
OpenCV笔记(10) 相机模型与标定
万圣节快乐!
1. 相机模型
针孔相机模型:过空间某特定点的光线才能通过针孔(针孔光圈),这些光束被投影 到图像平面形成图像。

将图像平面在针孔前方,重新把针孔相机模型整理成另一种等价形式,
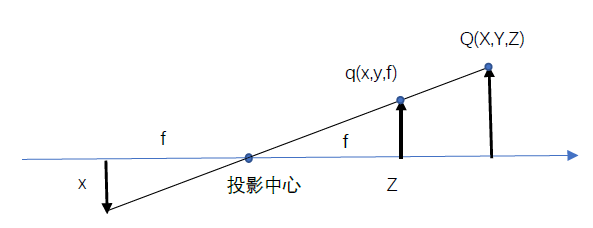
实际上,芯片的中心通常不在光轴上,我们因此引入两个新的参数cx和cy,对投影屏幕(图像平面)坐标中心可能的偏移(对光轴而言)进行建模。这样一来物理世界中的点Q,其坐标为(X, Y, Z),根据下式投射到成像装置上某个像素位置(xscreen,yscreen):
xscreen = fx*X/Z+cx, and yscreen = fy*Y/Z+cy
我们引入了两个不同的焦距,原因是单个像素在低价成像装置上是矩形而不是正方形。例如,焦距fx实际上是透镜的物理焦距长度与成像装置每个单元尺寸sx的乘积(这样做的意义在于sx的单位是像素/每亳米,而f的单位是毫米,这意味着fx的单位是像素。
2. 射影几何基础
将物理世界中坐标为(Xi, Yi , Zi)的一系列物理点Q映射到投影平面上坐标为(xi, yi)的点的过程叫“射影变换”。公式为:
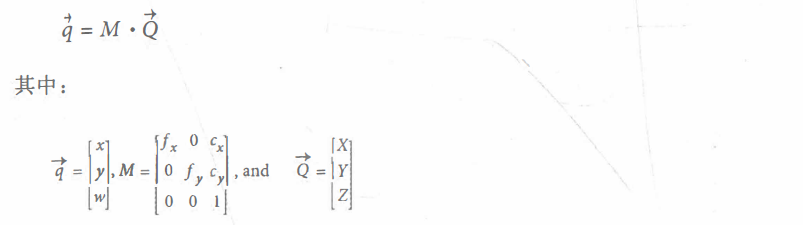
其中,M为相机的内参矩阵,Q为物理世界的点。将q的x和y坐标都除以w,可以得到实际的像素坐标值。
函数cv::convertPointsToHomogeneous()和cv::convertPointsFromHomogeneous()允许我们在齐次坐标和非齐次坐标之间转换。
采用理想针孔,由于只有很少量的光线通过针孔, 在实际中, 无论使用何种图像采集器, 都需要等待积累足够的光线, 因此成像速度非常慢。 对于快速生成图像的相机而言,必须利用更大面积的光线,甚至让光线弯曲,从而让足够多的光线能够聚焦到投影点上。我们使用透镜来实现这个目的。 透镜可以聚焦足够多的光线到一个点上,使得图像生成更加迅速,但代价是引入了畸变。
3.Rodrigues变换
在三维空间操作时,通常使用3x3矩阵来表示空间中的旋转。这种表示通常最方便, 因为将向量乘以该矩阵相当于以某种方式旋转向量。缺点是很难理解3x3矩阵表示什么样的旋转。除此之外,可以通过一个向量表示沿着某一角度进行旋转,向量的方向表示旋转轴的方向,向量的长度表示沿逆时针方向的旋转量。这个很容易做到,因为方向可以用任意幅度的向量表示。因此,我们可以选择我们的向量幅度等于旋转的角度。旋转向量与旋转矩阵可以通过Rodrigues变换进行转换。三维空间的旋转包含三个自由度, 从数值优化的角度而言, 处理只有三个部分的Rodrigues表示比处理有几个部分的3x3旋转矩阵方便得多。
void Rodrigues( InputArray src, //输入旋转向量or矩阵
OutputArray dst, //输出旋转矩阵or向量
OutputArray jacobian = noArray() );
最后一个参数是可选的, 如果jacobian不是cv::noArray(),那么它应该是一个指向3x9或9x3矩阵的指针, 该矩阵将填充输出矩阵元素相对于输入矩阵元素的偏导数。输出的jacobian主要用千CV: : solvePnP( )和cv::calibrateCamera()函数的内部优化,使用cv::Rodrigues()函数主要用于将cv:: solvePnP()和cv::calibrateCamera()的输出从Rodrigues格式的1x3或3x1轴—角度向量转化为旋转矩阵。在此时,可以将jacobian设置为cv::noArray( )。
示例:
#include <opencv.hpp> using namespace cv; using namespace std; int main() { Mat r = (cv::Mat_<float>(3, 1) << -2.100418, -2.167796, 0.273330); Mat R; Rodrigues(r, R, noArray()); for (int i = 0; i < 3; i++) { for (int j = 0; j < 3; j++) { printf("%f ", R.at<float>(i,j)); } printf("\n"); } return 0; }
结果:
-0.036254 0.978364 -0.203692 0.998304 0.026168 -0.051995 -0.045539 -0.205232 -0.977653
4. 透镜畸变
4.1 径向畸变
径向畸变是由于透镜的形状造成的,远离透镜中心的光线比靠近透镜中心的光线更加弯曲,在成像装置边缘附近的像素位置产生显著的畸变。也称为筒形畸变。
对于径向畸变, 成像装置的(光学)中心处的畸变为0,随着向边缘移动,畸变越来越大。实际上,这种畸变很小,可以用 r = 0 附近的泰勒级数展开的前几项来描述。对于廉价的网络相机,我们通常使用前两项;其中通常将第一项称作 k1,第二项称作 k2。对于畸变很大的相机, 比如鱼眼透镜,我们可以使用第三个径向畸变项 k3。通常,成像装置上某点的径向位置可以根据以下等式进行调整:
xcorrected = x • (1 + k1r2 + k2r4 + k3r6)
ycorrected = y • (1 + k1r2 + k2r4+k3r6)
这里(x, y)是(成像装置上)畸变点的原始位置,(xcorrected,ycorrected)是矫正后的新位置。 下图显示了矩形由于径向畸变产生的偏移。 随着距光学中心的径向距离的增加, 矩形上的外部点越来越向内偏移。
4.2 切向畸变
这种畸变是由于制造上的缺陷使透镜不与成像平面平行而产生的。在廉价的相机中,这种现象发生在成像装置被粘在相机背面的时候。切向畸变可以用两个额外参数P1 和P2来表示:
xcorrected = x + [ 2p1xy + p2(r2 + 2x2)]
ycorrected = y + [ p1(r2 + 2y2) + 2p2xy ]
因此我们总共需要五个畸变参数。因为在大多数使用它们的OpenCV程序中,这五个参数都是必需的,因此它们被放到一个畸变向量中,这是一个5x1的矩阵包括k1,k2,p1,p2和k3(按顺序)。在成像系统中还有很多其他类型的畸变,但是它们比径向和切向畸变的影响小。因此,我们和OpenCV都不会进一步处理它们。
5. 标定
OpenCV提供了一些算法来帮我们计算这些内部参数。实际标定过程是通过cv::calibrateCamera()来完成的。标定的方法是把相机对准一个具有很多独立可标识点的已知结构。通过从多个视角观察这个结构,我们可以计算拍摄每个图像时相机的(相对)位置和方向以及相机的内部参数。为了提供多个视角, 我们需要旋转和平移物体。
5.1 旋转矩阵和平移变量
我们已经知道可以用三个角度来表示三维旋转,可以用三个参数(x,y, z)来表示三维平 移,因此我们目前有六个参数。OpenCV相机内参矩阵有四个参数(fx、fy、cx和cy),所以每个视图都需要求解10个参数(注意,相机内在参数在不同视图保持不变)。使用一个平面物体,我们很快可以看到每个视图固定八个参数。因为在不同视图下旋转和平移的 六个参数会变化,对于每个视图,我们对两个额外参数进行约束,随后使用它们来求解相机内参矩阵。因此,我们需要(至少)两个视图来求解所有的几何参数。
5.2 标定板
OpenCV选择使用平面物体的多个视图,而不是特别构造的三维物体的一个视图。目前我们将集中讨论棋盘模式。使用交替的黑色和白色方格的图案确保在测量中没有偏向一侧或另一侧。
5.3 相机标定
首先要注意的是外参数包括3个旋转参数和3个平移参数,每个棋盘视图共有6个外参数。 由相机内参矩阵的4个参数和6个外参数共同构成10个需要求解的参数, 在单个视图的情况下, 每个额外的视图就会增加6个参数。
假设有N个角点和K个棋盘图像(不同位置)。 我们需要看到多少视图和角点才能有足够的约束条件来求解所有这些参数?
• K个棋盘图像提供2 · N · K个约束(出现因子2是因为图像上的每个点都具有x和y两个坐标值)
• 忽略每次的畸变参数, 我们有4个内在参数和6 · K个外参数(因为我们需要在K个视图中找到棋盘位置的6个参数)。
• 求解的前提是2·N·K≥6·K+4。
所以看起来如果N = 5, 那么我们只需要K = 1的图像, 但要注意!无论我们在平面上发现多少角点, 我们只得到四个有用的角点信息,因此至少需要两个视图才能求解我们的标定问题。 在实践中, 为了获得高质批的效果, 需要至少10张7X8或更大的棋盘图像(只有在图像之间移动足够次数的棋盘才能获得 “丰富的“ 视图)。
5.4 用cv::findChessboardCorners()找到棋盘角点★★★
给定一个棋盘图像(或一个人手持棋盘,或任何具有棋盘的场景和合适的无干扰背景),可以使用函数cv::findChessboardCorners()来定位棋盘的角点。如果可以找到并排序所有的角点,返回值被设为true,否则为false。
bool findChessboardCorners( InputArray image, //必须是8bit图像
Size patternSize, //棋盘图,8UC1 OR 8UC3
OutputArray corners, //棋盘每行每列有多少角点 Size(cols,rows) int flags = CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE );
//用于实现一个或多个附加滤波步骤,以帮助找到棋盘上的角点
棋盘上的亚像素角点和cv::cornerSubPix()
findChessboardCorners()使用的内部算法仅提供角点的近似位置。因此,cornerSubPix()由indChessboardCorners()自动调用,以获得更准确的结果。这在实际中意味着这些位置是相对准确的。但是,如果你希望将它们定位到非常高的精度,则需要在输出上自己调用cornerSubPix()(有效地再次调用它), 但是需要更严格的终止条件。
5.5 使用cv::drawChessboardCorners()绘制棋盘角点★★★
函数cv::drawChessboardCorners()将cv::findChessboardCorners()找到的角点绘制到你提供的图像上。如果没有找到所有的角点, 则可用的角点将被表示为小的红色圆圈。如果整个图案上的角点都找到, 那么角点将被绘制成不同的颜色(每一行都将有自己的颜色), 并将角点以一定顺序用线连接起来。
void drawChessboardCorners( InputOutputArray image, //由于角点是用有颜色的圆圈表示的,因此必须为8位的彩色图像。
Size patternSize, InputArray corners,
bool patternWasFound );//是否整个棋盘图案上的角点都被成功找到
5.6 cv::calibrateCamera()得到相机内参和物体外参★★★
double calibrateCamera( InputArrayOfArrays objectPoints,//在x和y维中是整数,在z维中为零 InputArrayOfArrays imagePoints, //图像中每个点的位置
Size imageSize,//图像的大小(以像素为单位) InputOutputArray cameraMatrix, //包含线性内在参数, 应为3x3矩阵
InputOutputArray distCoeffs,//畸变参数,可以是4,5或8个元素 OutputArrayOfArrays rvecs, //旋转矩阵(以Rodrigues形式表示)
OutputArrayOfArrays tvecs,//平移矩阵 int flags = 0,
TermCriteria criteria = TermCriteria(//终止标准 TermCriteria::COUNT + TermCriteria::EPS, 30, DBL_EPSILON) );
flags参数允许对标定过程进行更精确的控制。 以下值可以根据需要与布尔OR运算组合在一起。
- CALIB_USE_INTRINSIC_GUESS
在计算内参矩阵时不需要其他信息。具体来说,参数cx和cy(图像中心)的初始值直接从imageSize参数中得到。如果设置此参数,则假定cameraMatrix中包含有效值,该值将作为初始猜测值被进一步优化。在许多实际应用中, 我们知道相机的焦距, 因为我们可以从镜头的侧面读取它们。在这种情况下, 将这些信息放入相机矩阵中并使用 cv::CALIB_USE_INTRINSIC_GUESS是一个好主意。
- CALIB_FIX_PRINCIPAL_POINT
该标志可以与CALIB_USE_INTRINSIC_GUESS结合使用,也可以单独使用。如果单独使用,则主点固定在图像中心;如果共同使用,则主点固定在cameraMatrix中提供的初始值。
- CALIB FIX ASPECT RATIO
如果设置这个标志,那么在调用标定程序时,优化过程将一起改变fx和fy,并且它们的比值保持在cameraMatrix中设置的值。如果没有设置cv::CALIB_USE_INTRINSIC_ GUESS标志, 那么cameraMatrix中的fx和fy的值可以是任意值,只是它们的比值是相关的。
- CALIB FIX FOCAL LENGTH
该标志在优化时直接使用cameraMatrix中传递的fx和fy
- CALIB_FIX_K1, cv::CAlIB_FIX_K2, ... cv::CALIB_FIX_K6
修正径向畸变参数k 1 , k2到k6。 可以通过组合这些标志来设置径向参数。
- CALIB RATIONAL MODEL
该标志告诉OpenCV计算k4,k5和k6和从三个畸变系数。 这是因为向后兼容性问题, 如果不添加此标志, 则只计算前三个K参数(即使你为distCoeffs提供了一个八元素矩阵)。
5.7 已知内参计算外参数
-
仅使用cv::solvePnP()计算外参数
在某些情况下,我们已经知道了相机的内在参数,因此只需要计算正在观察的对象的位置。这种情况与一般的相机标定明显不同,但它仍然是有用的工作。
bool solvePnP( InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess = false, int flags = SOLVEPNP_ITERATIVE );
solvePnP()的参数与calibrateCamera()的对应参数类似,但是有两个不同的地方:
1) objectPoints和imagePoints参数是来自物体的单个视图的参数(即,它们的类型为 cv::InputArray, 而不是cv::InputArrayOfArrays) 。
2) 内参矩阵和畸变系数是直接提供的而不必计算(即, 它们是输入而不是输出) 。
所输出的旋转向量以 Rodrigues形式表示:由三个部分组成的旋转向量表示棋盘或点旋转的三维坐标轴, 向量的幅度或长度代表逆时针旋转角度。这个旋转向量可以通过cv::Rodrigues()函数转换成我们之前讨论过的3x3旋转矩阵。平移向量是相机坐标中棋盘原点的偏移量。
useExtrinsicGuess参数可以设置为true,以表示rvec和tvec参数中的当前值应被视为求解的初始猜测值。默认值为false。
参数flags可以设置为三个值之一,即cv::IT ERATIVE, cv::P3P或cv:: EPNP , 以 表明应该使用哪种方法来求解整个系统。 当使用cv::ITERATIVE时, 会使用Levenberg-
-
只用cv::solvePnPRansac()计算外参数
cv: :solvePnP的一个缺点是对异常值不够鲁棒。 在相机标定时, 这不是一个问题, 主要 是因为棋盘本身为我们提供一种可靠的方法来找到我们关心的各个特征, 并通过它们的 相对几何位置来验证我们正在看的实物和我们认为的一致。 然而 , 当我们用相机定位的不是棋盘上的点而是真实世界中的点(例如, 使用稀疏关键点特征)时, 可能发生错配并导致严重的问题。 回想一下我们在前面讨论单应性时讲过RANSAC方法可以成为处理这种离群值的有效方法:
bool solvePnPRansac( InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess = false, int iterationsCount = 100, float reprojectionError = 8.0, double confidence = 0.99, OutputArray inliers = noArray(), int flags = SOLVEPNP_ITERATIVE );
RANSAC算法还由一些新参数控制。具体来说,iterationsCount参数设置RANSAC迭代的次数,
而reprojectionError参数表示将某点设置为内部点的最大重投影误差注39参数mininliersCount的命名有一定的误导性,如果在运行RANSAC时,内部点数最超过mininliersCount,则该过程将被终止,并且该组将被认为是内部点组。这样做可以显著提高性能,但如果设置得太低也会出现很多问题。最后,inliers参数是一个输出,如果提供的话,将用内部点的索引值(从objectPoints到imagePoints)来填充该参数。
6. 矫正
通过输入原始图像和由函数calibrateCamera()得到的畸变系数,生成矫正后的图像。我们既可以只用函数undistort()使用该算法一次性完成所需的任务,也可以用一对函数initUndistortRectifyMap()和remap()来更有效地处理此事,这通常适用于视频或者同一相机中获取多个图像的应用中。
6.1 矫正映射
当进行图像矫正时,我们必须指定输入图像中的每个像素在输出图像中移动到的位置,称为矫正映射(或有时为畸变映射)。这样的映射有以下几种表示:双通道浮点表示,双矩阵浮点数表示。定点表示。
6.2 使用 cv::convertMaps()在不同表示方式之间转换矫正映射
因为在矫正映射中有多个表示方式, 所以人们很自然地希望在这些表示方式之间能够进 行相互转换。我们用cv::convertMaps()函数便能够做到这一点。 这个功能允许你提供
6.3 使用cv::initUndistortRectifyMap()计算矫正映射★★★
void initUndistortRectifyMap(InputArray cameraMatrix, InputArray distCoeffs, InputArray R, //补偿相机相对千相机所处的全局坐标系的旋转
InputArray newCameraMatrix,// 对于单目图像,设为noArray() Size size, //输出映射的尺寸
int m1type, //最终的映射类型,可能值为CV_32FC1或CV_16SC2
OutputArray map1, OutputArray map2);
6.4 使用cv::remap()矫正图像★★★
一且计算了矫正映射,就可以使用cv:: remap()将它们应用于传入的图像。如前所述,cv::remap()函数有两个对应于矫正映射的映射参数,例如由 cv::initUndistortRectifyMap()计算得到的映射参数。cv:: remap()接受我们讨论的任何矫正映射格式:双通道浮点型、双矩阵浮点型或定点格式(带或不带插值表索引矩阵)。
void remap( InputArray src, OutputArray dst, InputArray map1, InputArray map2,//initUndistortRectifyMap()计算得到的映射参数 int interpolation, int borderMode = BORDER_CONSTANT, const Scalar& borderValue = Scalar());
6.5 使用cv::undistort()进行矫正★★★
在某些情况下,只需要校正一个图像,或者对每一个图像重新计算矫正映射。在这种情况下,可以使用更加简洁的undistort(),它可以有效地计算映射并将其应用于单个图像。
void undistort( InputArray src, OutputArray dst, InputArray cameraMatrix, InputArray distCoeffs, InputArray newCameraMatrix = noArray() );
6.6 使用cv::undistortPoints()进行稀疏矫正
只对你关心的点矫正。
7. 示例
#include<iostream> #include<opencv2\opencv.hpp> using namespace std; using namespace cv; int main(int argc, char* argv[]) { int n_boards = 10; float image_sf = 0.5f; float delay = 1.f; int board_w = 3; int board_h = 3; int board_n = board_w * board_h; Size board_sz = Size(board_w, board_h); //开启摄像头 VideoCapture capture(0); if (!capture.isOpened()) { cout << "\nCouldn't open the camera\n"; return -1; } //分配存储空间 vector<vector<Point2f>> image_points; vector<vector<Point3f>> object_points; double last_captured_timestamp = 0; Size image_size; //不断取图,直到取够n_boards张 while (image_points.size() < (size_t)n_boards) { Mat image0, image; capture >> image0; image_size = image0.size(); resize(image0, image, Size(), image_sf, INTER_LINEAR); //Find the board vector<Point2f> corners; bool found = findChessboardCorners(image, board_sz, corners); //Draw it drawChessboardCorners(image, board_sz, corners, found); double timestamp = (double)clock() / CLOCKS_PER_SEC; if (found && timestamp - last_captured_timestamp > 1) { last_captured_timestamp = timestamp; image ^= Scalar::all(255); Mat mcorners(corners); mcorners *= (1. / image_sf); image_points.push_back(corners); object_points.push_back(vector<Point3f>()); vector<Point3f>& opts = object_points.back(); opts.resize(board_n); for (int j = 0; j < board_n; j++) { opts[j] = Point3f((float)(j / board_w), (float)(j % board_w), 0.f); } cout << "Collected our " << (int)image_points.size() << "of" << n_boards << "needed chessboard images\n" << endl; } imshow("calibration", image); if ((waitKey(30) & 255) == 27) return -1; } destroyWindow("calibration"); cout << "\n\n*** CALIBRATIING THE CAMERA... \n" << endl; //Calibrate the camera Mat intrinsic_matrix, distortion_coeffs; double err = calibrateCamera( object_points, image_points, image_size, intrinsic_matrix, distortion_coeffs, noArray(), noArray(), CALIB_ZERO_TANGENT_DIST | CALIB_FIX_PRINCIPAL_POINT); //保存相机内参和畸变 cout << "***DONE!\n\n Reprojection error is" << err << "\nStoring Intrinsics.xml and Distortions.xml files\n\n"; FileStorage fs("intrinsics.xml", FileStorage::WRITE); fs << "image_width" << image_size.width << "image_height" << image_size.height << "camera_matrix" << intrinsic_matrix << "distortion_coeffs" << distortion_coeffs; fs.release(); //加载这些参数 fs.open("intrinsics.xml", FileStorage::READ); cout << "\nimage width:" << (int)fs["image_width"]; cout << "\nimage height:" << (int)fs["image_height"]; Mat intrinsic_matrix_loaded, distortion_coeffs_loaded; fs["camera_matrix"] >> intrinsic_matrix_loaded; fs["distortion_coeffs"] >> distortion_coeffs_loaded; cout << "\nintrinsic matrix:" << intrinsic_matrix_loaded; cout << "\ndistortion coefficients:" << distortion_coeffs_loaded << endl; //矫正映射 Mat map1, map2; initUndistortRectifyMap( intrinsic_matrix_loaded, distortion_coeffs_loaded, Mat(), intrinsic_matrix_loaded, image_size, CV_16SC2, map1, map2 ); //传入图像,显示的是没有畸变的图像 for (;;) { Mat image, image0; capture >> image0; if (image0.empty()) break; remap( image0, image, map1, map2, INTER_LINEAR, BORDER_CONSTANT, Scalar() ); imshow("Undistorted", image); if ((waitKey(30) & 255) == 27) break; } return 0; }
结果:
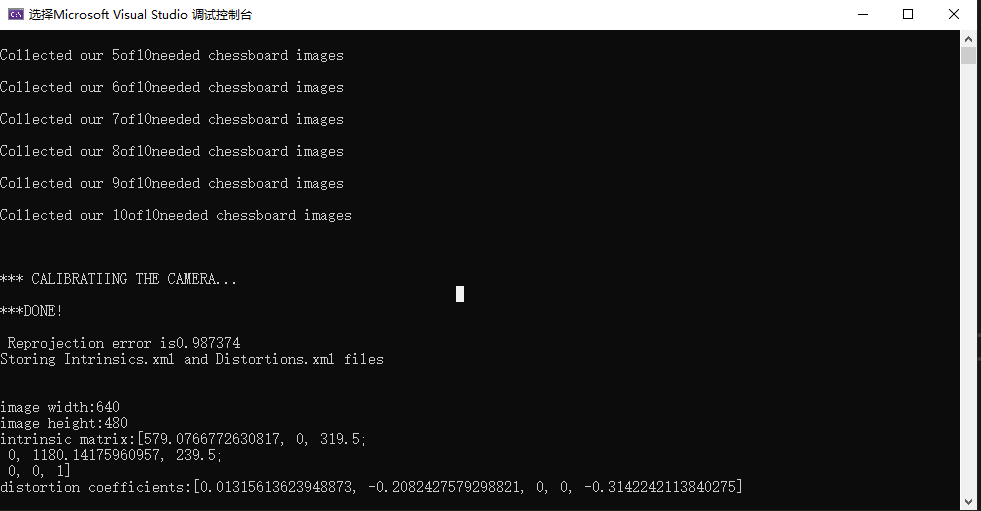
<?xml version="1.0"?> -<opencv_storage> <image_width>640</image_width> <image_height>480</image_height> -<camera_matrix type_id="opencv-matrix"> <rows>3</rows> <cols>3</cols> <dt>d</dt> <data>5.7907667726308171e+02 0. 3.1950000000000000e+02 0.1.1801417596095703e+03 2.3950000000000000e+02 0. 0. 1.</data> </camera_matrix> -<distortion_coeffs type_id="opencv-matrix"> <rows>1</rows> <cols>5</cols> <dt>d</dt> <data>1.3156136239488735e-02 -2.0824275792988209e-01 0. 0. -3.1422421138402745e-01</data> </distortion_coeffs> </opencv_storage>
补充:
1. 关于为什么
(waitKey(30) & 255) == 27
文章https://blog.csdn.net/hao5119266/article/details/104173400详细讲解了。
2. image_points和object_points的区别
image_points是图像上点的像素坐标,object_points是(0,0,0)(0,1,0)这样的位置
object_points的size是标定图片的个数,打印一个object_points,如下所示
[0, 0, 0;
0, 1, 0;
0, 2, 0;
0, 3, 0;
1, 0, 0;
1, 1, 0;
1, 2, 0;
1, 3, 0;
2, 0, 0;
2, 1, 0;
2, 2, 0;
2, 3, 0;
3, 0, 0;
3, 1, 0;
3, 2, 0;
3, 3, 0]
3. 为什么opts的z维为0,也就是object_points的z维为0
opts[j] = Point3f((float)(j / board_w), (float)(j % board_w), 0.f);
我们关注的点不是所有空间的坐标,只是在观察平面上的坐标,因此做一些简化,选择定义物体平面使得Z=0。(我猜的,我也不李姐)
4.opencv 图像畸变矫正加速、透视变换加速方法
https://blog.csdn.net/lcydhr/article/details/72726396
来自蝴蝶书18章P553-P597
相关文章
- 手搓一个“七夕限定”,用3D Engine 5分钟实现烟花绽放效果
- 七夕活动浪漫上线,别让网络拖慢和小姐姐的开黑时间
- AI智能剪辑,仅需2秒一键提取精彩片段
- 携手HMS Core分析服务,以数据助力游戏高效增长
- AI目标分割能力,无需绿幕即可实现快速视频抠图
- HMS Core音频编辑服务音源分离与空间音频渲染,助力快速进入3D音频的世界
- HMS Core Discovery第16期回顾|与虎墩一起,玩转AI新“声”态
- 如何让照片中的人物笑起来?HMS Core视频编辑服务一键微笑功能,让人物笑容更自然
- 虚拟偶像的歌声原来是这样生成的!
- 想让照片中的云飘起来?视频编辑服务一键动效3步就能实现
- 如何获取广告服务流量变现数据,助力广告效果分析?
- 小红书携手HMS Core,畅玩高清视界,种草美好生活
- HMS Core Discovery第16期直播预告|与虎墩一起,玩转AI新“声”态
- 动作活体检测能力,构建安全可靠的支付级“刷脸”体验
- 开发者必读:2022年移动应用运营增长洞察白皮书
- 【FAQ】接入HMS Core推送服务,服务端下发消息常见错误码原因分析及解决方法
- 如何打造3D立体世界?跟随图片一同探寻
- 有奖调研 | 让虚拟照入现实的完美AR开发平台长什么样?
- HMS Core图形图像技术展现最新功能和应用场景,加速构建数智生活
- 华为通用卡证识别功能,一键实现多种卡绑定