
CVPR最有趣论文 | 再模糊的照片AI都可以可以恢复
生活中,我们都会遇到图片模糊状态下,很早之前我们是不可能恢复;之后通过PS进行修复,也会有畸形或者差异的表现;但是,现在AI可以准确完整的恢复出blind face。
一、简要

B lind face 通常依赖于facial priors,如facial geometry prior或reference prior,来恢复现实和真实的细节。然而,当高质量的参考无法访问时,非常低质量的输入不能提供精确的几何先验,这限制了在现实场景中的适用性。
所以,有研究者提出了GFP-GAN,它利用封装在预先训练好的人脸GAN中的丰富多样的先验来进行blind face恢复。该Generative Facial Prior(GFP)通过新的信道分裂空间特征变换层融入到人脸修复过程中,使新方法能够实现真实度和保真度的良好平衡。由于强大的 GFP 和精细的设计,GFP-GAN可以通过一次共同恢复面部细节和增强颜色,而GAN inversion methods在推理时需要昂贵的特定图像优化。大量的实验表明,新方法在合成数据集和真实数据集上都取得了优于现有技术的性能。
二、效果先知道

HiFaceGAN [ 69 ]: Lingbo Yang, Chang Liu, Pan Wang, Shanshe Wang, Peiran Ren, Siwei Ma, and Wen Gao. Hifacegan: Face renovation via collaborative suppression and replenishment. ACM Multimedia, 2020
DFDNet [ 46 ]: Xiaoming Li, Chaofeng Chen, Shangchen Zhou, Xianhui Lin, Wangmeng Zuo, and Lei Zhang. Blind face restoration via deep multi-scale component dictionaries. In ECCV, 2020
Wan et al. [ 63 ]: Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Bringing old photos back to life. In CVPR, 2020
PULSE [ 54 ]: Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, and Cynthia Rudin. Pulse: Self-supervised photo upsampling via latent space exploration of generative models. In CVPR, 2020
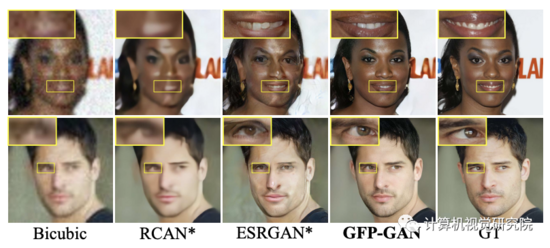
在本研究中,研究者利用GFP来进行现实世界的盲脸恢复,即先验隐式封装在预先训练的人脸生成对抗网络(GAN)模型中,如StyleGAN。这些face GANs能够产生具有高度变化的 faithful faces,从而提供丰富多样的先验,如几何,面部纹理和颜色,使它能够共同恢复面部细节和增强颜色(如上图)。
然而,将这种生成先验纳入恢复过程中是具有挑战性的。以前的尝试通常使用GAN inversion。他们首先将降级的图像“倒置”回预先训练好的GAN的 latent code,然后进行昂贵的特定于图像的优化来重建图像。尽管在视觉上有真实的输出,但它们通常会产生低保真度的图像,因为低维的 latent code不足以引导精确的恢复。
三、新框架
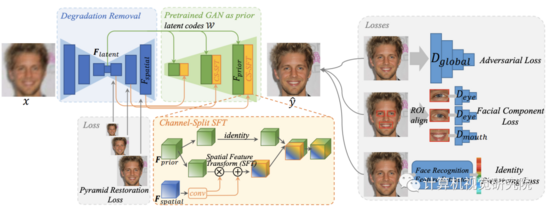
GFP-GAN 框架的概述:它包括一个degradation removal模块和一个预先训练好的face GAN作为 facial prior。它们由latent code映射和几个Channel-Split Spatial Feature Transform(CSSFT)层。所提出的CS-SFT调制实现了良好的保真度和保真度平衡。在训练过程中,使用1)Pyramid restoration引导来消除现实世界中复杂的退化,2)Facial component损失和识别器来增强面部细节,3) identity preserving损失以保持面部身份。
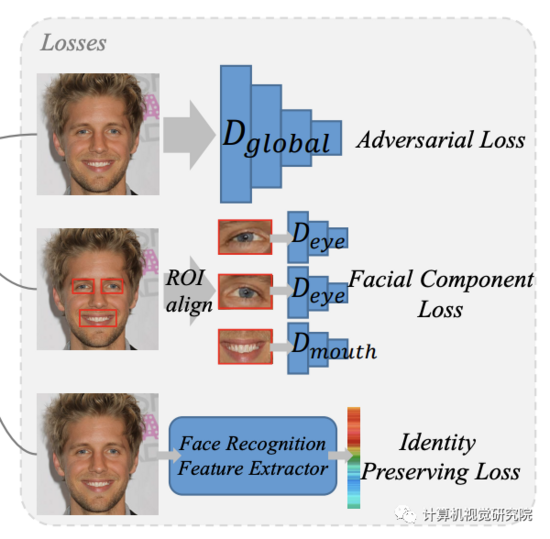
Adversarial Loss

Facial Component Loss

Identity Preserving Loss
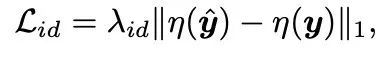
总体模型目标是上述损失的组合:
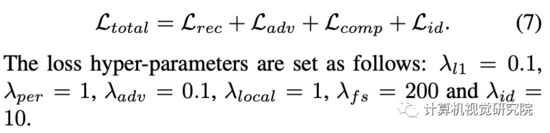
训练数据
和之前大部分工作类似,GFP-GAN采用了Synthetic数据的训练方式。研究者们发现在合理范围的Synthetic数据上训练, 能够涵盖大部分的实际中的人脸。GFP-GAN的训练采用了经典的降质模型, 即先高斯模糊, 再降采样 , 然后加噪声, 最后使用JPEG压缩。
四、实验及效果可视化

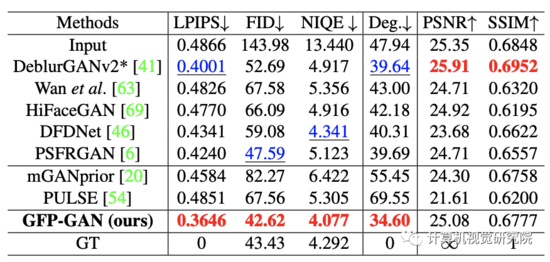
在Synthetic的量化 指标上, 该研究提出的方法在LPIPS、FID、 NIQE都能够取得最好的结果,Deg.是指人脸识别 模型ArcFace的Cosine距离, 较小的值说明identity也保持的很好。


相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合