
机器学习中必学的四种交叉验证技术
介绍
考虑在数据集上创建模型,但它在看不见的数据上失败。
我们不能简单地将模型拟合到我们的训练数据中,然后坐等它在真实的、看不见的数据上完美运行。
这是一个过度拟合的例子,我们的模型已经提取了训练数据中的所有模式和噪声。为了防止这种情况发生,我们需要一种方法来确保我们的模型已经捕获了大多数模式并且不会拾取数据中的每一点噪声(低偏差和低方差)。处理此问题的众多技术之一是交叉验证。
了解交叉验证
假设在一个特定的数据集中,我们有 1000 条记录,我们train_test_split()在上面执行。假设我们有 70% 的训练数据和 30% 的测试数据random_state = 0,这些参数导致 85% 的准确度。现在,如果我们设置random_state = 50假设准确度提高到 87%。
这意味着如果我们继续选择不同random_state的精度值,就会发生波动。为了防止这种情况,一种称为交叉验证的技术开始发挥作用。
交叉验证的类型
留一交叉验证 (LOOCV)
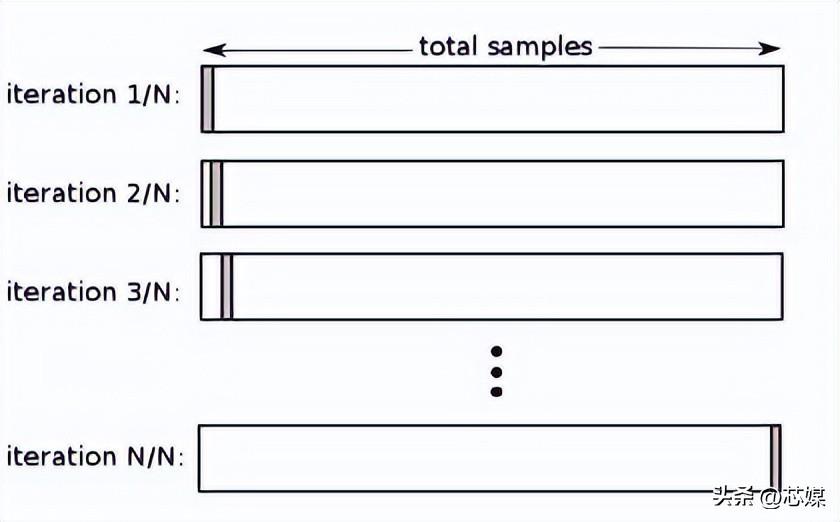
在LOOCV中,我们选择 1 个数据点作为测试,剩下的所有数据都将是第一次迭代中的训练数据。在下一次迭代中,我们将选择下一个数据点作为测试,其余的作为训练数据。我们将对整个数据集重复此操作,以便在最终迭代中选择最后一个数据点作为测试。
通常,要计算迭代交叉验证过程的交叉验证 R²,您需要计算每次迭代的 R² 分数并取它们的平均值。
尽管它会导致对模型性能的可靠且无偏的估计,但它的执行计算成本很高。
2. K-fold 交叉验证

在K-fold CV中,我们将数据集拆分为 k 个子集(称为折叠),然后我们对所有子集进行训练,但留下一个 (k-1) 个子集用于评估训练后的模型。
假设我们有 1000 条记录并且我们的 K=5。这个 K 值意味着我们有 5 次迭代。对于测试数据要考虑的第一次迭代的数据点数从一开始就是 1000/5=200。然后对于下一次迭代,随后的 200 个数据点将被视为测试,依此类推。
为了计算整体准确度,我们计算每次迭代的准确度,然后取其平均值。
我们可以从这个过程中获得的最小准确度将是所有迭代中产生的最低准确度,同样,最大准确度将是所有迭代中产生的最高准确度。
3.分层交叉验证
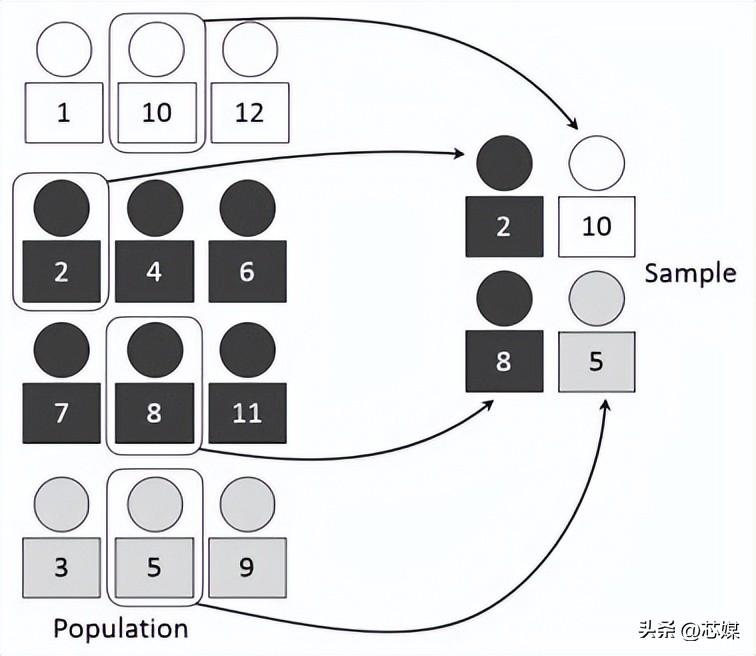
分层 CV是常规 k 折交叉验证的扩展,但专门针对分类问题,其中的分割不是完全随机的,目标类之间的比率在每个折中与在完整数据集中的比率相同。
假设我们有 1000 条记录,其中包含 600 条是和 400 条否。因此,在每个实验中,它都会确保填充到训练和测试中的随机样本的方式是,每个类的至少一些实例将是存在于训练和测试分裂中。
4.时间序列交叉验证
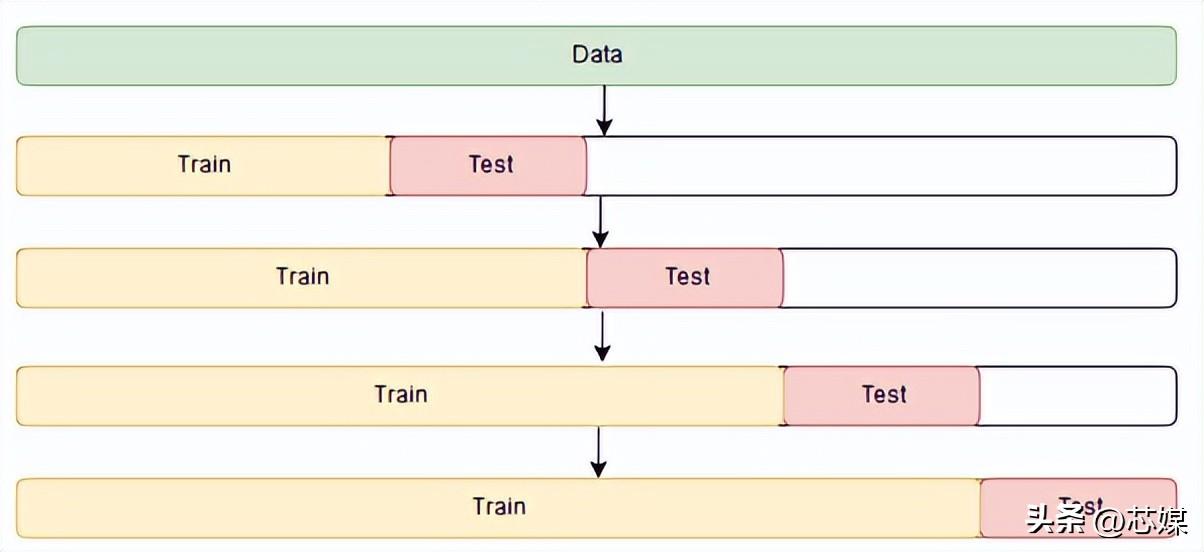
在时间序列 CV中有一系列测试集,每个测试集都包含一个观察值。相应的训练集仅包含在形成测试集的观察之前发生的观察。因此,未来的观察不能用于构建预测。
预测精度是通过对测试集进行平均来计算的。此过程有时被称为“对滚动预测原点的评估”,因为预测所基于的“原点”会及时前滚。
结论
在机器学习中,我们通常不想要在训练集上表现最好的算法或模型。相反,我们需要一个在测试集上表现出色的模型,以及一个在给定新输入数据时始终表现良好的模型。交叉验证是确保我们能够识别此类算法或模型的关键步骤。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合