
【数据库设计与实现】第二章:数据前像与回滚
数据前像与回滚
设计原则
事务中重要的一点是事务的原子性,即事务中的所有操作要么全部生效,要么全部都不生效。数据的前像和回滚是保证事务原子性的重要手段。修改记录前,先将记录的前像(即修改前的记录)保存下来,当事务需要回滚时,将记录恢复到前像,从而保证事务的原子性。从当前的实现情况来看,前像保存主要有两种技术手段:
- 本地更新方案:直接在原记录上进行更新,把被更新列的前像保存到独立的undo区域;
- 异地更新方案:不在原记录上更新,而是克隆1条新记录出来,然后在新记录上进行更新,原记录就是前像;
Oracle和MySQL采用的都是本地更新方案,本章加入PostgreSQL,从而能够深入地了解异地更新方案的优缺点。在设计数据前像和回滚方案时,有如下几点需要考虑:
- 记录前像对正常写操作的影响有多大;
- 根据前像进行回滚,回滚的效率如何;
- 前像占用的空间如何,回收效率如何;
- 前像是高价值数据,可以基于前像提供一致性读(MVCC)、闪回等功能,前像的设计是否能高效地实现这些功能;
Oracle设计原理
开启一个事务
图2.2-1 undo segment header block结构
在开启事务之前,我们先了解一下undo segment header block的总体结构,如图2.2-1所示,undo segment header block的组成情况如下:
- undo segment header block既是1个block,又是1个segment header,所以cache layer、footer、segment control header、extent map也都是存在的(图中未标出),详细情况可以参考“空间管理与数据布局章节”;
- retention table:记录各extent最近一次提交的时间,从而在extent到期时回收空间给后继事务使用,详细情况见表2.2-1;
- transaction control:记录本undo segment中事务的总体信息,详细情况见表2.2-2;
- free block pool:记录当前使用过且有空闲空间的undo block,优先使用这些block(前面的事务未用满),详细情况见表2.2-3;
- transaction table:记录本undo segment中各个事务的详细信息,详细情况见表2.2-4;
表2.2-1 retention table部分关键信息
域 | 含义 |
Extent number | extent号 |
Commit time | 最近的提交时间,1970.1.1起始的秒数 |
表2.2-2 transaction control部分关键信息
域 | 长度 | 含义 |
seq | 2 | 新事务第1条undo记录所在block的seq,与uba中的seq相对应 |
chd | 2 | transaction table中的index,指向最老的事务,即优先被替换的事务 |
ctl | 2 | transaction table中的index,指向最新的事务,即最后被替换的事务 |
nfb | 2 | free block pool中的undo block数量,0表示没有空闲的undo block |
uba | 7 | 新事务的第1条undo记录的地址 |
scn | 6 | transaction table中最近1次被替换事务的提交scn,用于上界提交 |
表2.2-3 free block pool部分关键信息
一级域 | 二级域 | 含义 |
Array(*n) | uba | Undo block的地址 |
ext | Undo block所在的extent | |
spc | Undo block的空闲空间,单位字节 |
表2.2-4 transaction table部分关键信息
域 | 长度 | 含义 |
index | 0 | 事务的槽位号,对应于事务表的下标,不占用实际空间,事务id的组成部分之一 |
state |
| 9 unactive;10 active |
cflag | 1 | 0x00 无事务;0x10 死事务;0x80 active事务;0x90 正在被回滚的死事务 |
wrap | 2 | 本槽位每被事务复用1次加1,事务id的组成部分之一 |
uel | 2 | 指向下1个事务的槽位 |
scn | 6 | 事务提交时的scn,部分oracle版本在事务未提交时记录事务开始时的scn |
dba | 4 | 指向事务最近1条undo记录对应的data block |
nub | 4 | 事务使用的undo block数量 |
cmt |
| 事务提交时的时间 |
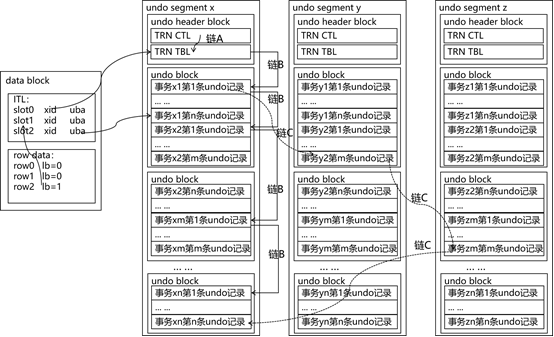
开启1个事务时,首先要到undo segment header block的transaction table中申请1个位置,该位置的下标就称为该事务id的组成部分之一。xid由segment no、transaction table index、wrap这3个部分组成。transaction table实际上就是1个大数组,该数组中元素每被复用1次,wrap就会加1。
开启的事务在transaction table中申请到位置后,会一直占用这个位置,直到该事务提交或回滚才有可能被其它事务覆盖。1个undo segment只有1个undo segment header block,受限于block的大小,transaction table一般只能提供34个槽位(随block大小而变化),即同时只能存放34个活跃事务。为此Oracle默认会创建10个undo segment,并根据并发事务的数量以及retention参数动态伸缩undo segment数量。
transaction control和transaction table是undo segment header block中最重要的信息,下面结合实例来讲解事务并发运行过程中,transaction control和transaction table是如何记录undo日志的。假设当前的transaction control和transaction table分别如下(仅保留说明原理的关键信息):
TRN CTL:
chd=index0 ctl=index34 uba=uba99 scn=scn32
TRN TBL:
index0: uel=index1 scn=scn78 dba=dba19 wrap=1
index1: uel=index2 scn=scn98 dba=dba12 wrap=1
index2: uel=index3 scn=scn107 dba=dba99 wrap=1
... ...
index33: uel=index33 scn=scn765 dba=dba72 wrap=1
index34: uel=0xFF scn=scn899 dba=dba31 wrap=1
从上例我们可以看出:
- 通过chd、ctl、uel可以将transaction table中的事务链在一起,这是我们见到第1个链表,为了说明方便,我们在本章节将其称为链表A;
- chd指向链表头,ctl指向链表尾;
- 整个链的顺序表达了事务提交的顺序,上例中的顺序是人为构造的,过于完美,实际上随着事务的频繁生成和消亡,指向顺序会比较杂乱;
针对上例,新开始的事务需要在此基础上申请1个位置,假设复用后的结果如下(仅保留说明原理的关键信息):
TRN CTL:
chd=index1 ctl=index0 uba=uba342 scn=scn78
TRN TBL:
index0: uel=0xFF scn=0 dba=dba26 wrap=2
index1: uel=index2 scn=scn98 dba=dba12 wrap=1
index2: uel=index3 scn=scn107 dba=dba99 wrap=1
... ...
index33: uel=index33 scn=scn765 dba=dba72 wrap=1
index34: uel=index0 scn=scn899 dba=dba31 wrap=1
假设新事务生成的第1条undo记录(该undo记录的地址未uda342,仅保留说明原理的关键信息)如下:
uda=uda99 ctl max scn=scn32 prev tx scn=scn78 prev brb=dba19
新事务复用transaction table的过程大致如下:
- 从transaction control中找到chd指针,遍历链表,直至找到第1个处于提交状态的事务,即scn最小的提交事务,上例中假设找到的即将被覆盖的位置为index0;
- 将index0从链表A中摘除,本例是从链首摘除,所以只需要修改chd,如果是中部或者尾部摘除,情况略有不同;
- 针对新事务生成该事务的第1条undo记录,记录被替换事务的scn和dba(分别对应第1条undo记录中的prev tx scn和prev brb),以及transaction control中的uda和scn(分别对应第1条undo记录中的uba和ctl max scn);
- 将transaction control中的scn更新为被替换事务的提交scn,用于将来的“上界提交”,将transaction control中的uda更新为新事务的第1条undo记录的地址,至此完成链B的组建,即本undo segment中的所有事务通过事务的第1条undo记录链在一起,根据链表B可以回溯任何时候的transaction control和transaction table(当然前提是undo日志还没有被清理掉);
- 根据新事务的信息更新index0,并在事务提交后将index0加入到链表A的尾部;
在上述过程中,已开始生成undo记录,那么就需要申请undo block来存放,undo block的申请规则如下:
- 查看free block pool中是否有空闲undo block,有则使用,否则转下一步;
- 当前extent有空闲undo block,有则使用,否则转下一步;
- 当前segment存在过期extent,重置该extent(wrap加1),然后使用该extent,否则转下一步;
- 如果undo tablespace有空闲空间,从中分配1个新的extent,并加入到本segment中并使用,否则转下一步;
- 从offline状态的segment中窃取1个过期的extent,加入到本segment中并使用,否则转下一步;
- 从online状态的segment中窃取1个过期的extent,加入到本segment中并使用,否则转下一步;
- 如果undo tablespace可以扩展,扩展undo tablespace,将新extent加入当前segment中并使用,否则转下一步;
- 如果undo segment中的retention时间设置为非担保,自动调整undo segment的保留时间,每次降低10%,寻找过期extent,如此循环直至找到;
Undo Block与Data Block
图2.2-2 undo block结构

通过上节介绍的方法找到了空闲的undo block,并向该undo block写入了本事务的第1条undo记录。对于单个undo block来说,同时只能属于1个活跃事务,所以从单个事务来看,其undo记录是相对集中的。当然如果事务已经提交,而该事务并没有用满某个undo block,该undo block的剩余空间会被其它事务使用。
undo block的结构如图2.2-2所示(忽略了cache layer和footer,这对所有block来说都是一样的):
- control section:记录本undo block的总体信息,详细情况见表2.2-5;
- record directory:undo记录的目录,array型,下标是uba的地址,指向undo记录在record heap中的位置,空间从上向下增长(uba由3个部分组成,undo dba. seq no. record no,通过undo dba定位到undo block,通过record no定位到目录,从而找到在record heap中的undo记录);
- record heap:存放具体的undo记录,空间从下向上增长,详细情况见表2.2-6;
表2.2-5 control section部分关键信息
域 | 长度 | 含义 |
xid | 8 | 最近1次操作本undo block的事务id |
cnt | 1 | 本undo block中的undo记录数 |
irb | 1 | 指向事务(对应于xid)的最近1条undo记录,回滚的起始点 |
表2.2-6 record heap部分关键信息
一级域 | 二级域 | 含义 |
record header | rec | 本undo记录在record directory中的下标,不占用实际空间 |
undo type | 组合标志位:
| |
objn | 本undo记录所涉data block对应的data object id | |
objd | object id | |
tblspc | tablespace no | |
rci | 指向同1个事务的上1条undo记录,0x00表示最后1条undo记录 | |
rdba | 用于单个undo block无法容纳事务的所有undo记录的场景,rdba指向本事务的下1个undo block 此情况一般仅出现在undo block的第1条undo记录中,其他undo记录该值都为0x00000000 | |
undo segment header | uba | 用于恢复transaction control中被覆盖的uba |
ctl max scn | 用于恢复transaction control中被覆盖的scn | |
prev tx scn | 用于恢复transaction table中被覆盖的scn | |
txn start scn | 记录新事务开始时的scn | |
prev brb | 用于恢复transaction table中被覆盖的dba | |
data block ITL | xid | 同data block中的ITL相对应,用于恢复某条ITL |
uba | ||
flg | ||
lck | ||
scn | ||
data block record | kdo op code |
|
bdba | undo记录对应的data block | |
hdba | undo记录对应的data block归属的segment header block | |
slot | undo记录所涉记录在data block中row directory的下标 | |
ncol | 记录前像数据,用于恢复UPDATE和DELTE所涉列 | |
nnew | ||
size | ||
cols |
如表2.2-6所示,单条undo记录包含如下信息:
- record header:记录的总体信息,如所涉data block对应的dba、object_id、tablespace,并通过rci将属于同一个事务的所有undo记录链在一起;
- undo segment header:可选,仅存在于事务的第1条undo记录中,用于恢复undo segment中的transaction control和transaction table;
- data block ITL:可选,用于恢复data block中被本事务覆盖的事务槽位上的事务信息;
- data block record:记录data block上被修改数据的前像:
- update:仅记录被修改列的前像;
- delete:记录被删除行的所有列的前像;
- insert:仅记录插入行的RowID(通过objn+bdba+slot计算得到);
表2.2-7 transaction layer:fixed部分关键信息
域 | 长度 | 含义 |
typ | 1 | 1 数据,2 索引 |
seg/obj | 4 | segment, object_id |
csn | 6 | 最近一次清除时的scn |
itc | 1 | 本data block中ITL的数量,即事务槽的个数,受参数INITRANS和MAXTRANS影响 |
flg | 1 | segment空间的管理方式:
|
fsl | 1 | 本data block的ITL中,第1个空闲的位置 |
fnx | 4 | 用于缓存管理 |
表2.2-8 transaction layer:ITL部分关键信息
域 | 长度 | 含义 |
xid | 8 | 事务id,4个字节的undo segment no+2个字节的transaction table slot no+2个字节的transaction table slot wrap |
uba | 8 | 本事务的最近1条undo记录的地址,4个字节的undo block地址+2个字节的seq number+1个字节的目录下标+1个字节的预留 |
flg | 1 | 事务状态,组合标志位: ---- 事务处于活跃态
--U- 事务已上界提交 ---T 相对于csn时刻,事务仍然处于活跃态 |
lck | 1 | 本事务在本data block中锁定的记录数(行数) |
scn/fsc | 6 |
|
现在我们再从data block的角度审视事务的运行过程,在“数据布局与空间管理”章节中,我们知道data block中与事务、数据强相关的部分为transaction layer:fixed+ITL,table directory,row directory,row data。当事务修改某data block中的数据时,首先要在data block的transaction layer:ITL中占用1个新的或者复用1个已处于提交状态的事务槽位。如果是复用槽位,新事务生成的undo记录需要记录被覆盖事务在ITL中的相关(详细情况见2.2-6的data block ITL,ITL槽位数量由initrans指定,普通场景默认2个,create table as select语句默认3个)。至此,我们接触到undo相关的第3个链表,用于按照data block维度将某个data block相关的所有事务的undo链在一起,我们将其称为链C。事务在修改data block中的实际数据时,row data中的lb会记录对应事务的槽位号,这样记录、事务、undo整个1张大网已经组建完成。
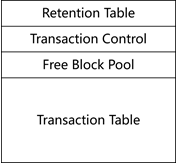
图2.2-3 undo链表关系全景图
如图2.2-3所示,我们得到了整个和undo相关的全景图:
- 链A:存在于undo segment header block中,可以将transaction control和transaction table中的事务链接在一起,方便事务申请;
- 链B:存在于undo segment内,将本undo segment内的所有事务通过第1条undo记录链接在一起,这样即使因为transaction control和transaction table中的事务信息发生了覆盖,所有的历史事务信息都可以通过链B进行回溯;
- 链C:存在于undo记录中,用于将某个data block相关的所有事务的undo链接在一起,这样即使因为transaction layer:ITL数量有限,事务被频繁覆盖,所有修改过本data block的所有事务的undo记录都可以通过链C进行回溯(为一致性读提供了条件);
- 对于仍然保留在transaction layer:ITL中的事务(活跃或已提交)则非常简单,通过xid可以找到undo segment header block中的transaction table中的详细信息,也可以直接通过uba访问到本事务的undo记录;
事务提交与Block清除
从undo的角度来看,事务的提交需要做下列工作:
- 工作1:找到undo segment header block,定位到transaction table中的对应位置,修改事务状态和提交scn,并记录redo日志;
- 工作2:遍历本事务修改过的所有data block,在其中的transaction layer:ITL找到本事务,修改事务状态和提交scn;
- 工作3:遍历本事务修改过的所有data block,在其中的row data部分,找到相关行并清理锁信息,记录redo日志;
工作1是一个常量,和事务修改的data block数量无关,且事务提交时工作1是必须实施的,这也是我们通常说的“事务提交”日志(redo日志)。
工作2的工作仅涉及transaction layer:ITL,位置相对固定,且不用记录redo日志,但又和修改的data block数量强相关,所以情况比较复杂:
- Oracle会在会话内存中跟踪本事务修改过的data block(有说最多1000个block,有说10%左右的缓存大小),事务提交时这些data block如果还在内存中,直接修改这些data block中的ITL,将flg打上C标志,表示事务已经提交,更新scn为事务的提交scn;
- 对于超出跟踪数量的data block,或者已经被换出缓存的data block,Oracle为了提高commit速度,不再处理这些data block,而是采用延迟块清除策略,即将更新事务状态和scn的工作延迟到将来再做。当将来某个事务读到该data block时,发现ITL中事务处于活跃状态:
- 读取对应的undo segment header block,发现该事务还处于transaction table中,且已经提交,将ITL中该事务的flg打上C标志,并更新事务的提交scn;
- 读取对应的undo segment header block时,发现该事务所在的transaction table已经被覆盖,将ITL中该事务的flg打上CU标志,并事务的提交scn更新为transaction control中的scn,这就是“上界提交”,即在该scn时刻事务一定已经提交了,但也可能在这之间已经提交。Oracle通过上界提交在效率和准确度之间做了一个平衡,上界提交通过最小的代价找到尽可能老的scn,将来一致性读构建CR时,如果scn已经满足要求那最好,如果不满足要求再通过undo(链B)进一步回溯,找到更新精准的提交scn(实际上找到满足一致性判断要求的scn即可);
可见对于工作2,Oracle采取了综合措施,在commit效率和ITL准确度之间做了平衡。延时块清除将大量工作分解到将来的各个data block的读过程中。工作3是最耗时的,既要找到data block中的行记录(行记录会在data block内部移动),又要记录redo日志,Oracle的策略是将工作3延期分解到将来的data block读上,这也是为什么读操作有时也产生redo日志的原因。
用户回滚与重启回滚
用户回滚时,其中一个线索是通过undo segment header block中的transaction table找到该事务,再根据其中记录的dba获取本事修改的最近的data block,通过该data block中的ITL:uda获取该事务的最后1条undo记录,而undo记录是链在一起的,至此可以顺利实施回滚。实际执行用户回滚更加容易,因为内存中拥有完备的跟踪信息,可以加速上述过程。
重启回滚和上述类似,不同的是不存在内存加速(重启了),而是通过扫描所有undo segment header block获得所有待回滚事务及其入口信息。
另外需要说明的是实施回滚时除了data block的修改要记录redo日志外,undo block中的undo记录也要打上“user undo applied”标签,也需要记录redo日志,防止重复回滚。
一致性读
本节仅讲述Oracle基于undo记录构建一致性读的过程(构建CR),至于背后的理论基础请参考“事务”章节。假设事务A的启动scn为scn_a,事务A读取某个data block时,首先对该data block做延迟块清除。如果ITL中的事务都处于提交状态,且scn都小于scn_a则不需要构建CR,直接读取即可,否则需要构建CR:
- 步骤1:在缓存区中对当前data block做一个拷贝,即CR;
- 步骤2:反向更改所有未提交事务;
- 步骤3:如果有事务提交scn大于scn_a,应用该事务的undo日志;
- 重复上述步骤3,直至所有事务的scn小于等于scn_a;
因为构建CR并不是实际更新数据,所以不需要记录undo和redo。至于CR版本的生命周期,Oracle综合应用了数量控制(有说1个data block至多3个CR)和缓存控制策略。
闪回
既然数据库内部可以通过undo记录构建CR版本实现读取历史数据的功能,该功能自然可以开放给用户直接使用,这就是闪回查询。当然还可以更进一步,对表进行闪回,即将数据回退到过去某个时间,解决用户误操作问题。闪回drop和闪回database有所不同,前者是将recyclebin中的对象重新可见,后者除了将前像放在undo tablespace中,还想日志归档一样,将前像归档到闪回日志中,用于更大规模的闪回,但基本原理是一致的。
MySQL设计原理
开启一个事务
事务的开启与undo segment强相关,但MySQL的特殊地方在于发明了rollback segment和undo log segment这2个概念。rollback segment用于存放总体信息,而undo log segment用于存放具体的undo日志记录。
图2.3-1 rollback segment page结构

表2.3-1 ROLLBACK PAGE HEADER结构
域 | 长度 | 含义 |
TRX_RSEG_MAX_SIZE | 4 | rollback segment允许使用的最大page数,当前值为ULINT_MAX |
TRX_RSEG_HISTORY_SIZE | 4 | history list上undo page数量 |
TRX_RSEG_HISTORY | 16 | 链表指针头,指向history list链表 |
TRX_RSEG_FSEG_HEADER | 10 | 本rollback segment对应的INODE Entry的地址 |
rollback segment只有1个page(type为FIL_PAGE_TYPE_SYS),如图2.3-1所示,rollback segment page由如下关键部分组成:
- TRX_RSEG_UNDO_SLOTS:每个slot对应1个undo log segment,1个rollback segment可以管理1024个undo log segment。slot本身仅占用4个字节,记录是undo log segment header page的page no,没有space id,所以rollback segment及其管理的undo log segment必须在同一个undo tablespace中;
- ROLLBACK PAGE HEADER:存放了rollback segment的总体信息,详细情况如表2.3-1所示,其中最重要的是TRX_RSEG_HISTORY,其为链首指针,通过和UNDO LOG HEADER中的TRX_UNDO_HISTORY_NODE组成history list链表,将所有归属于本rollback segment且已经提交的undo log链接在一起;
图2.3-2 rollback segment 总体布局
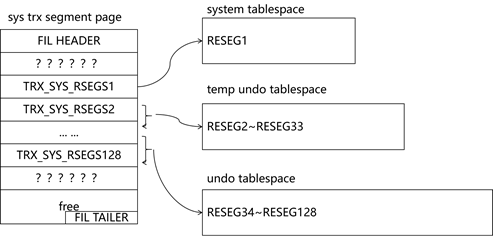
开始事务需要在rollback segment中找到1个slot,那又是如何找到rollback segment的呢?如图2.3-2所示,在“空间管理与数据布局”章节中我们知道系统tablespace中有1个sys trx segment,该segment中的sys trx segment page中存放了128个RSEG地址,其中:
- 第1个rollback segment预留在系统tablespace中;
- 第2~33个rollback segment存放在临时tablespace中;
- 第34~128个rollback segment存放在独立的undo tablesapce中;
如此就可以获得所有rollback segment的入口。开始事务时,MySQL默认为只读事务,当后继发生写操作时,转换为读写模式,为事务分配事务id和rollback segment,分配方式如下:
- 如果事务操作了临时表,为其分配临时表rollback segment(2-33,临时表的undo无需记录redo);
- 采用round-robin的方式分配rollback segment(34~128),不过在遍历的过程中,如果某个rollback segment的history list过长,意味着该rollback segment已经非常大了,会跳过该rollback segment,继续遍历下一个rollback segment;
Undo Log Segment
在上一节我们知道MySQL定义了rollback segment和undo log segment两种segment,rollback segment负责管理作用,undo log segment则负责记录具体的undo日志。
图2.3-3 undo log segment header page & normal undo log page

undo log segment包含1个header page和若干个normal page,rollback segment中的TRX_RSEG_UNDO_SLOTS记录的就是header page的page no。如图2.3-3所示,两种page基本类似,只是header page多了1个UNDO LOG SEGMENT HEADER,而normal page对应的区域为空。下面详细了解一下各个组成部分之间的关系:
- UNDO LOG PAGE HEADER用于描述本page的总体信息,详细情况见表2.3-3,而UNDO LOG SEGMENT HEADER则描述本segment的总体信息,详细情况见表2.3-2;
- MySQL出于效率考虑,将undo log segment分为TRX_UNDO_INSERT和TRX_UNDO_UPDATE。因为一旦事务提交完成,insert的undo日志就可以释放,不需要用于多版本并发控制,将insert区分出来,可以集中管理,高效释放;
- 1个undo log segment同时只能被1个事务使用,1个事务可以使用多个undo log segment(例如事务既有delete,也有insert,就需要申请2个undo log segment,分别记录delete和insert的undo日志)。这样在极限情况下,系统最多支持((128-32)*1024)/2个并发事务(此数据是假设所有事务都包含insert和非insert类写操作);
- SEGMENT HEADER中的TRX_UNDO_PAGE_LIST和PAGE HEADER中的TRX_UNDO_PAGE_NODE将本undo log segment中所有的undo page链接在一起,方便管理;
表2.3-2 UNDO LOG SEGMENT HEADER结构
域 | 长度 | 含义 |
TRX_UNDO_STAT | 2 | undo log segment的当前状态:
|
TRX_UNDO_LAST_LOG | 2 | 最近1条undo log的header在page内的偏移 |
TRX_UNDO_FSEG_HEADER | 10 | 记录本segment对应的INODE Entry的地址 |
TRX_UNDO_PAGE_LIST | 16 | 链表头,将所有属于本undo log segment的page链接在一起 |
表2.3-3 UNDO LOG PAGE HEADER结构
域 | 长度 | 含义 |
TRX_UNDO_PAGE_TYPE | 2 | undo日志的类型:
|
TRX_UNDO_PAGE_START | 2 | 本page中最近1条undo日志的位置 |
TRX_UNDO_PAGE_FREE | 2 | 本page中空闲空间的偏移量 |
TRX_UNDO_PAGE_NODE | 12 | 链表的双向指针,用于将本undo log segment中的所有page链接在一起 |
图2.3-4 UNDO LOG结构

表2.3-4 UNDO LOG HEADER结构
域 | 长度 | 含义 |
TRX_UNDO_TRX_ID | 8 | 产生本条undo log的事务id |
TRX_UNDO_TRX_NO | 8 | 仅对update undo日志有效,加入history list的UNDO LOG RECORD数量 |
TRX_UNDO_DEL_MARKS | 2 | 是否有delete mark操作 |
TRX_UNDO_LOG_START | 2 | UNDO LOG RECORD开始的位置 |
TRX_UNDO_DICT_OPERATION | 2 | 是否是DDL |
TRX_UNDO_TABLE_ID | 8 | 若是DDL,记录table id |
TRX_UNDO_NEXT_LOG | 2 | 下一个undo log header的位置 |
TRX_UNDO_PREV_LOG | 2 | 上一个undo log header的位置 |
TRX_UNDO_HISTORY_NODE | 12 | 双向指针,用于构建history list链表 |
表2.3-5 INSERT型UNDO LOG RECORD结构
域 | 长度 | 含义 |
NEXT | 2 | 本条undo log record结束的位置 |
TYPE_CMPL | 1 | 日志类型,取值TRX_UNDO_INSERT_REC表示INSERT型 |
UNDO_NO | compact | 同1个undo log header下各个undo log record顺序编号 |
TABLE_ID | compact | 对应的表id |
PRIMARY KEY | var | 主键列的长度和取值: primary_col1_len primary_col1_val primary_col2_len primary_col2_val ... ... primary_colN_len primary_colN_val |
START | 2 | 本条undo log record的起始位置 |
表2.3-6 UPDATE型UNDO LOG RECORD结构
域 | 长度 | 含义 |
NEXT | 2 | 本条undo log record结束的位置 |
TYPE_CMPL | 1 | 日志类型及标志位 标志位:
日志类型:
|
UNDO_NO | compact | 同1个undo log header下各个undo log record顺序编号 |
TABLE_ID | compact | 对应的表id |
INFO_BITS | 1 | 标志位 |
DATA_TRX_ID | compact | 修改前,原记录上的事务id(隐藏列) |
DATA_ROLL_PTR | compact | 修改前,原记录上的回滚指针(隐藏列) |
PRIMARY KEY | var | 主键列的长度和取值: primary_col1_len primary_col1_val primary_col2_len primary_col2_val ... ... primary_colN_len primary_colN_val |
UPDATE VECTOR | var | 记录被更新列的前像(列位置、长度、前像): upd_col1_pos upd_col1_len upd_col1_val upd_col2_pos upd_col2_len upd_col2_val .. ... upd_colN_pos upd_colN_len upd_colN_val |
N_BYTES_BELOW | compact | INDEX_COLUMS部分的总长度 |
INDEX_COLUMS | var | 所有二级索引的前像(包括所有主键列和索引列)(列位置、长度、前像): upd_col1_pos upd_col1_len upd_col1_val upd_col2_pos upd_col2_len upd_col2_val .. ... upd_colN_pos upd_colN_len upd_colN_val |
START | 2 | 本条undo log record的起始位置 |
如图2.3-4所示,每条undo log由1个undo log header和若干条undo log record组成,每条undo log record保持数据的前像,和data block中的一条row data相对应,具体情况如下:
- undo log header:存放本条undo log的总体信息,详细情况如表2.3-4所示,其中TRX_UNDO_NEXT_LOG和TRX_UNDO_PREV_LOG用于将本undo log segment header page中的所有undo log header链接在一起(undo log segment可以被事务复用),而TRX_UNDO_HISTORY_NODE是history list链表的组成部分,用于将所有提交事务的undo log header(不含insert型)链接在一起,为将来purge打好基础;
- undo log record:分为insert型和update型,存放在不同的undo log segment中,insert型不用于构造MVCC,事务提交后对应的undo log segment就可以立刻释放;
delete和update将来都需要用于构造MVCC,所以对应的undo log record不能立刻释放。原始data page中的每条记录保存有当前事务id和指向undo log record的回滚指针,这就要求删除操作不能真正的实施,否则隐藏列无处存放。undo log record还保存了该条数据记录隐藏列上的前事务id和回滚指针,这样就可以回溯到该记录的任意历史版本(只要undo log record还在)。对于二级索引来说,二级索引上的update,MySQL都是转换为delete+insert。有了这些背景之后,我们再来看MySQL在undo log record记录了哪些内容:
- delete:生成类型为TRX_UNDO_DEL_MARK_REC的undo log record,主键索引和二级索引都不实施真正的删除,都是打上删除标签,undo log record中需要记录主键值(PRIMARY KEY)和二级索引列值(INDEX_COLUMS);
- update:生成类型为TRX_UNDO_UPD_EXIST_REC的undo log record,记录主键值(PRIMARY KEY)和更新列的前像(UPDATE VECTOR),以及二级索引相关列的前像(INDEX_COLUMS)。二级索引上的update实际上是delete+insert,所以需要记录二级索引的全部前像;
- insert:生成类型为TRX_UNDO_INSERT_REC的undo log record,记录主键值(PRIMARY KEY)。还有一种特殊情况,某条记录已经被打上删除标签,这时再次插入相同主键的行,这时生成类型为TRX_UNDO_UPD_DEL_REC的undo log record,记录主键值(PRIMARY KEY)和更新列的前像(UPDATE VECTOR),以及二级索引相关列的前像(INDEX_COLUMS);
图2.3-5 UNDO全景图
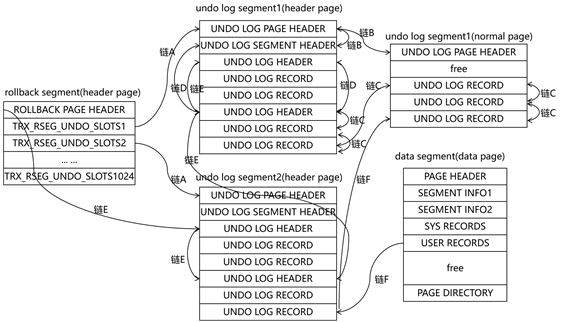
最后我再回顾总结一下undo的全貌,如图2.3-5所示:
- 每个rollback segment有1个header page,每个undo log segment有1个header page和若干个normal page;
- 每个事务可以有多个undo log,但单个undo log只能属于1个事务。对于某个具体的undo log segment来说,1个事务只有1个undo log;
- 1个undo log segment同时只能属于1个事务,但当undo log segment仅使用了header page,且该header page至少有1/4空闲空间时,该undo log segment在上一个事务提交后可以被下一个事务复用,所以有时header page中有多个undo log header;
- 链A:每个rollback segment通过1024个slots可同时管理1024个活跃态的undo log segment;
- 链B:UNDO LOG SEGMENT HEADER中的TRX_UNDO_PAGE_LIST结合UNDO LOG PAGE HEADER中的TRX_UNDO_PAGE_NODE,将本undo log segment中的所有undo page链接在一起;
- 链C:UNDO LOG HEADER中的TRX_UNDO_LOG_START结合UNDO LOG RECORD中的NEXT和START,将本undo log中的所有undo log record链接在一起;
- 链D:UNDO LOG SEGMENT HEADER中的TRX_UNDO_LAST_LOG结合UNDO LOG HEADER中的TRX_UNDO_NEXT_LOG、TRX_UNDO_PREV_LOG,将本undo log segment中的所有undo log链接在一起;
- 链E:ROLLBACK PAGE HEADER中的TRX_RSEG_HISTORY结合UNDO LOG HEADER中的TRX_UNDO_HISTORY_NODE,将所有已经提交的undo log链接在一起(不含insert和cached);
- 链F:user records中的DATA_ROLL_PTR隐藏列结合undo log record中的DATA_ROLL_PTR,将和某条记录相关的所有undo log record链接在一起,为MVCC打下基础;
事务提交
MySQL和InnoDB是松耦合结构,为了协调上下层的提交一致性,采用了2阶段提交。不过从undo的角度来看,prepare阶段的工作不多,但还是要将UNDO LOG SEGMENT HEADER中的TRX_UNDO_STAT从TRX_UNDO_ACTIVE改为TRX_UNDO_PREPARED,并更新其它一些信息。重点工作发生在commit阶段:
- 如果是insert型undo log segment,将TRX_UNDO_STAT设置为TRX_UNDO_TO_FREE,后继直接释放;
- 如果是update型undo log segment,只有1个page且page的空闲空间至少有1/4,将TRX_UNDO_STAT设置为TRX_UNDO_CACHED,并将本undo log segment加入到undo cache list中,以供将来复用(undo cache list是内存结构);
- 如果是update型undo log segment,不满足只有1个page且page的空闲空间至少有1/4,将TRX_UNDO_STAT设置为TRX_UNDO_TO_PURGE,同时将rollback segment中对应的slot置为FIL_NULL,并将本undo log segment(undo log header)加入到TRX_UNDO_HISTORY_NODE中(链E),等待被清理(不再用于MVCC后即可被清理);
用户回滚与重启回滚
当用户主动或者数据库内部原因对事务发起回滚时,内存中保存有相关对象和指针,直接进行逆向操作即可,主要包括如下动作:
- 二级索引对主键索引有依赖关系,所以先回滚二级索引,再回滚主键索引;
- 对于打上删除标记的记录,清理删除标记;
- 对于更新操作,将数据回退到前像版本;
- 对于插入操作,直接删除记录;
重启回滚涉及的动作和用户回滚类似,但重启内存丢失,需要根据以下原则找到回滚记录:
- 遍历所有rollback segment,根据每个rollback segment中的slot遍历undo log segment;
- 如果undo log segment的TRX_UNDO_STAT为TRX_UNDO_ACTIVE,表示需要回滚,按照类似用户回滚的动作进行回滚;
- 如果undo log segment的TRX_UNDO_STAT为TRX_UNDO_PREPARED,比较事务的XID与binlog,如果binlog已经完成,则走提交流程,否则走回滚流程;
一致性读
RR隔离级别下一致性读的原则:事务开始时所有已经提交的事务对本事务来说都是可见的,所有未提交以及将来启动的事务对本事务来说都是不可见的。为此,开启事务时需要根据当前系统的活跃事务情况构建一个属于本事务的ReadView,包含如下要素:
- up_limit_id:最小活跃事务id,比该id小的事务对本事务来说都是可见的;
- low_limit_id:最大事务id,比该事务id大的事务都是在本事务开启之后生成的,所以对本事务来说都是不可见的;
- trx_ids:trx_ids为本事务开启时系统活跃事务列表的快照,对于up_limit_id和low_limit_id之间的所有事务,如果在trx_ids中表示本事务开启时该事务处于活跃态,尚未提交,所以不可见,否则可见;
图2.3-6 可见性判断
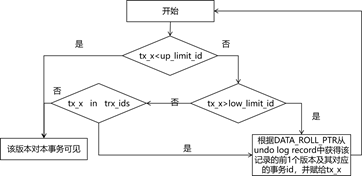
数据记录中有事务id和回滚指针的隐藏列,而每条undo log record中也有上1个事务id和指向上1个undo log record的指针,通过这些事务id和回滚指针,按照图2.3-6中的原则就可以进行无锁的一致性读。在RC场景下,原则和RR场景基本一致,不同的是RR在事务开始时建立ReadView,而RC在每条SQL语句开始前都要建立一个新的ReadView。
Purge
一致性读机制不再读到的这些历史版本就需要及时被清理掉,以便及时释放出undo空间。为此,获得系统中最老的ReadView,比该ReadView中up_limit_id小的事务对应的undo log都可以被清理掉。方法是遍历各个rollback segment的TRX_RSEG_HISTORY链表,链表中事务id小于up_limit_id的undo log都可以被清理掉。清理的动作主要包括2个方面:
- 清理记录:清理二级索引和主键索引中删除标记为真的记录;
- 清理undo:清理undo log和undo log segment;
PostgreSQL设计原理
Page与前像设计
图2.4-1 page结构
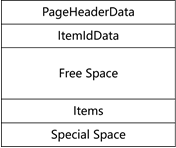
表2.4-1 PageHeaderData结构
域 | 长度 | 含义 |
pd_lsn | 8 | 本page被修改的lsn |
pd_checksum | 2 | 校验值,检查page异常 |
pd_flags | 2 | Page状态,组合标志位:
|
pd_lower | 2 | Free space的起始位置 |
pd_upper | 2 | Free space的结束位置 |
pd_special | 2 | Special space的位置 |
pd_pagesize_version | 2 | 高位字节表示page大小,低位字节表示版本号 |
pd_prune_xid | 4 | 本page最老的事务id,vacuum时使用 |
表2.4-2 ItemIdData结构
域 | 长度 | 含义 |
lp_off | 15bit | 记录在Items中的位置 |
lp_flag | 2bit | Item状态:
|
lp_len | 15bit | 在Items中的长度 |
PostgreSQL采用异地更新方案,前像没有存放在独立的undo区域中,而是和数据一起存放在data page中。因此,在研究PostgreSQL回滚前,有必要先了解一下page结构。如图2.4-1所示,page由如下部分组成:
- PageHeaderData:头部,定义了整个page的总体信息,详细情况见表2.4-1;
- ItemIdData:目录信息,每行记录占1个位置,其下标是后继定位该记录的重要组成部分,详细情况见表2.4-2,随着记录的增加,目录从上向下增加;
- Items:用户数据,随着记录的增加,数据从下向上增加;
- Special Space:存放和访问方法相关的数据,如对于BTree索引存放左右兄弟节点的指针,普通表page为空;
图2.4-2 Item结构

表2.4-3 HeapTupleHeaderData结构
域 | 长度 | 含义 |
t_xmin | 4 | insert本记录的事务id |
t_xmax | 4 | delete/update本记录的事务id |
t_cid/t_xvac | 4 | Insert/delete时的事务id和命令id |
t_ctid | 6 | 本记录下一个版本的地址,如果自己是最新版本则指向自己 |
t_infomask2 | 2 | 低11位表示当前记录的列数; 其它位为标志位:
|
t_infomask | 2 | 组合标志位:
|
t_hoff | 1 | 记录头大小 |
Item存放一条具体的记录,如图2.4-2所示,Item由HeapTupleHeaderData、NullBitmap、ObjectId、UserData 4个部分组成:
- HeapTupleHeaderData:记录头,固定大小,t_xmin和t_xmax用于判断记录在事务间的可见性判断,t_cid用于记录在本事务内的可见性判断,t_ctid用于将记录的多个版本链接在一起,详细情况见表2.4-3;
- NullBitmap:可选,t_infomask中HEAP_HASNULL标志位为真时有此字段,用于表达相关列是否为null;
- ObjectId:可选,t_infomask中HEAP_HASOID_OLD标志位为真时有此字段;
- UserData:真正的用户数据;
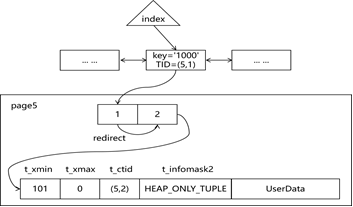
图2.4-3 前像设计示例

了解了PostgreSQL的page和item设计,下面来看PostgreSQL是如何进行异地更新的,如图2.4-3所示,DML主要包括下面3种情况:
- Insert:insert直接插入数据,不需要记录前像,t_xmin记录插入本记录的事务id;
- Delete:delete不进行实际删除,记录本身就是前像,t_xmax记录删除本记录的事务id;
- Update:不进行本地更新,而是克隆1个新记录,然后在新纪录上更新(实际上是delete+insert),旧记录就是前像,并将旧记录的t_ctid指向新记录的位置,从而形成一个旧记录指向新记录的链表;
可见PostgreSQL通过上述方法保存了前像,同时通过clog、记录中的ItemIdData.lp_flag、记录中的t_infomask保存相关事务的状态,这样就可以合理地应用保存的前像。当然记录中的ItemIdData.lp_flag和t_infomask的状态可能不是最新的,需要后台根据clog中的真实状态进行刷新。
用户回滚
PostgreSQL采用异地更新的最大优势就是回滚。由于前像仍然以记录的方式存在于数据当中,所以用户回滚只需要记录事务的状态,释放相关资源即可,非常高效。至于遗留下来的垃圾数据,通过后台进程逐步清理即可。
一致性读
和MySQL类似,PostgreSQL也采用基于事务id的一致性读,该方法需要获取当前的活跃事务id列表,PostgreSQL将其称为transaction snapshot。RR或者SERIALIZABLE隔离级别下,事务在启动时会生成本事务的transaction snapshot。RC隔离级别下,每条SQL语句执行前生成最新的transaction snapshot。
由于PostgreSQL采用的是异地更新,一致性判断的规则更加复杂,需要综合判断事务状态、t_xmin、t_xmax和transaction snapshot,具体规则如下:
- 类别1:t_xmin的事务状态为ABORTED
插入此条记录的事务已经回滚,所以本记录对任何事务都不可见。
- 类别2:t_xmin的事务状态为IN_PROGRESS
R1: t_xmin=current_txid & t_xmax=INVALID -> visible
R2: t_xmin=current_txid & t_xmax!=INVALID -> invisible
R3: t_xmin!=current_txid -> invisible
R1表示当前事务读取本事务之前插入的数据,所以可见。R2表示该记录虽然是本事务插入的,但已被本事务删除,所以不可见。R3表示当前事务读取其它事务插入的记录,且其它事务尚未提交,所以不可见。
- 类别3:t_xmin的事务状态为COMMITTED
R4: snapshot(t_xmin)=active -> invisible
R5: t_xmax=INVALID | status(t_xmax)=ABORTED -> visible
R6: status(t_xmax)=IN_PROGRESS & t_xmax=current_txid -> invisible
R7: status(t_xmax)=IN_PROGRESS & t_xmax!=current_txid -> visible
R8: status(t_xmax)=COMMITTED & snapshot(t_xmax)=active -> visible
R9: status(t_xmax)=COMMITTED & snapshot(t_xmax)!=active -> invisible
判断规则是R4到R9依次判断,一旦满足条件就以此结果为依据。R4表示插入这条记录的事务虽然已经提交了,但该事务仍然在snapshot中,所以不可见。R5表示没有其它事务更新过该记录或者更新过该记录的事务已经回滚,所以可见。R6表示本事务已经更新过该记录,所以该记录的上一个版本不可见。R7表示其它事务正在更新该记录,所以该记录的上一个版本可见。R8表示更新或删除该记录的事务已经提交,但该事务在snapshot中,所以可见。R9表示更新或删除该记录的事务已经提交,但该事务不在snapshot中,需要看更新的版本,所以不可见。
HOT与Index-Only Scan
图2.4-4 索引与记录关系示意图(非HOT)
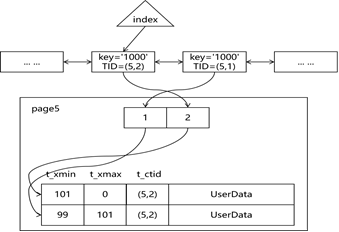
如图2.4-4所示,由于记录采用了异地更新,当记录生成一个新的版本时,为了保持同步,索引项不管有没有发生变化,都需要生成一个对应的新版本,和相应的数据记录对应起来。这导致了索引不必要的浪费,并为后继的vacuum带来了额外的负担。
图2.4-5 索引与记录关系示意图(HOT)
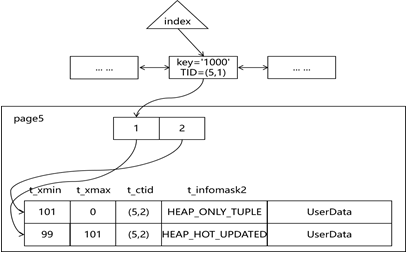
图2.4-6 索引与记录关系示意图(HOT, After Prune)

图2.4-7 索引与记录关系示意图(HOT, After Defragmentation)
HOT指当更新同时满足:1)新版本的记录和旧版本的据在同一个page内;2)更新的列不涉及索引列时,索引不再生成新版本,从而解决索引成本过高的问题。上述条件2很容易理解,条件1的主要目的是平衡读性能,否则通过索引访问很可能需要2次page调度,即先通过索引定位到旧版本,然后再通过旧版本的c_ctid或者ItemIdData中重定向定位到新版本。
如图2.4-5所示,HOT生效时索引仍然指向旧记录,新记录通过旧记录的t_ctid访问,同时旧记录的t_infomask2打上HEAP_HOT_UPDATED标志,新记录的t_infomask2打上HEAP_ONLY_TUPLE标志。当旧记录的状态为dead后,图2.4-6和图2.4-7分别给出修剪(prune)和去碎片化(defragmentation)实施后的情况,旧记录的ItemIdData保留,并重定向到记录的ItemIdData上。
Index-Only Scan指索引中已包含查询所需所有列,原则上直接扫描或定位索引page,无需扫描或定位数据page即可完成本次查询。PostgreSQL的一致性判断规则复杂,且依赖于数据page中各记录的t_xmin、t_xmax及其状态信息,从而导致Index-Only Scan无法实施。为此,PostgreSQL采用了一个简单直接的办法,在后台维护一个visibility map,一旦确定某个数据page中的所有记录都是可见的,就将该page加入到visibility map中,直接对外可见。这样扫描索引时,如果发现对应的数据page在visibility map中就仅扫描索引,不再访问数据page,否则仍然访问数据page,根据记录的t_xmin和t_xmax及其相应状态进行可见性判断。
Vacuum
从前面几个小节我们知道数据page和索引page都会有过期数据(dead tuple),vacuum的工作主要就是清理这些过期数据。vacuum分为concurrent vacuum和full vacuum,前者允许vacuum期间并发执行其它只读事务,后者不允许vacuum期间执行其它事务,但两者的实现原理是一致的。
concurrent vacuum的主要工作是针对某个特定的table或所有table执行如下任务:
- 清理dead tuple,即删除无用的数据前像:
- 删除数据page中的dead tuple,并对数据page做去碎片化整理;
- 删除索引page中指向dead tuple的索引记录;
- 冻结过期txids,PostgreSQL的txid只有4个字节,需要及时清理,以解决循环使用的问题:
- 冻结过期的txids;
- 更新系统catalogs;
- 清理不必要的clog;
- 其它任务:
- 更新FSM和VM;
- 更新系统统计项;
concurrent vacuum的大致实现过程如下:
- step1:从table list中获取某个待实施的table;
- step2:针对该table申请UpdateExclusiveLock,该锁仍然允许其它事务读本table;
- step3:扫描本table中所有数据page,识别出所有dead tuple,必要时冻结过期txids;
- step4:删除指向dead tuple的所有索引记录;
- step5:针对本table的每个数据page,重复step6和step7;
- step6:删除dead tuple,并做去碎片化工作;
- step7:更新FSM和VM;
- step8:如果数据page中不再含有任何tuple,释放该数据page;
- step9:更新统计信息和catalogs;
- step10:清理不必要的clog page和clog文件;
其中第3步是将扫描的结果存放在内存中(maintenance_work_mem),如果内存已满则开始实施第4步到第8步,然后清理内存,并回到第3步从上次断点开始继续扫描。
总结与分析
首先来看记录前像对正常写操作的影响,下面从DML操作类型和索引的角度来分析:
- insert:Oracle和MySQL都会生成1条undo记录,PostgreSQL无需做额外处理;
- delete:Oracle和MySQL都会生成1条undo记录,PostgreSQL只需设置相关状态;
- update:Oracle和MySQL会生成1条undo记录,仅记录更改列的前像,PostgreSQL需要完整克隆1条新记录,并更改旧记录的状态;
- 索引:Oracle将索引当数据,数据与索引的处理方式一致。MySQL的索引不记undo,而是通过数据的undo间接记录索引的变化。PostgreSQL的索引页采用异地更新,但不记录事务状态,同时HOT方式进行一定程度的优化。当然对于索引来说,索引列的更新涉及索引记录在BTree中位置的调整,所以Oracle和MySQL都是将索引的update转换为delete+insert,即异地更新方案;
总的来说Oracle、MySQL、PostgreSQL相差不大,insert、delete操作PostgreSQL更加轻量,而update操作Oracle、MySQL相对较为轻量。但Oracle在设计上相对更加简洁,索引、数据的处理原则基本一致,没有太多的特殊情况要考虑。
其次看回滚效率,PostgreSQL是最高效的。PostgreSQL的前像就再数据之中,只需要记录事务的状态,不需要实施回滚动作。Oracle和MySQL则厚重得多,需要从undo日志中读出前像,并应用到实际数据和索引上,同时还要记录重做日志。
再次看存储效率,我们还是从DML操作类型、数据和索引这几个角度来看:
- insert:Oracle仅记录RowID,MySQL记录主键值,PostgreSQL不需要做额外记录;
- delete:Oracle需要记录整条记录的前像,MySQL记录主键值,PostgreSQL不需要做额外记录;
- update:Oracle需要记录被更新的列,MySQL记录主键值和被更新的列,PostgreSQL需要拷贝一个完整的新行(所有列);
- 记录:Oracle的记录不需要做太多特殊处理,MySQL需要引入13个字节的事务id和回滚指针,PostgreSQL需要引入22个字节的t_xmin、t_xmax、t_cid、t_ctid、t_infomask、t_infomask2;
- 索引:Oracle的索引处理等同于数据,MySQL需要将索引的所有列记录在数据的undo中,并将update转换为insert+delete,PostgreSQL需要生成新的索引记录;
从数据的前像来看,对于insert和delete操作,PostgreSQL基本不消耗存储空间;对于update操作,Oracle和MySQL优于PostgreSQL,因为前者仅需要记录被更新列的前像。对于delete操作,Oracle和MySQL都是在原记录上打上删除标签,但Oracle会在undo中记录整条记录的前像,而MySQL仅记录主键值。虽然MySQL更省空间,但Oracle将undo和数据block清理的工作完全解耦,没有依赖关系,且为将来的闪回提供了可能。从对记录的影响来看,Oracle是最优的,MySQL其次,PostgreSQL最后,虽然单条记录占用的字节数不是太多,但对于大数据量的窄表(表的列数很少,但记录非常庞大)来说,占用的空间会比较可观。
再再次看回收效率。Oracle在undo segment中维护retention table,直接按照时间将相关extent失效即可,不需要做太多的回收动作,block上的事务状态主要集中在ITL上,调整面也比较小。MySQL相对复杂一点,通过rollback segment和undo log segment进行日志管理,1个undo log segment同时只能服务于1个事务,segment的管理成本比Oracle高,但通过history list进行回收,回收涉及的undo page也相对比较集中。Page上基本不涉及事务状态,调整面最小。PostgreSQL的前像和数据存放在一起,需要通过扫描所有page确认dead tuple,成本非常高,事务状态涉及每条记录,调整面也非常大。
最后看一致性读和闪回。Oracle通过undo日志和scn进行一致性判断,简洁高效。MySQL和PostgreSQL分别需要维护read view和transaction snapshot,高并发时事务列表会很长,活跃事务列表的比较效率也较低,且每个事务都需要维护一个read view或transaction snapshot,RC隔离级别下每执行一次SQL还需要更新一次。虽然MySQL和PostgreSQL原理相似,但由于PostgreSQL涉及t_xmin、t_xmax、t_maskinfo、transaction snapshot、clog,判断规则极其复杂,效率最低。在扫描数据和索引时,涉及多个版本(关键看vacuum的频率),虽然VM可以有一定程度的缓解,但效率要低于Oracle和MySQL。
原则上只要前像存在,就可以提供闪回功能。Oracle在系统中维护有逻辑时间(scn),且可以和墙上时间转换,事务提交时记录当时的scn,这样就可以基于scn和墙上时间进行闪回查询和闪回恢复。MySQL和PostgreSQL当前还没有提供闪回功能,提供该功能的挑战在于:1)可以基于LSN进行闪回回退,但需要对当前的前像回收机制进行较大幅度的调整;2)当前的可见性判断机制是基于read view和transaction snapshot的,该机制无法复用到闪回查询,因为用户并不知道历史某个时刻的read view和transaction snapshot。
相关文章
- 六西格玛与商业分析:蒙特卡罗模拟
- 特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】
- 元宇宙基础设施:WEB 3.0 chain33 优势分析
- 找亮点!2020年数据交换网络领域专利态势
- mysql 客户端报错案例一例
- MySQL 中view的常用操作
- MongoDB yum安装及遇到的小问题
- MySQL开源生态工具简单汇总
- 深入浅出MySQL复制--MySQL的"核心科技"
- Numpy库的简单用法(2)
- Numpy库的简单用法(3)
- 那么普通却那么自信,Presentation也内卷!
- MySQL查询表索引的方式
- MySQL字符串类型和数字类型索引的效率
- MYSQL多表联合查询
- redis在php中使用的笔记
- 虹科新闻|虹科与Telco Systems正式建立合作伙伴关系
- 灵活而防篡改的内区块链模式设计
- MySQL InnoDB数据恢复,丢失ibdata1时怎么安全恢复
- MYSQL一些不常用的函数笔记