
论文解读(RDGCN)《Region-enhanced Deep Graph Convolutional Networks for Rumor Detection》
论文信息
论文标题:Region-enhanced Deep Graph Convolutional Networks for Rumor Detection
论文作者:Ge Wang, Li Tan, Tianbao Song, Wei Wang, Ziliang Shang
论文来源:2202,arXiv
论文地址:download
论文代码:download
1 Introduction
同时考虑时间转发结构信息和深层模型的表达能力(并解决过平滑问题),同时还结合了无监督损失。
2 The Proposed Model
总体框架如下:
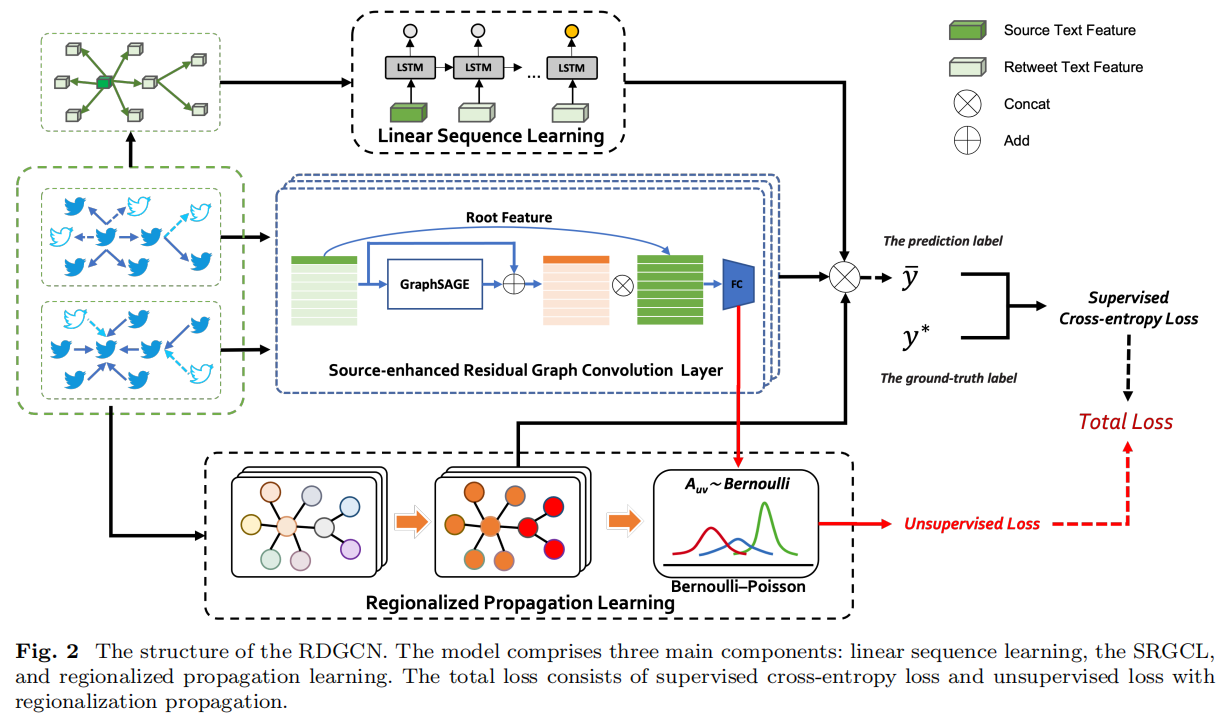
2.1 Linear Sequence Learning
信息和谣言在社交媒体上的传播形成了异构的传播结构,并包含了线性互动的特征。换句话说,公众对谣言声明的反应是动态的,而且会随着时间的推移而变化。由于上下文信息可以通过序列交互有效地解释信息随时间的扩散过程,本文提出了一种线性序列学习方法来聚合上下文节点的特征并表示序列传播。
$h_{N\left(v_{i}\right)}^{l s t m}=\operatorname{LSTM}\left(\left\{R_{i}, \forall R_{i} \in N\left(v_{i}\right)\right\}\right)$
2.2 Source-enhanced Residual Graph Convolution Layer
标准 GNN :
$\begin{array}{l}H_{l+1}=\mathcal{F}\left(H_{l}, \mathcal{W}_{l}\right) \\=\text { Update }\left(\text { Aggregate }\left(H_{l}, \mathcal{W}_{l}^{a g g}\right), \mathcal{W}_{l}^{\text {update }}\right)\end{array}$
ResGNN 解决过平滑问题:
$\begin{array}{l}H_{l+1}&=\mathcal{H}\left(H_{l}, \mathcal{W}_{l}\right) \\&=\mathcal{F}\left(H_{l}, \mathcal{W}_{l}\right)+H_{l}=H_{l+1}^{\text {res }}+H_{l}\end{array}$
考虑根节点特征增强:
$H_{l+1}^{\text {enhance }}=\text { concat }\left[H_{l+1},\left(H_{l}\right)^{\text {root }}\right]$
其中,$H_{0}=\mathbf{X}$。
完整的残差 GNN 框架(考虑不同方向的谣言传播树):
$\begin{array}{l}H_{l+1}^{T D}&=\mathcal{H}\left(H_{l}^{\text {enhance,TD }}, \mathcal{W}_{l}^{T D}\right) \\&=\mathcal{F}\left(H_{l}^{\text {enhance,TD }}, \mathcal{W}_{l}^{T D}\right)+H_{l}^{\text {enhance }, T D} \\&=H_{l+1}^{\text {res } T D}+H_{l}^{\text {enhance }, T D}\end{array}$
$H_{l+1}^{\text {enhance, } T D}=\text { concat }\left[H_{l+1}^{T D},\left(H_{l}^{\text {enhace }, T D}\right)^{\text {root }}\right]$
$\begin{array}{l}H_{l+1}^{B U}&=\mathcal{H}\left(H_{l}^{\text {enhance }, B U}, \mathcal{W}_{l}^{B U}\right) \\&=\mathcal{F}\left(H_{l}^{\text {enhance }, B U}, \mathcal{W}_{l}^{B U}{ }_{l}\right)+H_{l}^{\text {enhance }, B U} \\&=H_{l+1}^{\text {res }, B U}+H_{l}^{\text {enhance }, B U}\end{array}$
$H_{l+1}^{\text {enhance, } B U}=\text { concat }\left[H_{l+1}^{B U},\left(H_{l}^{\text {enhace }, B U}\right)^{\text {root }}\right]$
接着使用一个 FC 提升表示质量:
$H_{l+1}^{\text {enhance,TD }}=F C\left(H_{l+1}^{\text {enhance, } T D}\right)$
$H_{l+1}^{\text {enhance }, B U}=F C\left(H_{l+1}^{\text {enhance }, B U}\right)$
接着使用上述的节点嵌入矩阵生成图级表示:
$H_{l+1}^{\text {enhance }, B U}=F C\left(H_{l+1}^{\text {enhance }, B U}\right)$
$\mathbf{C}^{B U}=\text { meanpooling }\left(H^{B U}\right)$
2.3 Regionalized Propagation Learning
2.3.1 Regionalized Propagation Encoder
使用 GCN 编码图结构信息:
$F=G C N(\mathbf{A}, \mathbf{X})$
2.3.2 Bernoulli-Poisson model
由于在谣言检测中缺乏具有区域模式的相关标签,因此引入了 Bernoulli-Poisson(BP)模型来学习区域传播的无监督图生成模型。将传播区域特征的邻接矩阵 $A_{u v}$ 项采样为 $\text{Eq.15}$:
$A_{u v} \sim \operatorname{Bernoulli}\left(1-e^{-\left(F_{u}\left(F_{v}\right)^{\mathrm{T}}\right)}\right)$
其中,$F_{u}$ 和 $F_{v}$ 是节点 $u$ 和节点 $v$ 的传播模式表示特征。
BP模型的最大负对数似然估计:
$\begin{aligned}-\log p(A \mid F)=-\sum\limits_{(u, v) \in E} \log \left(1-e^{-\left(F_{u}\left(F_{v}\right)^{\mathrm{T}}\right)}\right)+\sum\limits_{(u, v) \notin E}\left(F_{u}\left(F_{v}\right)^{\mathrm{T}}\right)\end{aligned}$
为进一步符合传播图的传播模式,由于传播图通常是稀疏矩阵,因此上述方程的第二项对损失的贡献更大。然后通过使用不平衡分类方法平衡这两项的权重来抵消这一点:
$\begin{array}{c}\mathcal{L}(F)=-E_{(u, v) \sim P_{E}}\left[\sum \log \left(1-e^{-\left(F_{u}\left(F_{v}\right)^{\mathrm{T}}\right)}\right)\right] +E_{(u, v) \sim P_{N}}\left[F_{u}\left(F_{v}\right)^{\mathrm{T}}\right]\end{array}$
其中,$P_{E}$ 和 $P_{N}$ 表示图中边和非边的均匀分布。
此外,为了增强 SRGCL 在传播模式上的训练趋势,还将其隐藏层的的表示输入到 BP 模型中来计算损失。最终的无监督损失可以计算为:
$\begin{array}{r}\mathcal{L}_{\text {Unsupervised }}=\mathcal{L}(G C N(A, X)) +\frac{\sum\limits_{i=1,2 l l} \mathcal{L}\left(H_{i}^{\text {enhance,TD }}\right)}{l} +\frac{\sum\limits_{i=1,2 \ldots l} \mathcal{L}\left(H_{i}^{\text {enhance }, B U}\right)}{l}\end{array}$
正项函数:$-\log \left(1-e^{-\left(F_{u}\left(F_{v}\right)^{\mathrm{T}}\right)}\right)$
将每一层的表示法输入到BP模型中来计算损失。最终的无监督损失可以计算为:
${\large \begin{array}{r}\mathcal{L}_{\text {Unsupervised }}&=&\mathcal{L}(G C N(A, X)) \\&+&\frac{\sum_{i=1,2 l} \mathcal{L}\left(H_{i}^{\text {enhance,TD }}\right)}{l} \\&+&\frac{\sum_{i=1,2 \ldots l} \mathcal{L}\left(H_{i}^{\text {enhance }, B U}\right)}{l}\end{array}} $
2.4 Training
将残差结构生成的 图表示 $\mathbf{C}^{T D}$ 和 $\mathbf{C}^{B U}$ ,以及 考虑时间传播的信息生成的图级表示 $h_{N\left(v_{i}\right)}^{l s t m}$ ,以及无监督模块的 $F$ 来生成图标签 :
$\hat{\mathbf{y}}=\operatorname{softmax}\left(\mathbf{W}_{c}\left(\mathbf{C}^{T D} \oplus \mathbf{C}^{B U} \oplus h_{N\left(v_{i}\right)}^{\text {lstm }} \oplus F\right)+\mathbf{b}_{c}\right)$
然后,计算交叉熵分类损失:
$\mathcal{L}_{c}=-\sum\limits _{i}^{|\mathcal{Y}|} \mathbf{y}^{i} \log \hat{\mathbf{y}}^{i}$
总训练目标:
$\theta^{*}=\arg \underset{\theta}{\text{min}} \quad \gamma \mathcal{L}_{\text {supervised }}+(1-\gamma) \mathcal{L}_{\text {Unsupervised }}$
3 Experiment
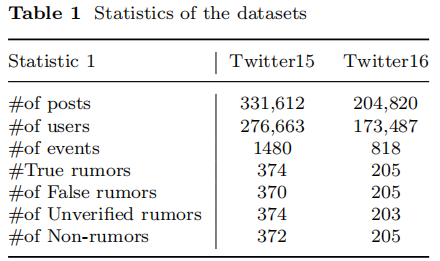
3.1 Datasets
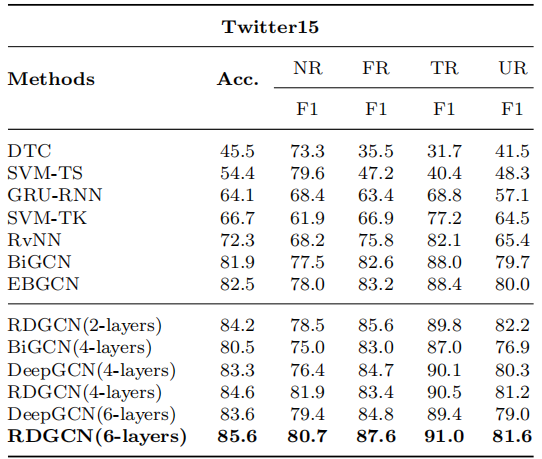
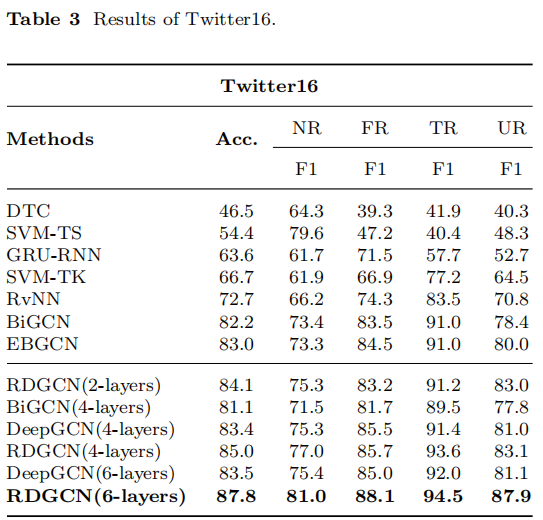
3.2 Results
相关文章
- 【Docker】搭建部署Redis高可用集群实验
- 【K8S】kubernetes概念和架构(一)
- 【K8S】基于Windows系统下使用minikube安装kubernetes集群
- PromQL的简单使用
- Prometheus基于文件的服务发现
- Prometheus重新标记
- Prometheus的单机部署
- Vim的简单使用
- SpringBoot整合kafka
- kafka生产者和消费者api的简单使用
- kafka错误之 Topic xxx not present in metadata after 60000 ms
- kafka的基本概念
- 处理微信回调事件
- 微信公众号开发接入
- kafka集群搭建
- Spring Cloud Alibaba Nacos Config 的使用
- Spring Cloud Gateway GatewayFilter的使用
- Spring Cloud Gateway Route Predicate Factory 的使用
- Charles的简单用法
- Spring Cloud Alibaba整合Sentinel