
【论文阅读】增量式物体检测
2023-02-18 16:31:58 时间
【摘要】 当前主流的目标检测器模型在训练时即确定了需要检测的物体种类,如果想要增加新的类别,只能重新训练。本文介绍了一种增量式的物体检测模型,可以随时增加新的类别,更符合实际场景。
文章信息:Konstantin Shmelkov, Cordelia Schmid, Karteek Alahari. Incremental Learning of Object Detectors without Catastrophic Forgetting. ICCV 2017.
文章主要介绍一种针对深度学习中物体检测任务的增量式学习方法。具体来说,问题的设置为:假设在一开始的时候已经有了一个用一些数据训练得到的物体检测模型;之后又有一批新的数据,这批数据上只标注了新的、未见过的类别的bounding box和类别,增量式物体检测方法的目标是在已有模型的基础上,学习一个新的模型,可以同时检测之前的类别和新类别的物体。
这个设置的难点在于,如果不对方法进行特殊的设计,而只使用新的数据更新模型,则模型在原来的类别上的表现会非常差,这个现象被称作“灾难性遗忘”。为了解决这个问题,作者提出将原始模型中的知识“蒸馏”出来,并在更新模型的时候既对新类别进行学习,也对这部分蒸馏出来的知识进行学习,从而保证模型不会遗忘已有的知识。
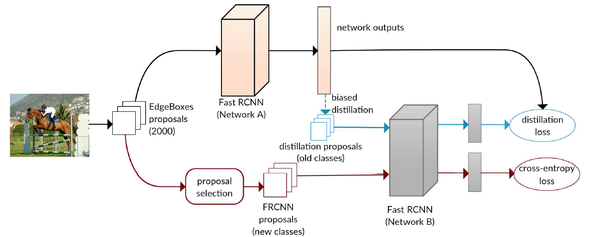
具体来说,该方法的模型设计如上图所示。本文中,为了保证候选的region proposal不是针对原有模型中特定的类别,而是针对通用的物体,方法的基本架构基于Fast RCNN。当更新模型的时候,需要两个版本的模型,其中上路的Network A为原始的模型(模型参数完全固定,不进行调整),下路的Network B为可以更新的模型。模型的整体流程如下:
-
以新类别的图像作为Network A的输入,从背景得分最低(即物体得分最高)的128个RoI中随机选取64个,并在Network B中计算这64个RoI的预测输出(包括分类预测的logits和bounding box regression输出),约束Network B的预测输出和相应的Network A的预测输出相同(使用L2损失进行约束,忽略Network B中对应新类别的输出项)。通过约束新模型在已有类别上的输出和旧模型在已有类别上的输出相同,保证旧类别的知识可以迁移到新模型上;
-
针对新增的类别,使用标准的Fast RCNN损失进行训练。
从实验结果来看,相比于在具有完整标注的全部数据上的模型训练的方式来说,增量式物体检测方法在性能上有一定的下降,但是相比于不考虑“灾难性遗忘”问题的方案有明显的提升。

相关文章
- 关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)
- Shell脚本监控网站页面正常打开情况
- Java开发桌面程序学习(一)——JavaFx+Jfoenix初始以及搭建
- VideoPipe可视化视频结构化框架更新总结(2022-12-9)
- VideoPipe可视化视频结构化框架新增功能详解(2022-11-4)
- VideoPipe可视化视频结构化框架开源了!
- VP视频结构化框架(2022/9/30更新)
- 生成型神经网络
- 如何写好一篇技术型文档?
- 肢体识别与应用
- 从Vehicle-ReId到AI换脸,应有尽有,解你所惑
- 图像Resize方式对深度学习模型效果的影响
- 目标检测框不稳定不连续?
- 视频结构化技术栈全解析
- 多目标跟踪全解析,全网最全
- 后端分析/前端分析/边缘分析
- [计算机视觉]非监督学习、AutoEncoder、AI换脸demo
- [计算机视觉]从零开始构建一个微软how-old.net服务/面部属性识别
- [计算机视觉]人脸应用:人脸检测、人脸对比、五官检测、眨眼检测、活体检测、疲劳检测
- [AI开发]一个例子说明机器学习和深度学习的关系