
论文解读(DGI)《Deep Graph Infomax》
论文信息
论文标题:Deep Graph Infomax
论文作者:Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, R Devon Hjelm
论文来源:2019,ICLR
论文地址:download
论文代码:download
1 Introduction
随机游走的限制:随机游走目标以牺牲结构信息为代价过分强调邻近信息,并且性能高度依赖于超参数的选择。
本文提出了一种用于无监督图学习的替代目标,这种目标是基于互信息,而不是随机游走。在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)是指变量间相互依赖性的量度。近年来基于互信息的代表性工作是 Mutual Information Neural Estimation (MINE),其中提出了一种 Deep InfoMax (DMI) 方法来学习高维数据的表示。 DMI 训练一个编码模型来最大化高阶全局表示和输入的局部部分的互信息。
2 Method
2.1 Local-Global mutual information maximization
图级表示 $ \mathcal{R}: \mathbb{R}^{N \times F} \rightarrow \mathbb{R}^{F}$ 。
$\mathcal{R}(\mathbf{H})=\sigma\left(\frac{1}{N} \sum \limits _{i=1}^{N} \vec{h}_{i}\right)$


class AvgReadout(nn.Module):
def __init__(self):
super(AvgReadout, self).__init__()
def forward(self, seq, msk):
if msk is None:
return torch.mean(seq, 1)
else:
msk = torch.unsqueeze(msk, -1)
return torch.sum(seq * msk, 1) / torch.sum(msk)
判别器 $ \mathcal{D}: \mathbb{R}^{F} \times \mathbb{R}^{F} \rightarrow \mathbb{R}$ 将局部表示和图级表示互信息最大化,$\mathcal{D}\left(\vec{h}_{i}, \vec{s}\right) $ 表示一个概率分数,这个分数越高表示对应的局部表示 $h_i$ 包含越多的图级信息。
$\mathcal{D}\left(\vec{h}_{i}, \vec{s}\right)=\sigma\left(\vec{h}_{i}^{T} \mathbf{W} \vec{s}\right)$
class Discriminator(nn.Module):
def __init__(self, n_h):
super(Discriminator, self).__init__()
self.f_k = nn.Bilinear(n_h, n_h, 1)
for m in self.modules():
self.weights_init(m)
def weights_init(self, m):
if isinstance(m, nn.Bilinear):
torch.nn.init.xavier_uniform_(m.weight.data)
if m.bias is not None:
m.bias.data.fill_(0.0)
def forward(self, c, h_pl, h_mi, s_bias1=None, s_bias2=None):
c_x = torch.unsqueeze(c, 1)
c_x = c_x.expand_as(h_pl)
sc_1 = torch.squeeze(self.f_k(h_pl, c_x), 2)
sc_2 = torch.squeeze(self.f_k(h_mi, c_x), 2)
if s_bias1 is not None:
sc_1 += s_bias1
if s_bias2 is not None:
sc_2 += s_bias2
logits = torch.cat((sc_1, sc_2), 1)
return logits
对于单个图,负样本的生成需要一个随机变换函数 $C$ :$ \mathcal{C}: \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{M \times F} \times \mathbb{R}^{M \times M} $ 来生成,可以表述为 $ (\widetilde{\boldsymbol{X}}, \widetilde{\boldsymbol{A}})=\mathcal{C}(\boldsymbol{X}, \boldsymbol{A}) $。
目标函数:
$\mathcal{L}=\frac{1}{N+M}\left(\sum \limits _{i=1}^{N} \mathbb{E}_{(\mathbf{X}, \mathbf{A})}\left[\log \mathcal{D}\left(\vec{h}_{i}, \vec{s}\right)\right]+\sum \limits_{j=1}^{M} \mathbb{E}_{(\tilde{\mathbf{X}}, \tilde{\mathbf{A}})}\left[\log \left(1-\mathcal{D}\left(\overrightarrow{\widetilde{h}}_{j}, \vec{s}\right)\right)\right]\right)\quad\quad\quad(1)$
在代码层面,$N =M$。
b_xent = nn.BCEWithLogitsLoss() #二分类交叉熵
logits = model(features, shuf_fts, sp_adj if args.sparse else adj, args.sparse, None, None, None)
loss = b_xent(logits, lbl) #lbl 1、1、1、1、 0、0、0、0、0、
2.2 Framework
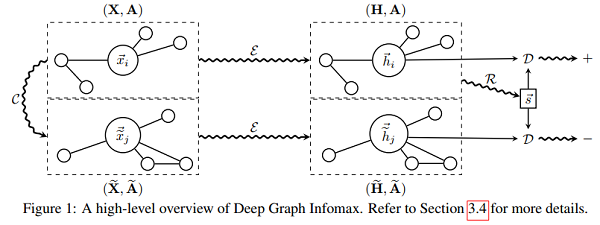
DGI 的步骤:
1. 通过某种随机变换 $C$ 得到负样本实例: $ (\widetilde{X}, \widetilde{\boldsymbol{A}}) \sim \mathcal{C}(\boldsymbol{X}, \boldsymbol{A}) $ ;
2. 通过 GCN 编码器获得输入图的隐表示 $\overrightarrow{h_{i}}: \boldsymbol{H}=\mathcal{E}(\boldsymbol{X}, \boldsymbol{A})=\left\{\overrightarrow{h_{1}}, \overrightarrow{h_{2}}, \ldots, \overrightarrow{h_{N}}\right\} $;
3. 通过 GCN 编码器获得负样本的隐表示 $\vec{h}_{j}: \widetilde{H}=\mathcal{E}(\widetilde{X}, \widetilde{A})=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \widetilde{h}_{M}\right\} $;
4. 通过 Readout 函数传递输入图的隐表示来得到图级别的隐表示: $ \vec{s}=\mathcal{R}(\boldsymbol{H})$ ;
5. 通过梯度下降法最小化目标函数式 (1),更新参数 $\mathcal{E}, \mathcal{R}, \mathcal{D}$;
3 Experiment
数据集

先利用 $\text{Eq.1}$ 进行训练得到表示,然后训练一个一个简单的线性(逻辑回归)分类器来实现分类。
直推式学习 Transductive learning
编码器是一层图卷积网络(GCN)模型,具有以下传播规则:
$\mathcal{E}(\mathbf{X}, \mathbf{A})=\sigma\left(\hat{\mathbf{D}}^{-\frac{1}{2}} \hat{\mathbf{A}} \hat{\mathbf{D}}^{-\frac{1}{2}} \mathbf{X} \boldsymbol{\Theta}\right)$
其中, $\hat{A}=A+I_{N} $ 代表加上自环的邻接矩阵, $\hat{D}$ 代表度矩阵,满足 $\hat{D}_{i i}=\sum_{j} \hat{A}_{i j}$,非线性激活函数 $\sigma$ 选择 PReLU。
对于随机变换函数 $C$ ,直接采用 $ \widetilde{A}=A$,但是 $ \widetilde{X}$ 是由原本的特征矩阵 $X$ 经过随机变换得到的。
大图上的归纳式学习Inductive learning
对于归纳学习,不在编码器中使用 GCN 更新规则(因为学习的滤波器依赖于固定的和已知的邻接矩阵);相反,我们应用平均池( mean-pooling)传播规则,GraphSAGE-GCN:
$\operatorname{MP}(\mathbf{X}, \mathbf{A})=\hat{\mathbf{D}}^{-1} \hat{\mathbf{A}} \mathbf{X} \Theta$
$\widehat{D} ^{-1}$ 实际上执行的是标准化的和(因此是 mean-pooling)。
对于 Reddit 数据库,DGI 的编码器是一个带有跳跃连接的三层均值池模型:
$\widetilde{\mathrm{MP}}(\mathbf{X}, \mathbf{A})=\sigma\left(\mathbf{X} \Theta^{\prime} \| \operatorname{MP}(\mathbf{X}, \mathbf{A})\right) \quad \mathcal{E}(\mathbf{X}, \mathbf{A})=\widetilde{\mathrm{MP}}_{3}\left(\widetilde{\mathrm{MP}}_{2}\left(\widetilde{\mathrm{MP}}_{1}(\mathbf{X}, \mathbf{A}), \mathbf{A}\right), \mathbf{A}\right)$
这里 || 是拼接操作,由于数据集的规模很大,将不能完全适合 GPU内存。因此,采用 子抽样(subsampling)方法,首先选择小批量的节点,然后,通过对具有替换的节点邻域进行抽样,得到以每个节点为中心的子图。具体来说,DGI 在第一层、第二层和第三层分别采样 10、10 和 25 个邻居,这样每次采样的 patch 有 1 + 10 + 100 + 2500 = 2611 个节点。只进行了推导中心节点 $i$ 的 patch 表示 $h_I$ 所必需的计算。这些表示然后被用来为 minibatch(图2)导出总结向量 $\overrightarrow{s} $ 。在整个训练过程中使用了 256 个节点的 minibatch 。
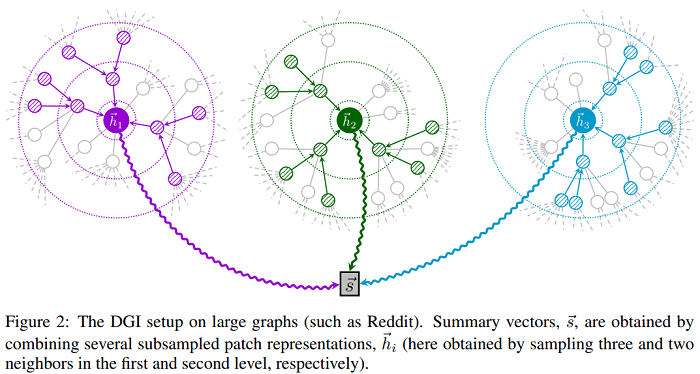
图2中,摘要向量 $\vec{s} $ 是通过组合几个子采样的邻近表示 $\vec{h}_{i} $ 得到的。
多图上的归纳式学习
例如 PPI 数据集,编码器是一个带有密集跳过连接的三层均值池模型
$\mathbf{H}_{1}=\sigma\left(\operatorname{MP}_{1}(\mathbf{X}, \mathbf{A})\right)$
$\mathbf{H}_{2}=\sigma\left(\mathbf{M P}_{2}\left(\mathbf{H}_{1}+\mathbf{X} \mathbf{W}_{\text {skip }}, \mathbf{A}\right)\right)$
$\mathcal{E}(\mathbf{X}, \mathbf{A})=\sigma\left(\mathbf{M P}_{3}\left(\mathbf{H}_{2}+\mathbf{H}_{1}+\mathbf{X} \mathbf{W}_{\text {skip }}, \mathbf{A}\right)\right)$
其中,$W_{skip}$ 是一个可学习的投影矩阵。
在这个多图设置中,DGI 选择使用随机抽样的训练图作为负样本(即,DGI 的破坏函数只是从训练集中抽样一个不同的图)。作者发现该方法是最稳定的,因为该数据集中超过 40% 的节点具有全零特征(all-zero features)。为了进一步扩大负样本池,作者还将 dropout 应用于采样图的输入特征。作者发现,在将学习到的嵌入信息提供给逻辑回归模型之前,将其标准化是有益的。
结果
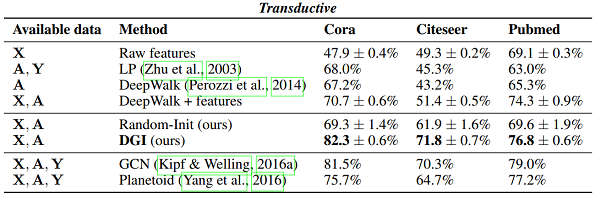
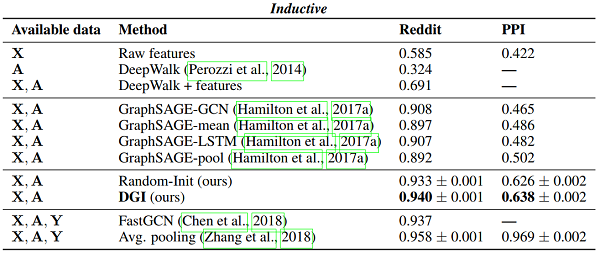
根据分类准确性(在 transductive tasks)或 micro-averaged $F_1$ score(在归纳任务)的结果总结。在第一列中,我们突出显示了训练期间每个方法可用的数据类型(X:特征,A:邻接矩阵,Y:标签)。"GCN" 对应于以监督方式训练的两层 DGI 编码器。

修改历史
2021-03-25 创建文章
2022-05-21 二次修改
2022-06-10 精读
相关文章
- mac及Windows系统禁止Chrome浏览器更新
- pip安装超时问题
- 爬虫学习--http请求详解
- Centos 配置eth0 提示Device does not seem to be present
- 判定表法测试用例设计
- 非关系型数据库(nosql)介绍
- 性能调优命令之vmstat
- 浅谈 DML、DDL、DCL的区别
- SQL优化
- Appium定位方式总结
- 移动端自动化测试-AppiumApi接口详解及常用adb命令
- 移动端自动化测试-WTF Appium?
- Selenium-Css Selector使用方法
- Selenium-Switch与SelectApi接口详解
- Selenium-ActionChains Api接口详解
- Selenium-WebDriverApi接口详解
- Selenium之前世今生
- Xpath使用方法
- Selenium-WebDriver驱动对照表
- HTML基础之DOM操作