
从部署和运维说说DLI(1)
2023-02-18 16:31:59 时间
DLI是支持多模引擎的Serverless大数据计算服务,其很好的实现了Serverless的特性:
1. 弱化了存储和计算之间的联系;
2. 代码的执行不再需要手动分配资源;
3. 按使用量计费。
那么如何才能更好的实现Serverless化的服务,同时又避免成为传统单体分布式的应用?微服务架构无疑是最优的选择。DLI基于微服务架构模式下的整体部署架构如下:
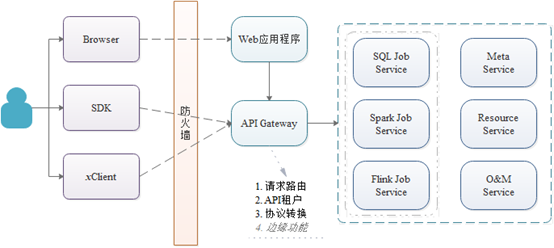
即对外以纯API形式提供服务,通过以APIGateway作为应用的入口,基于领域模型按子域进行微服务划分,从而实现Serverless化的大数据计算服务。
那么对于这样的一个基于微服务架构实现的Serverless服务,我们是如何在生产环境来部署与运维,从而在保证服务SLA的前提下实现快速迭代上线的呢?
随着技术的发展,部署的流程和架构都发生了根本性的变化,如今已经走入了轻量级、短生命周期的技术时代。
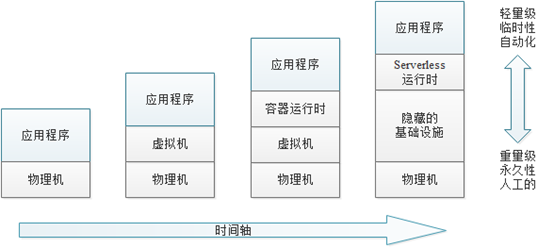
从最初部署在物理机上的大数据计算平台,到基于公有云的弹性计算云服务器部署大数据平台,再到DLI这样的Serverless服务,其很好展现了大数据计算服务的演变。那么如何才能更好的实现Serverless化的大数据计算服务的部署呢,DLI的答案就是基于Kubernetes+Docker来部署各微服务。
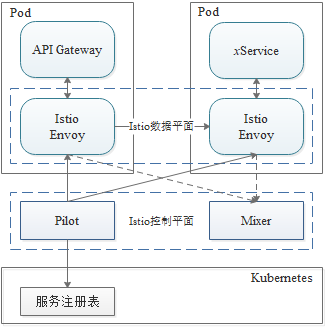
Kubernetes部署是在不停机的情况下部署服务的好方法,但是如何应对在接收生产流量后出现的错误,使新版本的服务更可靠呢?这可以通过将问题一分为二来看:
1. 部署,即将服务上线到生产环境中运行;
2. 发布,即使服务可用于处理生产流量。
传统上,分离部署流程与发布流程一直是一个挑战。但现在我们有了很好的选择,那就是基于服务网格。在DLI的部署中我们结合了Kubernetes+Istio,利用Istio的流量管理实现了服务发现、流量路由,从而轻松的将部署与发布分开,使新版本的服务更加可靠。

相关文章
- 中秋节,华为云AI送上超级大月亮制作教程,体验赢开发者键鼠套装
- VLDB'22 HiEngine极致RTO论文解读
- 强扩展、强一致、高可用…GaussDB成为游戏行业的心头爱
- 推理网络精度不达标,5个方法轻松搞定
- 一文带你认知定时消息发布RocketMQ
- 手把手教你君正X2000开发板的OpenHarmony环境搭建
- 遥居前列!华为云GaussDB再获行业权威验证
- 云图说丨初识分布式消息服务Kafka版
- Karmada v1.3:更优雅 更精准 更高效
- CodeLab:一款让你体验丝滑般的云化JupyterLab
- OpenHarmony3.0如何轻松连接华为云IoT设备接入平台?
- GaussDB(for Redis)双活容灾支持4大应用场景,为业务安全保驾护航
- 大规模数据如何实现数据的高效追溯?
- 百万奖池角逐,华为云IoT边缘带你看懂“边缘计算开发者大赛”
- 如何用AscendCL的接口开发网络模型推理场景下应用?
- 天呐,我居然可以隔空作画了
- 从零教你使用MindStudio进行Pytorch离线推理全流程
- 一文带你认识AscendCL
- 从原理剖析带你理解Stream
- 不信谣不传谣,亲自动手验证ModelBox推理是否真的“高性能”