
阿里云视频摘要SOTA模型:用于视频摘要的多层时空网络
这次向大家分享的工作是我所负责团队在国际人工智能多媒体顶会 ACM MM 2022 (CCF-A)发表的文章:Multi-Level Spatiotemporal Network for Video Summarization。该工作目前已经在阿里云主要业务落地并取得了显著的线上效果提升。
论文地址:https://dl.acm.org/doi/abs/10.1145/3503161.3548105
目前大多数视频摘要网络和生成算法无法很好应用于具有大量冗余信息的长镜头视频,为此我们研发了基于产业长镜头视频的深度模型 Multi-Level Spatiotemporal Network for Video Summarization(MLSN)。 该方法很好地解决了产业视频摘要应用的问题,并且在主流的公共数据集上做到了 SOTA 表现。
文章的主要贡献如下:
- 提出了一种适用于不同时长镜头的视频摘要任务架构,包括:通过多层时空特征表征灵活地捕获和容纳不同时空粒度的语义信息;通过生成模块使用融合的多层时空特征分数;使用新提出的 DKFS 算法生成视频摘要。
- 提出了一种局部偏序相对损失函数(LRL),该损失函数基于连续时空关系下的帧在语义信息上更局部连续,更具可比性的特点,引入帧中的局部偏序关系作为监督信息。该损失函数与现有方法相比不再只专注于比较没有局部时空关系的帧,大幅提高了视频帧得分间的可比性。
- 我们提出了 DKFS 的摘要生成算法,该算法在每个镜头中选择不同的关键片段作为视频摘要候选片段,而不是像基于 DP 的算法那样使用整个(具有大量冗余信息)镜头作为候选片段,解决了长镜头视频摘要场景的痛点。
- 我们的方法在广泛使用的基准数据集 SumMe 和 TVSum 上达到了 SOTA 表现,实验结果表明其达到了 SOTA 表现,并在阿里云产业应用场景中表现出来显著的效果提升。
1. 视频摘要任务简介
在搜索,推荐等需要进行大规模视频内容检索的架构中,目前的主流方案是基于深度模型的视频摘要算法。以阿里云的视频摘要场景为例,我们需要存在大量冗余数据的视频帧集合中,选择出相对比例较低的候选帧作为摘要内容,提供给用户进行查阅,需要满足在近线或者在线系统的性能要求。
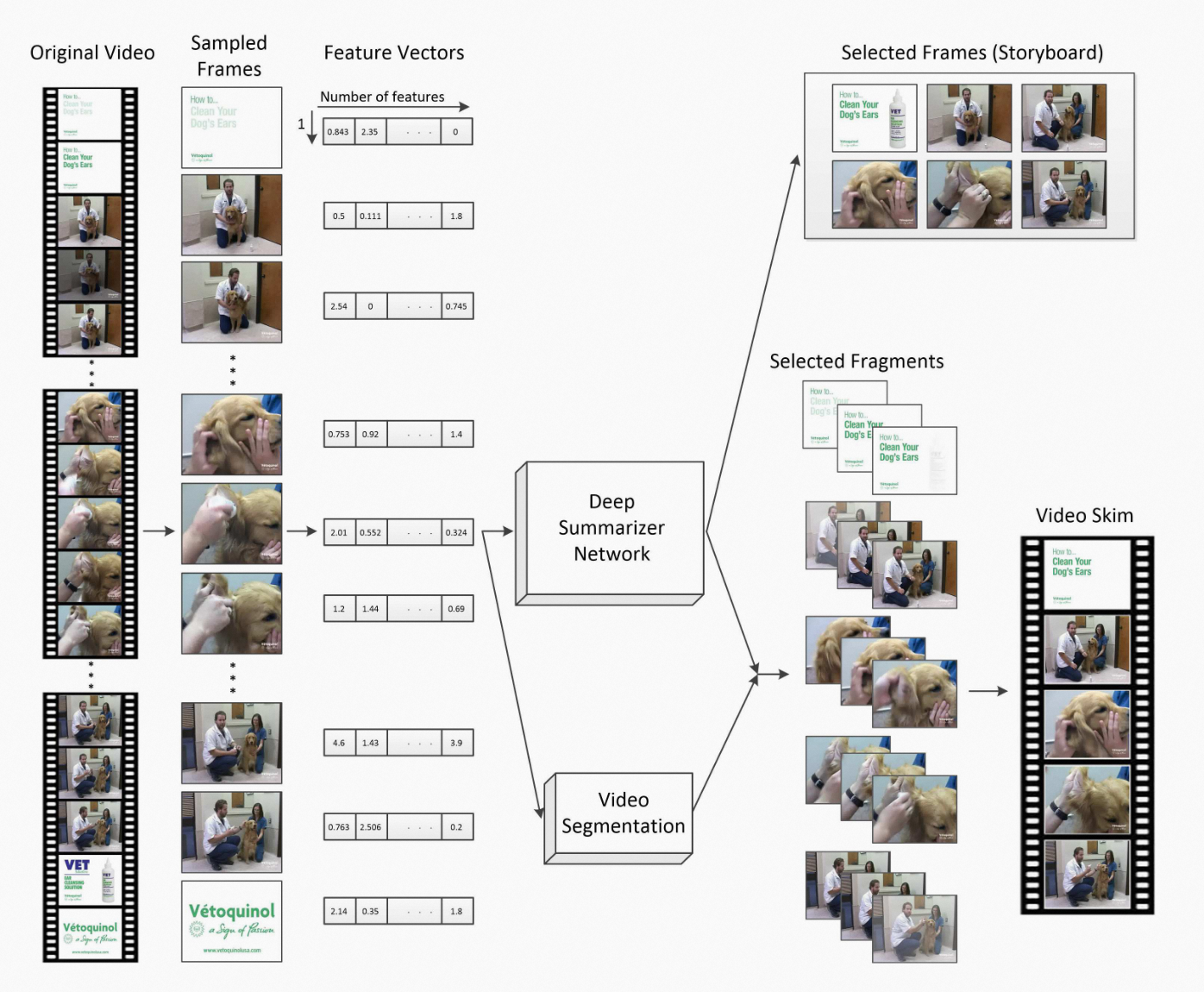
2. 发展历程
视频摘要的主流研究方向分为:
- 高光时刻检测:该任务将视频帧是否为高光时刻进行分类,从多模态信息处理方法的角度来看,现有的高光时刻检测方法可以分为三类:面向音频的方法、面向视觉的方法和或多模态方法。
- 视频摘要:相较于高光时刻检测,视频摘要的目标是生成整个视频的概要。 因此,视频摘要方法一般基于打分,更注重平衡趣味性、多样性和连贯性,来让剪辑内容更具代表性。目前公开的工作更侧重于对帧间相互依赖性进行建模,利用帧之间的顺序关系来构建时间特征,比如 RNN 及其变体,一些新的工作也基于注意机制进行建模。
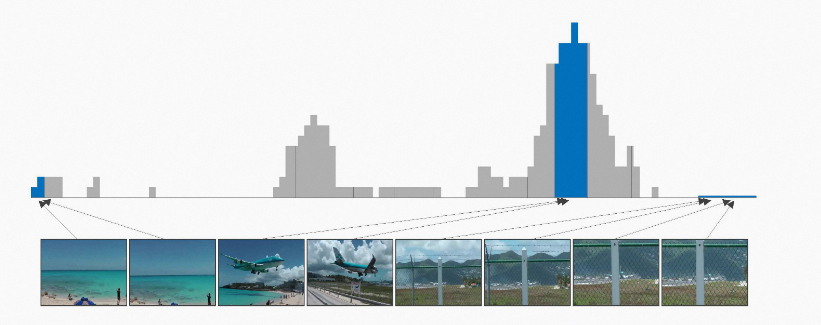
目前基于深度时序模型的视频摘要系统的效果目前已经得到了显著提升,但仍存在很多问题:
- 大多数公开工作都侧重于独立选择帧、镜头或片段,仅仅很少一部分方法利用了它们之间的关系,但即便如此,它们在特征表示方面存在一些弱点,在以长镜头并存在大量冗余信息的视频下表现较差。
- 目前主流的片段选择算法(DP)使用具有大量冗余信息的整个镜头作为候选片段,无法满足工业界个性化视频内容检索和推荐的需求,该问题在产业互联网应用中更为明显。
3. MLSN 模型
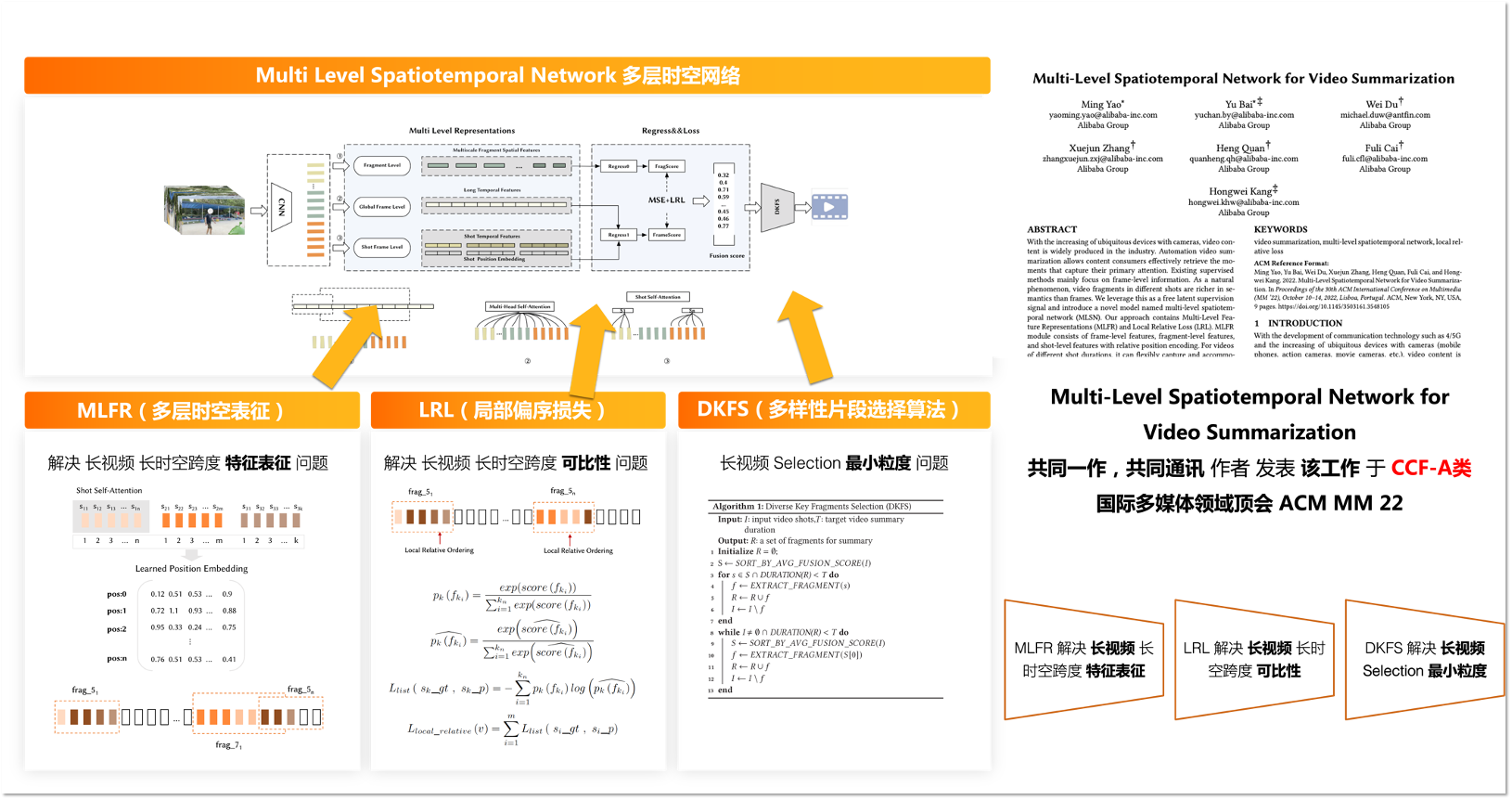
下图为我们方法的架构,给定一段视频,首先使用预训练的 CNN 网络来提取视频帧特征。随后我们通过片段、帧和镜头级别的特征表示生成 FragSocre 和 FrameScore,并将全局帧级特征和镜头级特征提供给它们相应的非线性回归层,以预测每帧的得分。类似地,我们将片段级特征提供给其非线性回归网络以预测每个片段的分数。最后通过局部相对损失(LRL)函数用来监督帧之间的偏序关系。 此外我们还介绍了一种名为 Diverse Key Fragments Selection (DKFS) 的算法作为面向长镜头的视频摘要片段优选策略。

3.1 多层时空特征表征(MLRF)
研究过程中我们发现人类在摘要一段视频时,通常会观看整个视频,然后回忆视频中的每个画面、片段和镜头,并根据各个片段的吸引力以及时空跨度下的内在联系来进行挑选。受此启发,我们提出了一个深度网络来模拟这样一个人工过程,面向镜头、片段和帧三个维度,设计一个多级特征表示模块,通过我们的融合模块将其转换为视频摘要的重要性分数。 这种网络结构可以帮助模型更好地帮助模型找到各个时间粒度下内容的跨时空联系,增强生成视频摘要片段的语义。
多层时空特征表征构建在三个不同的层次上,包括帧级、片段级和镜头级。
帧级特征:为了提取帧序列的时空特征,我们使用在 ImageNet 上预训练的 GoogLeNet(为了公平地和公开方法比较) 中 Pool5 层的输出作为帧向量,提供给 multi-head self-attention encoder layer 对具有较长时间跨度的全局帧的时间关系进行建模。
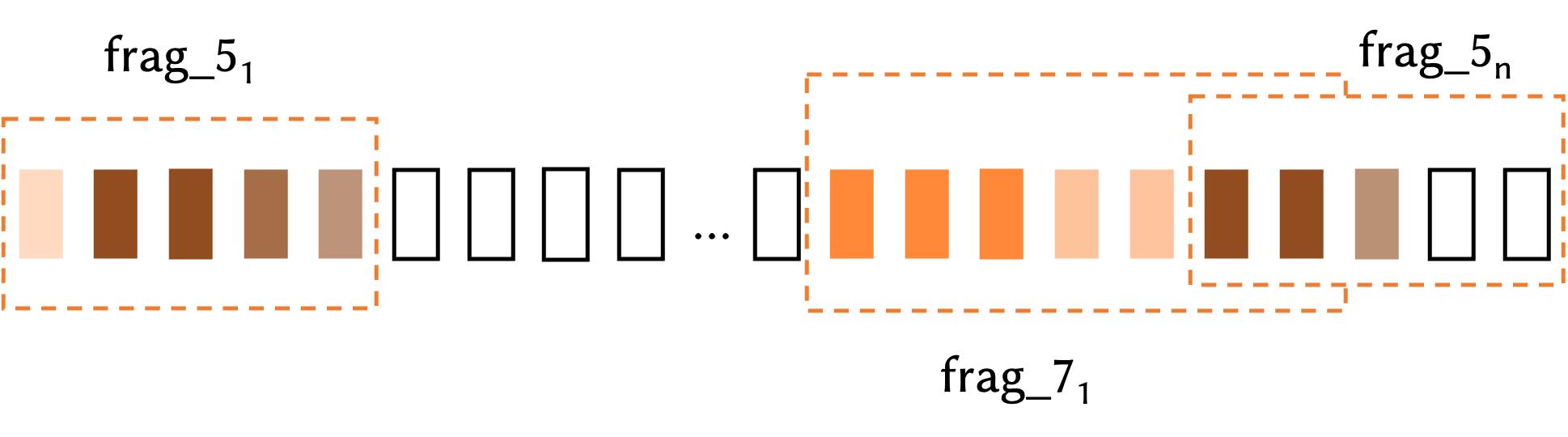
片段级特征:我们在所有帧上应用具有特定步长和窗口大小的滑动窗口,下图中介绍了片段级特征的主要思想。
镜头级特征:视频序列帧之间的相关性会随着时间距离的增加而衰减,从而对实验结果产生负面影响。 为了克服基于全局注意力的模型的不足,我们引入了具有镜头内帧相对位置的自注意力机制,使我们的模型能够感知帧的时序关系。 具体来说,我们将 shot self-attention with mask 和镜头级 learned position embedding 特征表示中作为局部偏序信息引入模型,下图中介绍了镜头级特征的主要思想。

3.2 局部偏序关系损失函数(LRL)
视频摘要任务标注者的主观性会导致评分标准(基本单位)的不一致,就此而言,标注的绝对分数不能准确代表帧质量的差异。因而我们借用连续时空关系下的帧在语义信息上更具局部连续性,从而更具可比性这一特点,提出了 LRL 损失函数,引入帧间局部偏序关系作为监督信号,提高在人工标注局限性下的视频帧间排序的可比性。

首先,我们保留了全局损失函数,来保留跨时空的偏序关系信号。
随后,我们创造性地利用 ListNet 的基本思想,通过 listwise loss 构成基于局部偏序关系的损失函数 LRL。
最终,我们的优化目标被定义为均方损失和局部相对损失的加权组合:
3.3 基于多样性的关键片段选择算法(DKFS)
当摘要任务需要实现具有多样性的关键片段选择而不是关键镜头选择时,现有(基于动态规划)的公开方法不再适用,因此我们提出了 DKFS 来解决产业互联网应用中的这个问题。
在初始化期间,我们设置片段的最大和最小片段时间限制以确保片段质量。 该过程分为两个阶段:
- 我们使用帧的平均得分作为镜头得分,然后按照得分对镜头进行排序。 当未达到目标摘要持续时间时,我们通过滑动窗口为每个镜头选择得分最高的片段。 这一步是为了保证视频摘要结果的多样性。
- 我们根据镜头中剩余帧的平均得分重新计算和排序每个镜头,然后通过滑动窗口选择 top1 镜头的片段,循环往复直到满足目标时长。这一步是为了保证视频摘要结果的吸引力。

4. 模型效果评估

为了验证我们提出的方法的性能,我们采用了两个公共基准数据集(TVSum、SumMe)和自研场景数据将我们的模型与其他 SOTA 方法进行比较。
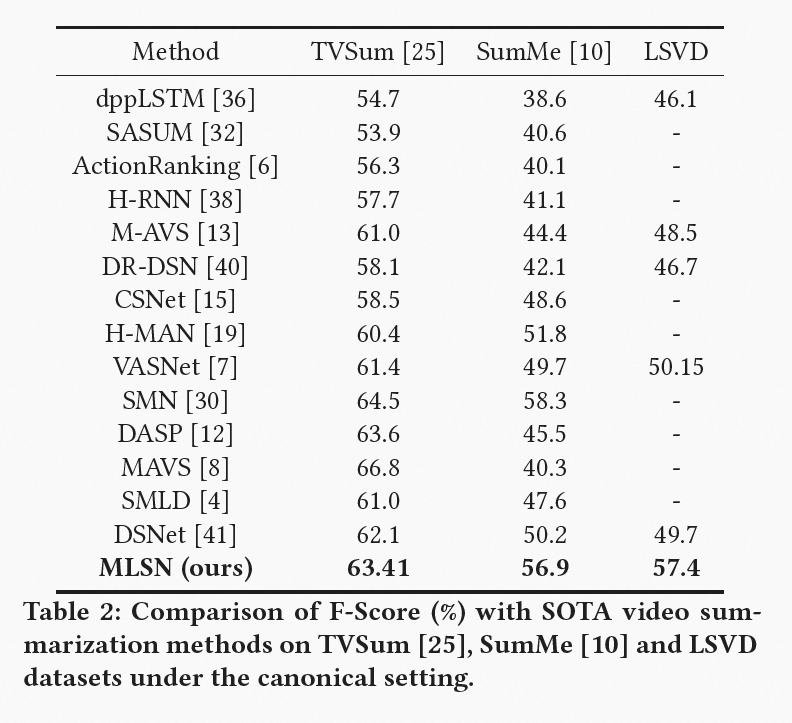
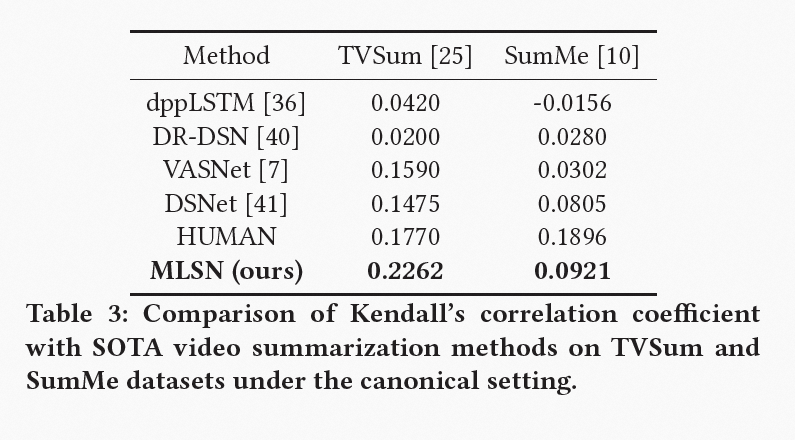
我们可以清楚地观察到我们的模型在两个数据集上都可以取得 SOTA 结果。SumMe 数据集上的更高性能增益是由于 TVSum 中的大多数方法已经非常接近人类性能。 我们认为这些收益是通过在不同粒度的视频帧上对时空特征进行建模和对局部偏序关系进行监督来提供的。
5. 总结
本文向大家详细介绍了阿里云视频摘要 SOTA 模型 MLSN。我们首先通过提取帧级特征、片段级特征和镜头级特征等多级特征,提出了一种用于视频摘要的新模型 MLSN,这种机制使我们的方法能够从多粒度中学习特征表示。 其次,我们引入了局部偏序相对损失函数,使我们的模型能够获得视频中的局部高质量帧。 第三,我们介绍了一种称为 Diverse Key Fragments Selection(DKFS)的摘要生成算法,该算法已经广泛应用于我们自己的产品中,以满足行业对多样性的需求。为了验证我们模型的效率,我们在规范设置中对两个基准数据集(TVSum 和 SumMe)进行了大量实验,实验结果表明了我们模型性能的先进性。近年来,MLSN 已经在阿里云的业务上得到应用并取得了显著的效果提升,我们后续的研究工作主要围绕以 spot light 为 query 的端到端视频摘要系统,敬请关注。
6. 团队介绍 & 致谢
特别要感谢项目中参与和给予支持的所有相关同学:秦宓,宗预,曾几,松昀和沐子对该工作的贡献。尤为感谢秦宓的悉心指导和大力支持。

相关文章
- 发现 Linux SpaceFM 文件管理器的威力
- 夯实数据智能底座 共筑数字经济发展“新基石”
- 五分钟教你使用console.log发布公司的招聘信息
- 微软发布 Windows 11 Beta 预览版 Build 22621.1250 和 22623.1250 (KB5023008)
- Windows 11 学院:在 Windows 11 Build 25290 上如何为文件管理器启用标签页拖拽支持
- 微软Windows 11 Dev 预览版 Build 25290 发布:带来新的开始菜单提醒角标
- 微软正用全屏通知提醒 Windows 10 用户免费升级 Windows 11,要点击 5 次才能退出
- Linux Mint 21.2 将于 6 月发布:改进登录屏幕,优化 Pix 图像管理程序等等
- 字节面试也会问SPI机制?
- 微软正式停售 Windows 10 产品密钥 / 许可证:继续提供 ISO 镜像下载,推荐用户升级 Windows 11
- 用复古电脑程序 Toy CPU 学习低级编程
- Windows 11 新功能泄露:现代音量合成器、实验工具和新的文件管理器
- 微软 Windows 11 文件资源管理器全新设计曝光:UI 迎来大修,整合 Microsoft 365
- 对比Pandas,学习PySpark大数据处理
- 微软宣布为Windows 11 21H2设备开启自动更新到22H2版本
- 互联网都在说降本增效,小红书技术团队是怎么做的?
- 微软将继续提供 Windows 10 ISO 镜像下载,即将停售产品密钥 / 许可证
- 微软宣布为Windows 11 21H2 设备开启自动更新到 22H2 版本
- 面试突击:Properties和Yml有什么区别?
- 微软 Windows 11 Beta 预览版 22621.1245 和 22623.1245 (KB5022358) 发布