
1111. 有效括号的嵌套深度
1111. 有效括号的嵌套深度
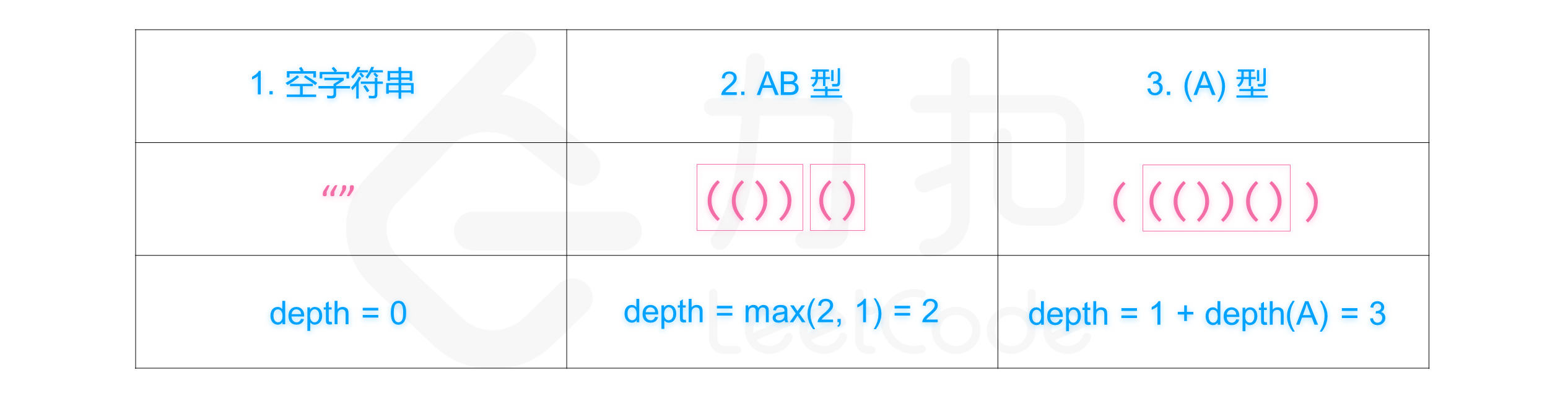
有效括号字符串 定义:对于每个左括号,都能找到与之对应的右括号,反之亦然。详情参见题末「有效括号字符串」部分。
嵌套深度 depth 定义:即有效括号字符串嵌套的层数,depth(A) 表示有效括号字符串 A 的嵌套深度。详情参见题末「嵌套深度」部分。
有效括号字符串类型与对应的嵌套深度计算方法如下图所示:
给你一个「有效括号字符串」 seq,请你将其分成两个不相交的有效括号字符串,A 和 B,并使这两个字符串的深度最小。
不相交:每个 seq[i] 只能分给 A 和 B 二者中的一个,不能既属于 A 也属于 B 。
A 或 B 中的元素在原字符串中可以不连续。
A.length + B.length = seq.length
深度最小:max(depth(A), depth(B)) 的可能取值最小。
划分方案用一个长度为 seq.length 的答案数组 answer 表示,编码规则如下:
answer[i] = 0,seq[i] 分给 A 。
answer[i] = 1,seq[i] 分给 B 。
如果存在多个满足要求的答案,只需返回其中任意 一个 即可。
示例 1:
输入:seq = "(()())"
输出:[0,1,1,1,1,0]
示例 2:
输入:seq = "()(())()"
输出:[0,0,0,1,1,0,1,1]
解释:本示例答案不唯一。
按此输出 A = "()()", B = "()()", max(depth(A), depth(B)) = 1,它们的深度最小。
像 [1,1,1,0,0,1,1,1],也是正确结果,其中 A = "()()()", B = "()", max(depth(A), depth(B)) = 1 。
方法一:用栈进行括号匹配思路及算法
要求划分出使得最大嵌套深度最小的分组,我们首先得知道如何计算嵌套深度。我们可以通过栈实现括号匹配来计算:
维护一个栈 s,从左至右遍历括号字符串中的每一个字符:
如果当前字符是 (,就把 ( 压入栈中,此时这个 ( 的嵌套深度为栈的高度;
如果当前字符是 ),此时这个 ) 的嵌套深度为栈的高度,随后再从栈中弹出一个 (。
下面给出了括号序列 (()(())()) 在每一个字符处的嵌套深度:

知道如何计算嵌套深度,问题就很简单了:只要在遍历过程中,我们保证栈内一半的括号属于序列 A,一半的括号属于序列 B,那么就能保证拆分后最大的嵌套深度最小,是当前最大嵌套深度的一半。要实现这样的对半分配,我们只需要把奇数层的 ( 分配给 A,偶数层的 ( 分配给 B 即可。对于上面的例子,我们将嵌套深度为 1 和 3 的所有括号 (()) 分配给 A,嵌套深度为 2 的所有括号 ()()() 分配给 B。
此外,由于在这个问题中,栈中只会存放 (,因此我们不需要维护一个真正的栈,只需要用一个变量模拟记录栈的大小。
代码:
class Solution{
public:
vector<int >maxDepthAfterSplit(string seq){
int depth=0,len=seq.length();
vector<int >ans;
for (int i = 0; i < len; i++)
{
if (seq[i] == '(') {
ans.push_back((++depth)&1);
} else {
ans.push_back((depth--)&1);
}
}
return ans;
}
};
复杂度分析
时间复杂度:O(n),其中 n 为字符串的长度。我们只需要遍历括号字符串一次。
空间复杂度:O(1)。除答案数组外,我们只需要常数个变量。
方法二:找规律
思路及算法
我们还是使用上面的例子 (()(())()),但这里我们把 ( 和 ) 的嵌套深度分成两行:
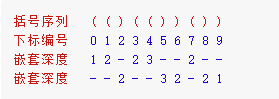
有没有发现什么规律?
左括号 ( 的下标编号与嵌套深度的奇偶性相反,也就是说:
下标编号为奇数的 (,其嵌套深度为偶数,分配给 B;
下标编号为偶数的 (,其嵌套深度为奇数,分配给 A。
右括号 ) 的下标编号与嵌套深度的奇偶性相同,也就是说:
下标编号为奇数的 ),其嵌套深度为奇数,分配给 A;
下标编号为偶数的 ),其嵌套深度为偶数,分配给 B。
这样以来,我们只需要根据每个位置是哪一种括号以及该位置的下标编号,就能确定将对应的对应的括号分到哪个组了。
对此规律感兴趣的同学的同学可以阅读下面的证明部分,若不感兴趣,可以直接跳到代码部分。
证明
对于字符串中的任意一个左括号 (,它的下标编号为 x,嵌套深度为 y。如果它之有 l 个左括号和 r 个右括号,那么根据嵌套深度的定义,有:
y = l - r + 1
y=l−r+1
下标编号与 l 和 r 的关系也可以直接得到,注意下标编号从 0 开始:
x = l + r
x=l+r
由于 l - r和 l + r 同奇偶,因此 l - r + 1(即 y)和 l + r(即 x)的奇偶性相反。
对于字符串中的任意一个右括号 ),它的下标编号为 x,嵌套深度为 y。如果它之有 l 个左括号和 r 个右括号,那么根据嵌套深度的定义,有:
y = l - r
y=l−r
下标编号与 l 和 r 的关系也可以直接得到,注意下标编号从 0 开始:
x = l + r
x=l+r
因此 y 和 x 的奇偶性相同。
class Solution {
public:
vector<int> maxDepthAfterSplit(string seq) {
vector<int> ans;
for (int i = 0; i < (int)seq.size(); ++i) {
ans.push_back(i & 1 ^ (seq[i] == '('));
}
return ans;
}
};
复杂度分析
时间复杂度:O(n),其中 n 为字符串的长度。我们只需要遍历括号字符串一次。
空间复杂度:O(1)。除答案数组外,我们只需要常数个变量。
相关文章
- [PHP] 试题系统研究
- [PHP] Yaf框架的简单安装使用
- [PHP] 链表数据结构(单链表)
- [PHP] 重回基础(IO流)
- [PHP] 重回基础(Array相关函数)
- [PHP] 重回基础(date函数和strtotime函数)
- [HTML5] Canvas绘制简单图片
- [HTML5] Canvas绘制简单形状
- [Redis] redis数据备份恢复与持久化
- [PHP] 商品类型规格属性后台管理(代码流程备忘)
- [PHP] 看博客学习观察者模式
- [PHP] 看博客学习插入排序
- [PHP] 排序和查找算法
- [css3] 看博客学习别人的旋转的星球
- [Redis]Redis的数据类型
- [Redis] redis在centos下安装测试
- [产品设计]电商设计知乎总结
- [PHP] B2B2C商品模块数据库设计
- [css] css3 中的新特性加强记忆
- [Laravel] Laravel的基本数据库操作部分