
【Selenium学习】Selenium 八大定位法
1.1 ID定位
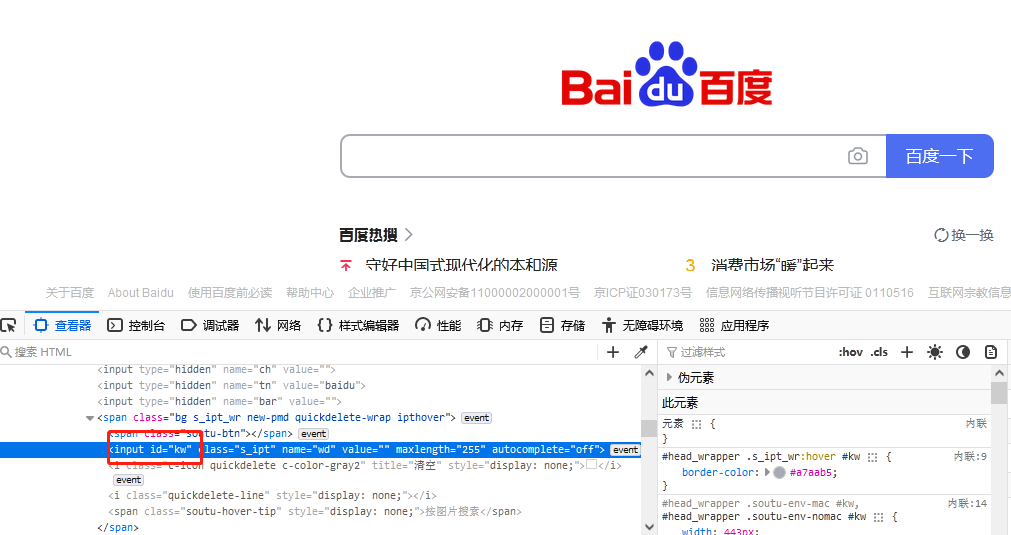
HTML Tag 的 id 属性值是唯一的,故不存在根据 id 定位多个元素的情况。下面以在百度首页搜索框输入文本“python”为例。搜索框的 id 属性值为“kw”,如图1.1所示:
代码如下,“find_element_by_id”方法已废弃,使用find_element(By.ID, 'kw')
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# 需要将浏览器驱动添加到环境变量中
# 打开百度
driver.get('https://www.baidu.com/')
# 通过id,在搜索输入框中输入文本“python”
driver.find_element(By.ID, 'kw').send_keys('python')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.2 name 定位
以上百度搜索框也可以用 name 来实现,如图 1.1 所示,其 name 属性值为“wd”,方法“find_element(By.NAME, 'wd')”表示通过 name 来定位
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过name,在搜索输入框中输入文本“自动化测试”
driver.find_element(By.NAME, 'wd').send_keys('自动化测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()注意:用 name 方式定位需要保证 name 值唯一,否则定位失败。
1.3 class 定位
以百度首页搜索框为例,如图 1.1所示,其 class 属性值为“s_ipt”,“By.CLASS_NAME, 's_ipt'”表示通过 class_name 来定位
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过class,在搜索输入框中输入文本“web测试”
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('web测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.4 link_text 定位
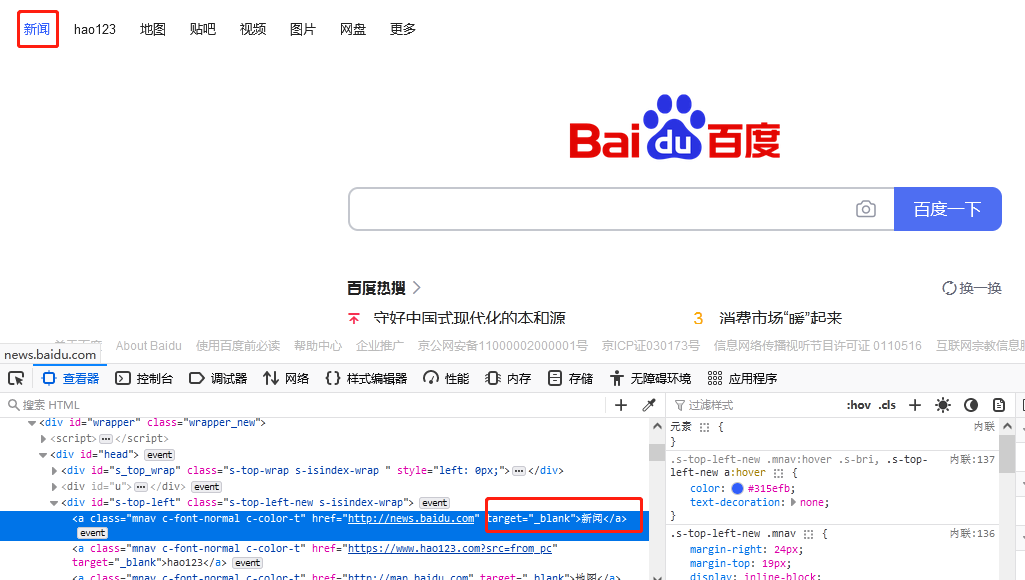
link_text 是以超链接全部名字作为关键字来定位元素的。以百度首页“新闻”超链接为例,如图 1.2 所示,关键字为“新闻”。
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过link_text定位,点击‘新闻’超链接
driver.find_element(By.LINK_TEXT, '新闻').click()
# 关闭浏览器
driver.close()注意:用此方法定位元素超链接,中文字需要写全。
1.5 partial_link_text 定位
即用超链接文字的部分文本来定位元素,类似数据库的模糊查询。以“新闻”超链接为例,只需“新”一个字即可,即取超链接全部文本的一个子集。
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过partial_link_text定位,用超链接文字的部分文本来定位元素,类似数据库的模糊查询
driver.find_element(By.PARTIAL_LINK_TEXT, '新').click()
# 关闭浏览器
driver.close()1.6 tag_name 定位
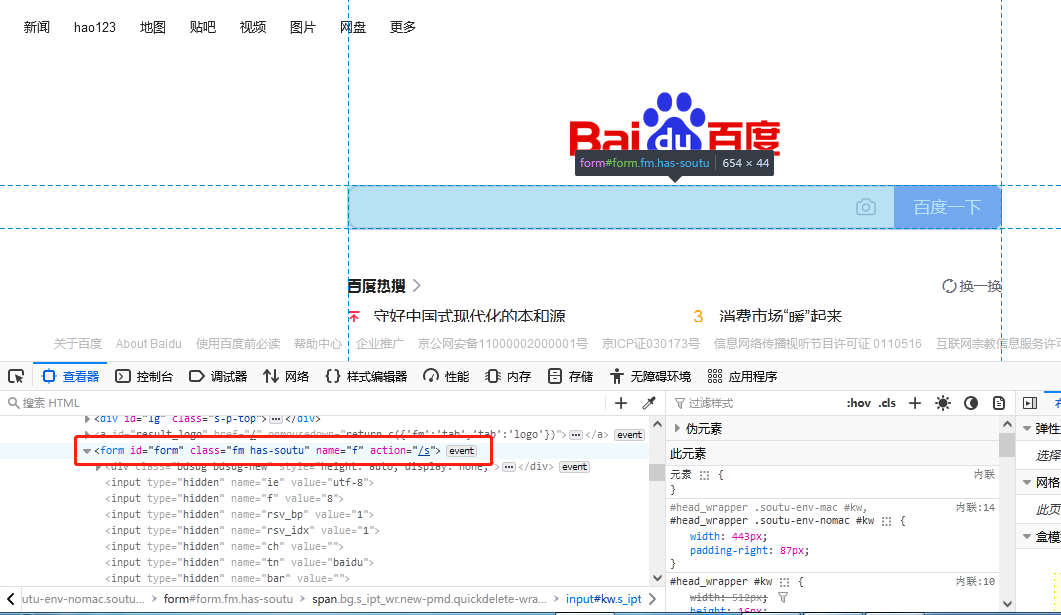
tag_name 定位即通过标签名称定位,如图 1.6所示,定位标签“form”并打印标签属性值“name”。
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# tag_name 定位即通过标签名称定位
print(driver.find_element(By.TAG_NAME, 'form').get_attribute('name'))成功后控制台输出“f”:

1.7 CSS 定位
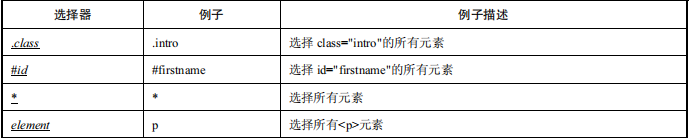
CSS 定位的优点是速度快、语法简洁。表 1.1 中的内容出自 W3School 的 CSS 参考手册。CSS 定位的选择器有十几种,在本节中主要介绍几种比较常用的选择器。
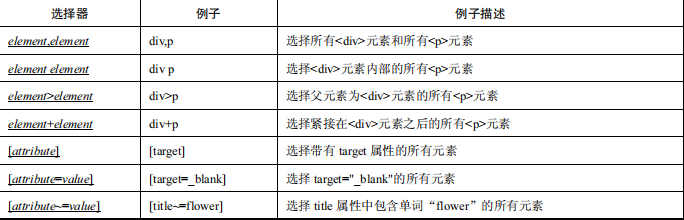
仍以百度搜索框为例,代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 以class选择器为例,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '.s_ipt').send_keys('python3')
# 以id定位语法结构为:#加 id 名,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('python3')
# CSS 定位主要利用属性 class 和 id 进行元素定位。也可以利用常规的标签名称来定位,如输入框标签“input”,在标签内部又设置了属性值为“name=’wd’”
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# CSS 定位方式可以使用元素在页面布局中的绝对路径来实现元素定位。百度首页搜索输入框元素的绝对路
# 径为“html>body>div>div>div>div>div>form>span>input[name="wd"]”
driver.find_element(By.CSS_SELECTOR, 'html>body>div>div>div>div>div>form>span>input[name="wd"]').send_keys('python3')
# CSS 定位也可以使用元素在页面布局中的相对路径来实现元素定位。相对路径的写法和直接利用标签名称来定位,两者
# 的代码实现的功能是一致的
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.8 XPath 定位
通过 XPath 来定位元素的方式,对比较难以定位的元素来说很有效,几乎都可以解决,特别是对于有些元素没有 id、name 等属性的情况。
XPath 是 XML Path 语言的缩写,是一种用来确定 XML 文档中某部分位置的语言。它在 XML 文档中通过元素名和属性进行搜索,主要用途是在 XML 文档中寻找节点。XPath定位比 CSS 定位有更大的灵活性。XPath 可以向前搜索也可以向后搜索,而 CSS 定位只能向前搜索,但是 XPath 定位的速度比 CSS 慢一些。
XPath 语言包含根节点、元素、属性、文本、处理指令、命名空间等。以下文本为 XML实例文档,用于演示 XML 的各种节点类型,便于理解 XPath。
<?xml version = "1.0" encoding = "utf-8" ?>
<!-- 这是一个注释节点 -->
<animalList type="mammal">
<animal categoruy = "forest">
<name>Tiger</name>
<size>big</size>
<action>run</action>
</animal>
</animalList>其中<animalList>为文档节点,也是根节点;<name>为元素节点;type=“mammal”为属性节点。
节点之间的关系:
• 父节点。每个元素都有一个父节点,如上面的 XML 示例中,animal 元素是 name、size,以及 action 元素的父节点。
• 子节点。与父节点相反,这里不再赘述。
• 兄弟节点,有些也叫同胞节点。它表示拥有相同父节点的节点。如上代码所示,name、size 和 action 元素都是同胞节点。
• 先辈节点。它是指某节点的父节点,或者父节点的父节点,以此类推。如上代码所示,name 元素节点的先辈节点有 animal 和 animalList。
• 后代节点。它表示某节点的子节点、子节点的子节点,以此类推。如上代码所示,animalList 元素节点的后代节点有 animal、name 等。
仍以百度搜索框为例,代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# XPath 有多种定位策略,最简单直观的就是写出元素的绝对路径。
driver.find_element(By.XPATH, '/html/body/div/div/div/div/div/form/span/input').send_keys('python3')
# XPath还可以使用元素的属性值来定位。//input 表示当前页面某个 input 标签,[@id='kw'] 表示这个元素的 id 值是 kw。
driver.find_element(By.XPATH, "//input[@id='kw']").send_keys('python3')
# 如果一个元素本身没有可以唯一标识这个元素的属性值,我们可以查找其上一级元素。
# form[@class='fm has-soutu']通过 class 定位到父元素,后面的/span/input 表示父元素下面的子元素。
driver.find_element(By.XPATH, "//form[@class='fm has-soutu']/span/input").send_keys('python3')
# 如果一个属性不能唯一区分一个元素,那么我们可以使用逻辑运算符连接多个属性来查找元素
driver.find_element(By.XPATH, "//input[@id='kw' and @class='s_ipt']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()本章主要介绍了 Selenium 元素的八大定位,每一种定位方式都有其特殊的用法,读者只要掌握其特殊性即可。需要在项目中多用多想、总结经验,时间久了会对这些定位方式有更深的理解。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合