
SQL中的排序order by 、SQL中的分页limit、SQL的多表查询、
2023-03-31 11:04:40 时间
SQL中的排序
使用关键字:ORDER BY
- ORDER BY 字段名后使用ASC升序表示;使用DESC表示降序。
- ORDER BY 后面可以使用列的别名进行排序(列的别名只能在ORDER BY中使用,不能再HWERE后使用)
- WHERE需要再FROM后,ORDER BY前声明!!
- 多级排序,ORDER BY 列名1 ASC,列名2 DESC..;
SQL中的分页
mysql使用LIMIT实现数据的分页显示
# 需求1:每页显示20条,此时显示第1页
SELECT employee_id,last_name FROM employees
LIMIT 0,20; #limit后第一个数字表示偏移量,第一条数据为0,第二个数字表示显示多少条。
# 需求2:每页显示20条,此时显示第2页
SELECT employee_id,last_name FROM employees
LIMIT 20,20;
# 需求3:每页显示20条,此时显示第3页
SELECT employee_id,last_name FROM employees
LIMIT 40,20;
分页公式
# 需求:每页显示pagesize条,此时显示第pageno页
# 公式:LIMIT (pageno-1)*pagesize,pagesize;
关于LIMIT:mysql8.0新特性
LIMIT...OFFSET...
在8.0之前的版本,limit后面的默认第一个数字表示偏移量,第二个数字表示要取的条数
在8.0之后的版本,limit后面新增了一个offset关键字,offset后面表示偏移量,limit后面表示要取的条数
SQL的多表查询
多表查询基本格式
# 多表查询的格式:
# select 要查询的字段名 from 表1,表2.. where 表1.字段名=表2.字段名
# 注意:要查询的字段名如果在多表中出现,则需要指定是哪个表的字段。
# 但是,从sql查询优化的角度看,建议多表查询时指明每个字段来自哪个表
SELECT employee_id,department_name
FROM employees,departments
WHERE employees.department_id=departments.department_id;
多表查询的分类
角度1:等值连接 vs 非等值连接
角度2:自连接 vs 非自连接
角度3:内连接 vs 外连接
- 等值连接:where后连接条件是=连接
SELECT employee_id,department_name
FROM employees,departments
WHERE employees.department_id=departments.department_id;
- 非等值连接:where后连接条件不是=连接
# 非等值连接例子
SELECT employee_id,salary,grade_level
FROM employees e,job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.grade_level;
- 自连接:自己这张表和自己连接
# 自连接的例子
# 员工表里有员工id和员工对应的管理者id(有的管理者也是员工,也在员工表里)这时需要自连接
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.manager_id=m.employee_id;
-
非自连接:一张表和其他表连接
-
内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
-
外连接:合并具有同一列的两个以上的表的行,结果集中包含一个表与另一个表匹配的行之外,还查询到了左表或者右表中不匹配的行,外连接的分类:左外连接、右外连接、满外连接。
- 左外连接
两个表在连接的过程中,除了返回满足连接条件的行以外,还返回了左表不满足条件的行,这种方式叫左外连接
- 右外连接
两个表在连接过程中,除了返回满足连接条件的行以外,还返回了右表不满足条件的行,这种方式叫右外连接
SQL92和SQL99实现内连接外连接的语法格式
# 查询所有员工的last_name和department_name信息、
# SQL92语法实现内连接,直接from后面写表名,表名用逗号分割,where后面写连接条件
# SQL92语法实现外连接使用+法 ----但是mysql不支持SQL92语法
# SQL99语法中使用JOIN...ON..实现多表查询
# SQL99的内连接写法:JOIN前面还可以加一个INNER(一般可省略)
SELECT last_name,department_name
FROM employees t1 JOIN departments t2
ON t1.department_id=t2.department_id
# SQL99的外连接写法:LEFT OUTER JOIN左外连接(OUTER可省略);RIGHT JOIN 右外连接
SELECT last_name,department_name
FROM employees t1 LEFT OUTER JOIN departments t2
ON t1.department_id=t2.department_id
# 满外连接:使用FULL OUTER JOIN---但是mysql不支持这样操作
SELECT last_name,department_name
FROM employees t1 LEFT OUTER JOIN departments t2
ON t1.department_id=t2.department_id
union和union all的使用
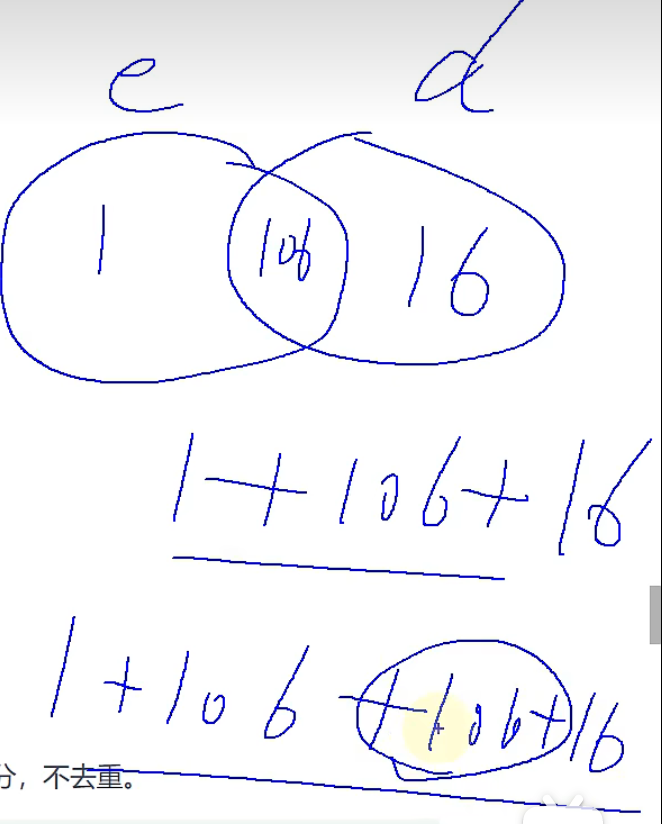
union:会执行去重操作
union all:不会执行去重操作
结论:如果明确知道合并后的数据不存在重复的数据,或者不需要去重重复数据,则尽量使用union all语句,以次来提高数据查询效率
7中JOIN操作的实现(重点)
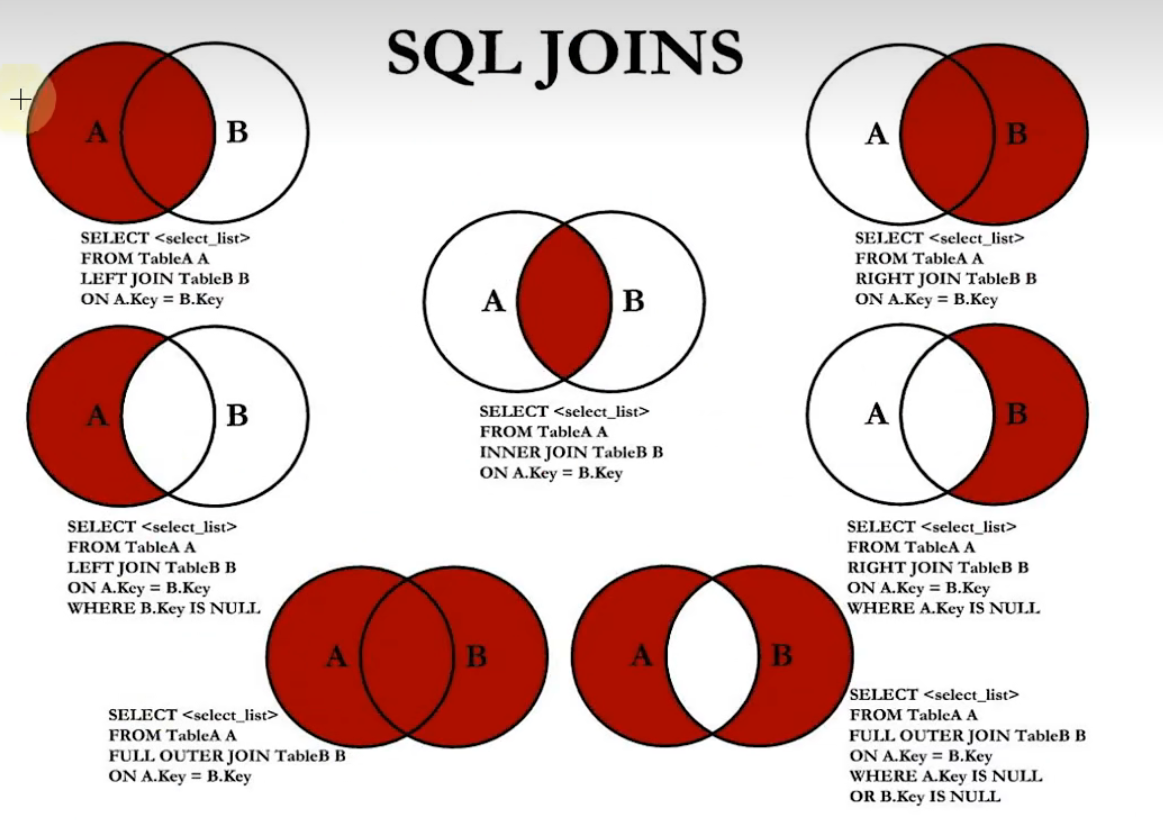
# 7种JOIN的实现,以employees和departments表为例
# 中图:内连接
SELECT employee_id,department_name
FROM employees t1 JOIN departments t2
ON t1.department_id=t2.department_id
# 左上图:左外连接
SELECT employee_id,department_name
FROM employees t1 LEFT JOIN departments t2
ON t1.department_id=t2.department_id
#右上图:右外连接
SELECT employee_id,department_name
FROM employees t1 RIGHT JOIN departments t2
ON t1.department_id=t2.department_id
# 左中图:
SELECT employee_id,department_name
FROM employees t1 LEFT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t2.department_id is NULL
# 右中图:
SELECT employee_id,department_name
FROM employees t1 RIGHT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t1.department_id IS NULL
# 左下图:使用union all连接上面的两个表
# 方式1:连接左上图和右中图
SELECT employee_id,department_name
FROM employees t1 LEFT JOIN departments t2
ON t1.department_id=t2.department_id
UNION ALL
SELECT employee_id,department_name
FROM employees t1 RIGHT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t1.department_id IS NULL
# 方式2:连接右上图和左中图
SELECT employee_id,department_name
FROM employees t1 RIGHT JOIN departments t2
ON t1.department_id=t2.department_id
UNION ALL
SELECT employee_id,department_name
FROM employees t1 LEFT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t2.department_id is NULL
# 右下图:连接左中图和右中图
SELECT employee_id,department_name
FROM employees t1 LEFT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t2.department_id is NULL
UNION ALL
SELECT employee_id,department_name
FROM employees t1 RIGHT JOIN departments t2
ON t1.department_id=t2.department_id
WHERE t1.department_id IS NULL
SQL99的新特性
- 新特性1:自然连接NATURAL JOIN
自然连接它会帮你自动查询两张表中的所有相同字段。然后进行等值连接
# 不用自然连接的写法
SELECT employee_id,department_name
FROM employees t1 JOIN departments t2
ON t1.department_id=t2.department_id
AND t1.manager_id=t2.manager_id
# 使用自然连接的写法
SELECT employee_id,department_name
FROM employees t1 NATURAL JOIN departments t2
# 使用natural自动代替了on下面的连接条件
- 新特性2:USING的使用
# 原先连接的正常写法
SELECT employee_id,department_name
FROM employees t1 JOIN departments t2
ON t1.department_id=t2.department_id
# 使用USING之后的写法
SELECT employee_id,department_name
FROM employees t1 JOIN departments t2
USING(department_id)
相关文章
- 从本体论开始说起——运营商关系图谱的构建及应用
- 如何成为一名数据科学家?
- 从未见过的堂兄杀了人,你的DNA是关键证据
- 20个安全可靠的免费数据源,各领域数据任你挑
- 20个安全可靠的免费数据源,各领域数据任你挑
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假