
【论文笔记】AlexNet
1.论文
3 The Architecture
3.1 ReLU Nonlinearity
标准的L-P神经元的输出一般使用tanh或 sigmoid作为激活函数,但是这些饱和的非线性函数在计算梯度的时候都要比非饱和的非线性函数ReLUs慢很多。
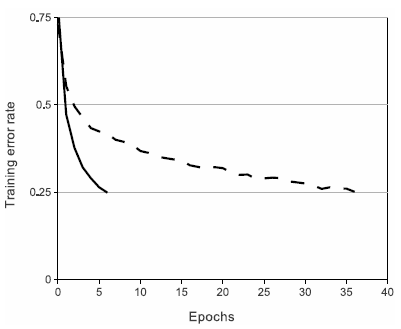
上图是使用ReLUs和tanh作为激活函数的典型四层网络的在数据集CIFAR-10s实验中,error rate达到到0.25时的收敛曲线,可以很明显的看到收敛速度的差距。虚线为tanh,实线是ReLUs。
3.2 Training on Multiple GPUs
3.3 Local Response Normalization
AlexNet中首次引入的归一化方法,但是在BatchNorm之后就很少使用这种方法了,所以简单了解下。
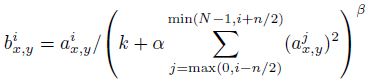
ai(x,y)代表的是ReLU在第i个kernel的(x, y)位置的输出,分母处对前面n/2个通道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的对应位置的平方求和(共n+1个点)。k,n,α和β为超参数由验证集决定。一般设置k = 2, n = 5, α = 10-4, and β = 0:75。
3.4 Overlapping Pooling
一般的池化单元是不会重叠的。一个池化层可以被认为是由一个网格组成,网格中的池单元间距为s个像素,每一个都总结了一个大小为zxz的社区,集中在池单元的位置。如果我们设置s=z,就获得了传统的池化层。如果我们设置s<z,那么就会产生覆盖的池化操作。当s=2,z=3,在top-1,和top-5中分别将error rate降低了0.4%和0.3%。同时在训练模型过程中,覆盖的池化层更不容易过拟合。
3.5 Overall Architecture

4 Reducing Overfitting
4.1 Data Augmentation数据增强
对抗过拟合最简单有效的办法就是扩大训练集的大小,AlexNet中使用了两种增加训练集大小的方式。
Image translations and horizontal reflections. 对原始的256x256大小的图片随机裁剪为224x224大小,并进行随机翻转,这两种操作相当于把训练集扩大了32x32x2=2048倍。在测试时,AlexNet把输入图片与其水平翻转在四个角处与正中心共五个地方各裁剪下224x224大小的子图,即共裁剪出10个子图,均送入AlexNet中,并把10个softmax输出求平均。如果没有这些操作,AlexNet将出现严重的过拟合,使网络的深度不能达到这么深。
AlexNet对RGB通道使用了PCA(主成分分析),对每个训练图片的每个像素,提取出RGB三个通道的特征向量与特征值,对每个特征值乘以一个α,α是一个均值0.1方差服从高斯分布的随机变量。
4.2 dropout
Dropout是神经网络中一种非常有效的减少过拟合的方法,对每个神经元设置一个keep_prob用来表示这个神经元被保留的概率,如果神经元没被保留,换句话说这个神经元被“dropout”了,那么这个神经元的输出将被设置为0,在残差反向传播时,传播到该神经元的值也为0,因此可以认为神经网络中不存在这个神经元;而在下次迭代中,所有神经元将会根据keep_prob被重新随机dropout。相当于每次迭代,神经网络的拓扑结构都会有所不同,这就会迫使神经网络不会过度依赖某几个神经元或者说某些特征,因此,神经元会被迫去学习更具有鲁棒性的特征。在AlexNet中,在训练时,每层的keep_prob被设置为0.5,而在测试时,所有的keep_prob都为1.0,也即关闭dropout,并把所有神经元的输出均乘以0.5,保证训练时和测试时输出的均值接近。当然,dropout只用于全连接层。没有dropout,AlexNet网络将会遭遇严重的过拟合,加入dropout后,网络的收敛速度慢了接近一倍。
2.代码实现
调用pytorch中的torchvision.model.AlexNet,输出其网络架构,如下:
model = torchvision.models.AlexNet() print(model)
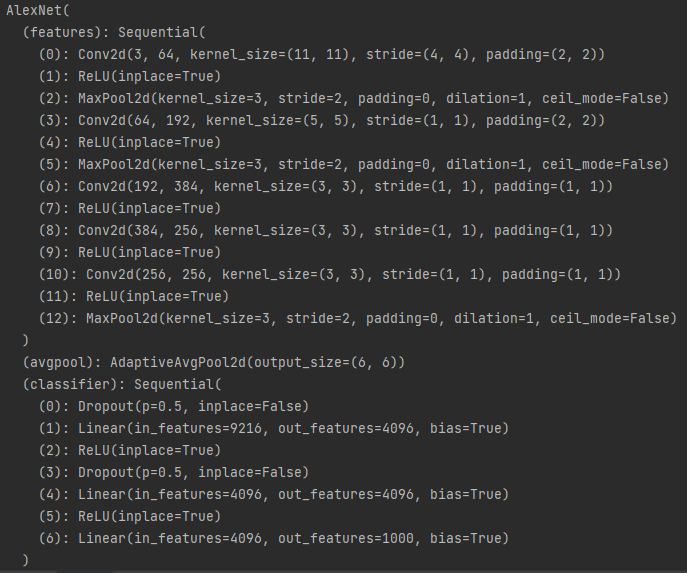
Tips:
- 卷积和线性层后面都加了ReLu
- 池化的k=3,s=2
import torch import torchvision from torch import nn from BasicModule import BasicModule class AlexNet(BasicModule): def __init__(self): super(AlexNet,self).__init__() self.model_name = "AlexNet" self.conv1 = nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,stride=4,padding=2) self.conv2 = nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,stride=1,padding=2) self.conv3 = nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1) self.conv4 = nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1) self.conv5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3,padding=1) self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2) self.pool2 = nn.MaxPool2d(2) self.l1 = nn.Linear(9216,4096) self.l2 = nn.Linear(4096, 4096) self.l3 = nn.Linear(4096, 2) self.drop = nn.Dropout(0.5) def forward(self,x): batch_size = x.size(0) x = self.pool1(nn.ReLU(self.conv1(x))) x = self.pool1(nn.ReLU(self.conv2(x))) x = nn.ReLU(self.conv3(x)) x = nn.ReLU(self.conv4(x)) x = self.pool1(self.conv5(x)) x = x.view(batch_size, -1) x = self.drop(nn.ReLU(self.l1(x))) x = self.drop(nn.ReLU(self.l2(x))) x = self.l3(x) return x model = AlexNet() input = torch.randn(32,1,224,224) output = model(input) print(output.shape)
相关文章
- kernel 启动流程
- UBOOT 启动流程
- 野火 STM32MP157 开发板内核和设备树的编译烧写
- 野火 STM32MP157 开发板 UBOOT 编译烧写
- ESP32 多线程入门实验
- VSCode 打开ESP32工程问题
- LVGL 定时器
- LVGL 字体
- LVGL 显示图片
- LVGL SCROLL循环滚动
- QT MySQL连接自动断开
- ESP32 SNTP校时
- ESP32 IDF 获取天气信息
- ESP32 分区表
- ESP32 使用LVGL案例
- LVGL 日志
- esp-idf 移植 lvgl8.3.3
- ESP32 + IDF + LED
- VSCode 中安装 esp-idf
- esp-idf 安装(Windows )