
6.5用二叉树实现哈夫曼编码
2023-04-18 15:22:17 时间
莫尔斯编码是根据日常文本中各字符出现频率决定表示各字符的编码的数据长度。不过,该编码体系,对AAAAAABBCDDEEEEEEF这样的特殊文并不是最合适的。在莫尔斯编码中,E的数据长度最短,而在AAAAAABBCDDEEEEEEF这个文本中,出现最频繁的是字符A。因此,应该给A分配数据长度最短的编码。这样才会使压缩率更高。
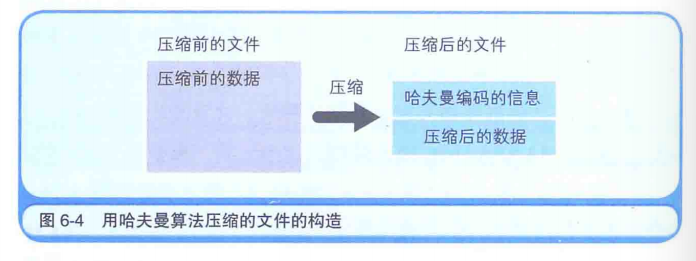
哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样的编码(哈夫曼编码)对数据进行分割,就由各个文件而定。用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据(图6-4)。
把AAAAAABBCDDEEEEEEF中的A~F这些字符,按照“出现频率高的字符用尽量的位数编码来表示”这一原则进行整理。按照出现频率从高到低的顺序整理后,结果就如表6-3所示。
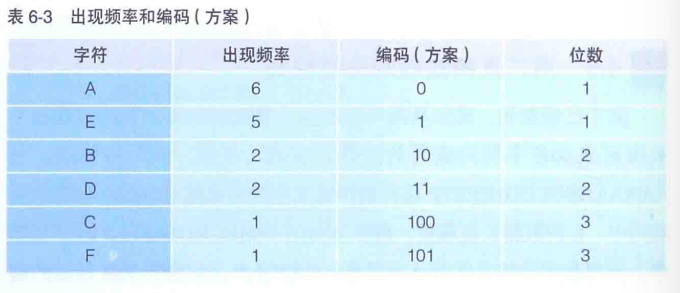
在6-3的编码(方案)中,随着出现频率的降低,字符编码信息的数据位数也在逐渐增加到3位。这个编码体系是存在问题的。如果不加入用来区分字符的符号,这个编码(方案)就无法使用。
而在哈夫曼算法中,通常借助哈夫曼树构造编码体系,即使在不使用字符区分的情况下,也可以构建能够明确进行区分的编码体系。也就是说,利用哈夫曼树后,就算表示各字符的数据位数不同,也就能够做成可以明确区分的编码,与RLE算法相比,程序的内容要复杂很多。
自然界的树是从根开始生枝长叶的,而哈夫曼树则是从叶生枝,然后在生根。图6-5展示了对AAAAAABBCDDEEEEEEF进行编码的哈夫曼树的制作过程。

相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!