
【机器学习】李宏毅——浅谈机器学习原理+鱼与熊掌兼得的深度学习简述
如何评判一个训练集的好坏
如果我们希望得到一个训练集,并且用该训练集所训练出来的模型,在训练集上的误差和在整个数据空间上的误差相距较小,即写成如下表达式:
那么训练集(D_{train})应该满足的条件为:
即对于假设空间中的任何模型在训练集上的误差和在整个数据空间上的误差之间的误差都小于某个值。推导过程如下:
因此,我们总希望得到一个好的样本集,其能够满足:
下面则来探讨一下我们选取到坏的数据集的概率。
由前述的讨论可知,一个(D_{train})是坏的,则至少存在一个h使得它不满足上式,那么可以认为:
那么可以看到:增加训练集样本的数据(N)或者减少假设空间的大小(lvert H vert)都可以使得拿到坏数据集的概率降低
但在实际运用中很少采用这样来进行衡量,因为随机计算一下上界就大于1了,这只是给我们启发如何做而已。
而在现实中通常另外收集数据这个方法很难实现,那如果刻意去减少(H)的大小呢,这虽然可以使上界降低,但如果使得(H)都没有能够让损失函数很小的假设,那这个减少就很没有意义了。如下图,虽然在更小的(H)能够让训练假设的误差更接近于完美假设的误差,但这个完美假设是在这个小的假设空间中选出来的,很可能它本身的误差就很大。
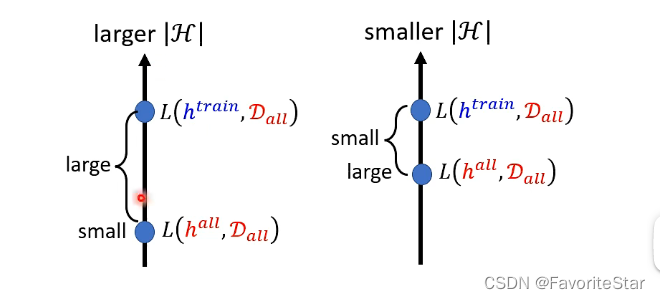
那么有没有可能有一个loss很低的完美假设,同时还能够让现实训练出来的假设和理想很接近呢?,即图中两个small都要。
鱼与熊掌可以兼得的机器学习
承接上文,如果我们要有一个loss很低的完美假设,同时还能够让现实训练出来的假设和理想很接近,那么最简单的想法当然是假设空间很小,但是假设空间里面的假设都是能够让损失函数非常小的好假设
这里需要补充一下前面讲过的内容“为什么需要隐含层”,可以看我这篇文章点此跳转,具体即讲述了神经网络是如何利用隐含层来逼近任何函数的。
那么是不是只要一个隐含层就够了呢?那么为什么还需要深度学习呢?
事实上,在实现同一个复杂函数时,使用深度较大宽度较小的网络,相较于只有一层而宽度很大的网络来说,其参数量会小很多,也就是说其效率会更高,同时参数量小也就说明需要的训练数据量也会小,也就更加不容易过拟合。
那么结合前面的说法,深度学习可以使得(H)的大小减小,并且效果也能够与(H)很大的宽度方向的神经网络相当。而在一些函数是复杂但有一定规律的情况下,深度学习的效果可以更好,其参数量可以更小。
相关文章
- EasyCVR对接华为iVS订阅摄像机和用户变更请求接口介绍
- 精选 | 腾讯云CDN内容加速场景有哪些?
- 模块化网络防止基于模型的多任务强化学习中的灾难性干扰
- 用搜索和注意力学习稳健的调度方法
- 用于多变量时间序列异常检测的学习图神经网络
- 助力政企自动化自然生长,华为WeAutomate RPA是怎么做到的?
- 使用腾讯轻量云搭建Fiora聊天室
- TSRC安全测试规范
- 云计算“功守道”
- 助力成本优化,腾讯全场景在离线混部系统Caelus正式开源
- Flink 利器:开源平台 StreamX 简介
- 腾讯云实践 | 一图揭秘腾讯碳中和?解决方案
- 深度学习中的轻量级网络架构总结与代码实现
- 信息系统项目管理师(高项复习笔记三)
- Adobe国际认证让科技赋能时尚
- c++该怎么学习(面试吃土记)
- 面试官问发布订阅模式是在问什么?
- 面试官:请实现一个通用函数把 callback 转成 promise
- 空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
- 中山大学林倞解读视觉语义理解新趋势:从表达学习到知识及因果融合