平均距离的最小值。Wasserstein距离是2000年IJCV期刊文章《The Earth Mover’s Distance as a Metric for Image Retrieval》提出的一种直方图相似度量。如果两个分布 p p p和 q q q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为0,即梯度消失,而Wasserstein距离可以解决这个问题。
我们将两个分布
p
p
p和
q
q
q看成两堆土,如下图所示,希望把其中的一堆土移成另一堆土的位置和形状,有很多种可能的方案。推土代价被定义为移动土的量乘以土移动的距离,在所有的方案中,存在一种推土代价最小的方案,这个代价就称为两个分布的Wasserstein距离。
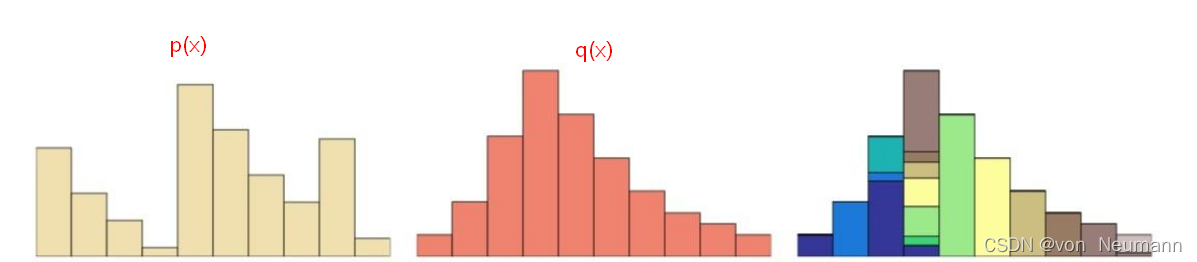
Wasserstein距离的形式化的表达式如下:
W
(
p
,
q
)
=
inf
γ
∼
∏
(
p
,
q
)
E
x
,
y
∼
γ
[
∣
∣
x
−
y
∣
∣
]
W(p, q)=inf_{gammasimprod(p,q)}E_{x, ysimgamma}[||x-y||]
W(p,q)=γ∼∏(p,q)infEx,y∼γ[∣∣x−y∣∣]
其中, ∏ ( p , q ) prod(p,q) ∏(p,q)表示分布 p p p和 q q q组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布 γ gamma γ可以从中采样 ( x , y ) ∼ γ (x, y)simgamma (x,y)∼γ得到一个样本 x x x和 y,并计算出这对样本的距离 ∣ ∣ x − y ∣ ∣ ||x-y|| ∣∣x−y∣∣,所以可以计算该联合分布 γ gamma γ下,样本对距离的期望值 E x , y ∼ γ [ ∣ ∣ x − y ∣ ∣ ] E_{x, ysimgamma}[||x-y||] Ex,y∼γ[∣∣x−y∣∣]。在所有可能的联合分布中能够对这个期望值取到的下界就是Wasserstein距离。用推土的方式理解就是, E x , y ∼ γ [ ∣ ∣ x − y ∣ ∣ ] E_{x, ysimgamma}[||x-y||] Ex,y∼γ[∣∣x−y∣∣]是在 γ gamma γ这种路径规划下,把 p p p这堆土,移成 q q q的样子的消耗,而Wasserstein距离就是在”最优路径规划“下的最小消耗。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合