
Pytorch介绍以及基本使用、深入了解、案例分析。
目录
前言
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程,相比于Tensorflow,Pytorch简介易用。一、为什么选择Pytorch
简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
速度:PyTorch 的灵活性不以速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras 等框架。
易用:PyTorch 是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称。
生态丰富:PyTorch 提供了完整的文档,循序渐进的指南,此外 ,相关社区还在逐渐壮大。
二、Pytorch的基本使用
2-0、张量的定义
张量:张量是一种特殊的数据结构,与Numpy中的arrays非常相似,在Pytorch中,我们使用张量对模型的输入和输出以及模型的参数进行编码。最重要的是,数据转化为张量可以方便在GPU上运行,这样运行速度可以大大加快。
注意:Tensors和Numpy中的数组具有底层内存共享,意味着不需要进行复制直接就可以相互转化。
2-1、直接创建张量
2-1-1、torch.Tensor()
import torch
torch.Tensor([1, 2, 3])
# 涉及到的参数
# data:data的数据类型可以是列表list、元组tuple、numpy数组ndarray、纯量scalar(又叫标量)和其他的一些数据类型。
# dtype:该参数可选参数,默认为None,如果不进行设置,生成的Tensor数据类型会拷贝data中传入的参数的数据类型,比如data中的数据类型为float,则默认会生成数据类型为torch.FloatTensor的Tensor。
# device:该参数可选参数,默认为None,如果不进行设置,会在当前的设备上为生成的Tensor分配内存。
# requires_grad:该参数为可选参数,默认为False,在为False的情况下,创建的Tensor不能进行梯度运算,改为True时,则可以计算梯度。
# pin_memory:该参数为可选参数,默认为False,如果设置为True,则在固定内存中分配当前Tensor,不过只适用于CPU中的Tensor。
输出:
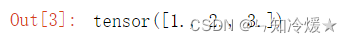
2-1-2、torch.from_numpy()
# notice: 当然我们也可以直接将numpy数组直接转化为Tensor
import torch
import numpy as np
t1 = [1, 2, 3]
np_array = np.array(t1)
data = torch.from_numpy(np_array)
print(data)
输出:
2-2、创建数值张量
2-2-1、torch.ones()
# 创建全1张量。
torch.ones((2,4))
输出:

2-2-2、torch.full()
torch.full([2,3],2.0)
参数:
# size: 定义了输出张量的形状。
# full_value: 定义填充的值。
输出:

2-2-3、torch.arange()
# 创建等差数列
torch.arange(0, 10, 2)
参数:
start: 等差数列开始。
end: 等差数列结束。
steps: 等差数列的差是多少。
输出:

2-2-4、torch.linespace()
# 创建线性间距向量
torch.linspace(2, 10, 5)
# 参数:
# start: 起始位置
# end: 结束位置
# steps: 步长
# out: 结果张量
输出:

2-2-5、torch.eye()
# 创建对角矩阵
# 即生成对角线全为1,其余部分全为0的二维数组
torch.eye(10,3)
# 参数:
# n: 行数
# m: 列数
# out: 输出类型,即输出到哪个矩阵。
输出:

2-3、根据概率创建张量
2-3-1、torch.randn()
# 创建随机值
# 与rand不同的是,它创建的是包含了从标准正态分布(均值为0,方差为1)中取出的一组随机值。
torch.randn(4)
# 参数
# size: 定义了输出张量的形状
# out: 结果张量
输出:

2-3-2、torch.randint()
# 返回一个填充了随机整数的张量,这些整数在low和high之间均匀生成。张量的shape由参数size定义。
torch.randint(100,size=(10,10))
# 参数说明:
# 常用参数:
# low ( int , optional ) – 要从分布中提取的最小整数。默认值:0。
# high ( int ) – 高于要从分布中提取的最高整数。
# size ( tuple ) – 定义输出张量形状的元组。
# 关键字参数:
# generator ( torch.Generator, optional) – 用于采样的伪随机数生成器
# out ( Tensor , optional ) – 输出张量。
# dtype ( torch.dtype , optional) – 如果是None,这个函数返回一个带有 dtype 的张量torch.int64。
# layout ( torch.layout, optional) – 返回张量的所需布局。默认值:torch.strided。
# device ( torch.device, optional) – 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(请参阅torch.set_default_tensor_type())。device将是 CPU 张量类型的 CPU 和 CUDA 张量类型的当前 CUDA 设备。
# requires_grad ( bool , optional ) – 如果 autograd 应该在返回的张量上记录操作。默认值:False。
输出:

2-3-3、torch.rand()
# 创建随机值,包含了从区间(0,1)的均匀分布中抽取的一组随机数
# 均匀分布
# torch.rand(*sizes, out=None)
torch.rand(4)
输出:

2-3-4、torch.normal()
torch.normal: 生成正态分布
四种模式:
1、mean为标量,std为标量。
2、mean为标量,std为张量。
3、mean为张量,std为标量。
4、mean为张量,std为张量。
# mean为标量,std为标量,这种模式必须加size参数
torch.normal(0, 1, size=(4,5))
输出:

2-4、张量的一些运算操作:拼接、切分索引变换
2-4-0、判断电脑是否有GPU
# 如果没有这一步可以直接略过
# 判断当前环境GPU是否可用, 然后将tensor导入GPU内运行
if torch.cuda.is_available():
tensor = tensor.to('cuda')
2-4-1、torch.ones_like函数和torch.zeros_like函数
input = torch.rand(4, 6)
print(input)
# 生成与input形状相同、元素全为1的张量
a = torch.ones_like(input)
print(a)
# 生成与input形状相同、元素全为0的张量
b = torch.zeros_like(input)
print(b)
输出:

2-4-2、torch.cat函数
# 生成一个两行三列的全1张量。
t = torch.ones((2,3))
# 拼接函数cat
# 在给定维度上对输入的张量进行连接操作
torch.cat([t,t], dim=0)
# 参数
# inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列
# dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
2-4-3、torch.stack函数
# 拼接函数stack
# 与cat不同的是,stack会增加维度。 简单来说就是增加新的维度进行堆叠。
# 扩维拼接!
torch.stack([t,t], dim=1)
# 参数
# inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列
# dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
输出:

2-4-4、torch.chunk函数
t = torch.ones((2,5))
# 在给定维度上将输入张量进行分块
torch.chunk(t, dim=1, chunks=5)
# input:被分块的张量。
# chunks:要切的份数。
# dim:在哪个维度上切分。
输出:

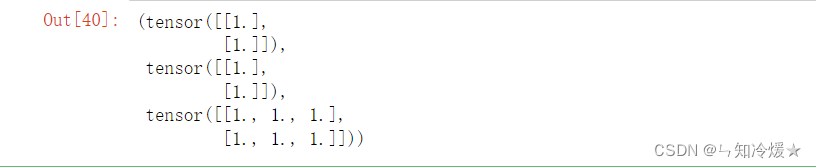
2-4-5、torch.split函数
# 将tensor分成块结构
torch.split(t, [1,1,3], dim=1)
# input:待输入张量
# split_size_or_sections: 需要切分的大小,可以为列表或者数字。
# dim:切分维度
输出:
2-4-6、torch.squeeze函数
# 返回一个删除了所有大小为1的输入维度的张量。
# 例如:如果输入为(A✖B✖1✖C),则输出张量为(A✖B✖C)
# input: 输入张量
# dim: 如果给定,则输入只会在这个维度上挤压。
2-4-7、自动赋值运算
# 自动赋值运算通常在方法后有 _ 作为后缀, 例如: x.copy_(y), x.t_()操作会改变 x 的取值。
print(tensor, "
")
tensor.add_(5)
print(tensor)

2-5、其他常用函数
2-5-1、torch.manual_seed
# 设置生成随机数的种子
# 为了使得结果可以复现。
# 参数:seed,设置的种子。
三、深入了解Pytorch
3-0、训练神经网络
背景:神经网络(NN:Neutral NetWork)是在某些输入数据上执行的嵌套函数的集合。 这些函数由参数(由权重和偏差组成)定义,这些参数在 PyTorch 中存储在张量中。
训练 NN 分为两个步骤:
正向传播:在正向传播中,NN 对正确的输出进行最佳猜测。 它通过其每个函数运行输入数据以进行猜测。即通过模型的每一层运行输入数据以进行预测。 这是正向传播。
反向传播:在反向传播中,NN 根据其猜测中的误差调整其参数。 它通过从输出向后遍历,收集有关函数参数(梯度)的误差导数并使用梯度下降来优化参数来实现。
3-1、叶子节点
叶子节点:用户创建的节点被称之为叶子节点。(即Tensor有一个属性,叫is_leaf。) 所以可以Tensor调用is_leaf属性来判断是否为叶子节点,只有叶子节点才有梯度。非叶子节点的梯度在运行后会被直接释放掉。依赖于叶子节点的节点 requires_grad默认为True。
requires_grad:即是否需要计算梯度,当这个值为True时,我们将会记录tensor的运算过程并为自动求导做准备。,但是并不是每个requires_grad()设为True的值都会在backward的时候得到相应的grad.它还必须为leaf。只有是叶子张量的tensor在反向传播时才会将本身的grad传入到backward的运算中,如果想得到其他tensor在反向传播时的grad,可以使用retain_grad()这个属性。
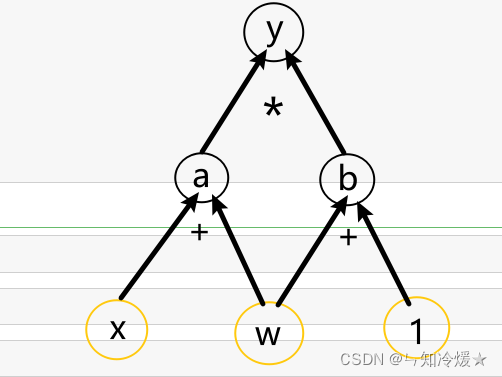
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
# last 计算w的梯度
w.grad
# tensor([5.])
计算图:
3-2、动态图与静态图
1、动态图:运算与搭建同时进行,容易调节。 Pytorch采用动态图机制。
2、静态图:先搭建图,后运算,高效,但是不灵活。 Tensorflow采用静态图机制。
3-3、自动求梯度(autograd)
前言:神经网络通常依赖反向传播求梯度来更新网络参数,深度学习框架可以帮助我们自动地完成这种梯度运算。 Pytorch一般通过反向传播方法backward来实现梯度计算。除此以外,也可以调用torch.autograd.grad函数来实现梯度计算。
注意:backward方法通常在一个标量张量上调用,该方法求得的梯度将存在对应自变量张量的grad属性下。如果调用的张量非标量,则要传入一个和它同形状的gradient参数张量。相当于用该gradient参数张量与调用张量作向量点乘,得到的标量结果再反向传播。
案例一:backward方法在一个标量张量上调用。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
# last 计算w的梯度
w.grad
# tensor([5.])
案例二:backward方法在非标量的反向传播
# 如果调用的张量非标量,则要传入一个和它同形状的gradient参数张量。相当于用该gradient参数张量与调用张量作向量点乘,得到的标量结果再反向传播。
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c
x = torch.tensor([[0.0,0.0],[1.0,2.0]],requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
print("x:",x)
print("y:",y)
y.backward(gradient = gradient)
x_grad = x.grad
print("x_grad:",x_grad)
输出:
x: tensor([[0., 0.],
[1., 2.]], requires_grad=True)
y: tensor([[1., 1.],
[0., 1.]], grad_fn=)
x_grad: tensor([[-2., -2.],
[ 0., 2.]])
案例三:使用autograd.grad方法来求导数。
torch.autograd.backward: 求梯度。
参数:
outputs:用于求导的张量
inputs:需要梯度的张量
create_graph: 创建导数计算图,用于高阶求导
retain_graph: 保存计算图
grad_outputs: 多梯度权重
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的导数
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
# create_graph 设置为 True 将允许创建更高阶的导数
dy_dx = torch.autograd.grad(y,x,create_graph=True)[0]
print(dy_dx.data)
# 求二阶导数
dy2_dx2 = torch.autograd.grad(dy_dx,x)[0]
print(dy2_dx2.data)
输出:
tensor(-2.)
tensor(2.)
3-4、前向传播、损失和反向传播(Numpy实现)
# 为了加深对于前向传播、损失和反向传播的理解,我们使用Numpy来实现这个流程
import numpy as np
import math
# Create random input and output data
# 用于在线性空间中以均匀步长生成数字序列。
x = np.linspace(-math.pi, math.pi, 2000)
y = np.sin(x)
# 随机初始化权重
# Randomly initialize weights
a = np.random.randn()
b = np.random.randn()
c = np.random.randn()
d = np.random.randn()
# 学习率设置为1e-6
learning_rate = 1e-6
for t in range(5000):
# Forward pass: compute predicted y
# y = a + b x + c x^2 + d x^3
# 预测函数,结果呢,就是得到a、b、c、d四个值使得预测值y_pred尽可能接近y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss
# 损失函数,就是预测值减去真实值求和,再开方。
loss = np.square(y_pred - y).sum()
# 每100次,输出轮次和损失
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
# 分别计算a、b、c、d的梯度。
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# Update weights
# 更新a、b、c、d四个参数
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
print(f'Result: y = {a} + {b} x + {c} x^2 + {d} x^3')

3-5、前向传播、损失和反向传播(Pytorch实现)
import torch
import math
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create random input and output data
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# Randomly initialize weights
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)
learning_rate = 1e-6
for t in range(2000):
# Forward pass: compute predicted y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss
#
grad_y_pred = 2.0 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# Update weights using gradient descent
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
3-6、前向传播、损失和反向传播(使用PyTorch Autograd 来计算梯度)
import torch
import math
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create Tensors to hold input and outputs.
# By default, requires_grad=False, which indicates that we do not need to
# compute gradients with respect to these Tensors during the backward pass.
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# Create random Tensors for weights. For a third order polynomial, we need
# 4 weights: y = a + b x + c x^2 + d x^3
# Setting requires_grad=True indicates that we want to compute gradients with
# respect to these Tensors during the backward pass.
# 这里设置requires_grad为True,即需要计算梯度
a = torch.randn((), device=device, dtype=dtype, requires_grad=True)
b = torch.randn((), device=device, dtype=dtype, requires_grad=True)
c = torch.randn((), device=device, dtype=dtype, requires_grad=True)
d = torch.randn((), device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6
for t in range(2000):
# Forward pass: compute predicted y using operations on Tensors.
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss using operations on Tensors.
# Now loss is a Tensor of shape (1,)
# loss.item() gets the scalar value held in the loss.
loss = (y_pred - y).pow(2).sum()
if t % 100 == 99:
print(t, loss.item())
# Use autograd to compute the backward pass. This call will compute the
# gradient of loss with respect to all Tensors with requires_grad=True.
# After this call a.grad, b.grad. c.grad and d.grad will be Tensors holding
# the gradient of the loss with respect to a, b, c, d respectively.
# 使用autograd来进行反向传播,计算损失梯度以及各个Tensor的梯度,使用.grad来调用梯度。
loss.backward()
# Manually update weights using gradient descent. Wrap in torch.no_grad()
# because weights have requires_grad=True, but we don't need to track this
# in autograd.
# 使用梯度下降手动更新权重。
with torch.no_grad():
a -= learning_rate * a.grad
b -= learning_rate * b.grad
c -= learning_rate * c.grad
d -= learning_rate * d.grad
# Manually zero the gradients after updating weights
# 在更新梯度之前,将梯度手动设置为0
a.grad = None
b.grad = None
c.grad = None
d.grad = None
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
四、数据读取机制Dataloader与Dataset
Dataloader方法:
# torch.utils.data.DataLoader
# 参数:
# dataset: Dataset类,决定数据从哪读取以及如何读取
# batchsize:批大小
# num_works: 是否多进程读取数据
# shuffle: 每个epoch是否乱序
# drop_last: 当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch、Iteration、Batchsize的含义:
# Epoch:所有训练样本都输入到模型中,称为一个Epoch
# Iteration: 一批样本输入到模型中,称之为一个Iteration
# Batchsize: 批大小,决定一个Epoch有多少个Iteration
五、数据预处理transforms模块机制
transforms: 图像预处理模块,对数据进行增强,即对训练集进行变换,使得模型的泛化能力更强。
# torchvision.transforms: 图像预处理模块
# torchvision.datasets: 常用数据集的dataset实现
# torchvision.model: 常用的模型与训练
# transforms: 数据中心化、标准化、缩放、裁剪、旋转、翻转、填充、噪声添加、灰度变换、线性变换、仿射变换、亮度、饱和度以及对比度变换。
# transforms.ToTensor(): 用于对载入的图片数据进行类型转换,把之前构成PIL图片的数据转换成Tensor数据类型的变量,让Pytorch能够对其进行计算和处理。
# transforms.Compose():可以被看做是一种容器,将数据处理方法组合到一起
# transforms.RandomCrop(): 随机裁剪,对于载入的图片按照我们需要的大小进行随机裁剪。如果传入的是一个整型数据,那么裁剪的长和宽都是这个数值。
# transforms.Normalize(): 数据标准化,这里使用的是标准正态分布变换,这种方法需要使用原始数据的均值(Mean)和标准差(Standard Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布。参数mean、std,列表形式,如mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], 思考:这里mean和std要在normalize之前自己算好再传进去,否则每次标准化之前都需要把所有的图片都读取一遍再算这两个。
# 功能:逐channel的对图像进行标准化
# output = (input - mean) /std
# mean: 各通道的均值
# std: 各通道的标准差
# inplace: 是否原地操作
六、如何使用CIFAR10数据集
6-1、加载数据
import torch
import torchvision
import torchvision.transforms as transforms
# 每次图像数据先进行ToTensor,即将数据归一化到[0,1](即将数据除以255——缩小范围),之后再进行一个标准化,即减去均值,除以方差,这样可
# 以让数据服从正态分布。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# root:数据集位置
# train:数据集状态,True为训练集,False为测试集
# download: 是否下载数据集,transform: 针对数据集做出的一些变换
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# 数据读取的一个重要接口: 将自定义的数据或者Pytorch已有的数据按照batch size封装成Tensor。
# batch_size :每个batch多少个样本
# shuffle (bool, optional) – 设置为True时会在每个epoch重新打乱数据(默认: False).
# num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
6-2、展示部分图像
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
# iter: 用来生成迭代器
dataiter = iter(trainloader)
# 得到迭代器的下一个数据
images, labels = dataiter.next()
# show images
# torchvision.utils.make_grid(): 组成图像的网络
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

6-3、定义卷积神经网络、损失函数以及优化器
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
6-4、训练网络
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')

6-5、保存训练过的模型
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
6-6、加载模型
net = Net()
net.load_state_dict(torch.load(PATH))
6-7、网络在整个数据集上的表现
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 53 %
6-8、在哪些类的表现良好,哪些类的表现不佳
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Accuracy of plane : 50 %
Accuracy of car : 62 %
Accuracy of bird : 51 %
Accuracy of cat : 32 %
Accuracy of deer : 31 %
Accuracy of dog : 35 %
Accuracy of frog : 77 %
Accuracy of horse : 70 %
Accuracy of ship : 71 %
Accuracy of truck : 52 %
更多Transform模块方法详见博客。
Pytorch:transforms二十二种数据预处理方法及自定义transforms方法.
参考文章:
pytorch简介.
PyTorch 的基本使用.
Pytorch基础–torch.Tensor.
torch.randn和torch.rand有什么区别.
pytorch 之 torch.eye()函数.
torch.randint().
torch.stack()的官方解释,详解以及例子.
torch.split().
【one way的pytorch学习笔记】(三)leaf 叶子(张量).
pytorch 中autograd.grad()函数的用法说明.
使用 PYTORCH 进行深度学习:60 分钟的闪电战.
NEURAL NETWORKS.
训练分类器.
Pytorch相关课程-4
重要:!!!PyTorch 中文教程 & 文档.
PyTorch中文教程&文档.
总结
今天是周五哎,好耶。
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击