
GitLab:因“大脑分裂问题” 5台PostgreSQL 3台彻底趴下
数据库复制故障让五台 PostgreSQL 服务器中的三台彻底趴下。
在一起典型的故障事件中,GitLab昨天无意中触发了数据库故障切换,因此降低了性能。
由此引发的“大脑分裂问题”让这家代码收集网站试图靠单单一台数据库服务器postgres-02来服务广大用户,同时竭力恢复另外三台数据库服务器。
这个问题最初出现在美国时间周四凌晨1:30左右,因此而来的重构工作仍在继续之中。
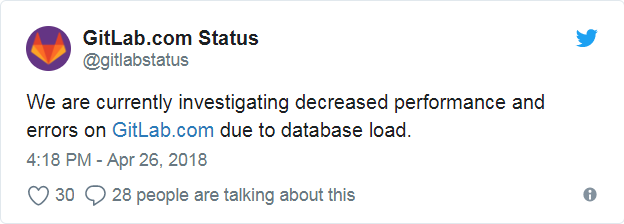
GitLab.com的推文内容如下:
由于数据库负载,我们目前正在调查GitLab.com上的性能下降和错误。
意外的故障切换被触发后,亚历克斯•汉塞尔卡(Alex Hanselka)写道,虽然服务器群“继续追随真正的主服务器”,但这起事件显然令人痛苦:
“由于postgres-01是出岔子的主服务器,我们关闭了它。我们在调查时发现,postgres-03和postgres-04都试图追随postgres-01。正因为如此,我在写这个问题单(issue)时,我们正在postgres-03上重构复制内容,完成后又在postgres-04上重构复制内容。”
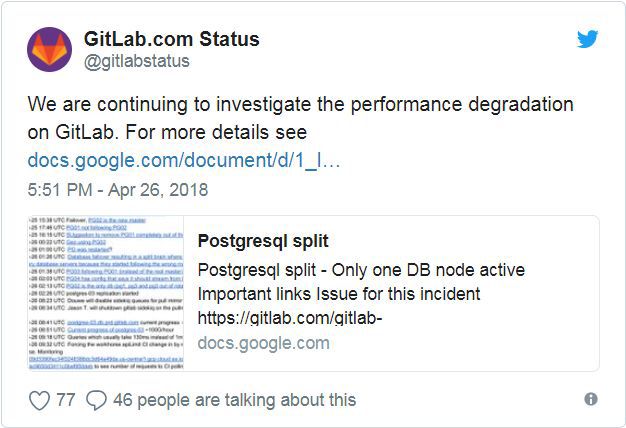
我们在继续调查GitLab上的性能下降问题。想了解详情,请参阅:https://docs.google.com/document
影响性能的还有备份(由于故障切换之前没有完整的pg_basebackup,所以需要备份);由于Sidekiq集群导致庞大的查询,GitLab只好关闭了该集群。
问题刚出来时就是这个情况:近20个小时后,故障工单还没有完结。
一开始,postgres-03的备份以每小时75GB的速度执行,直到23:00(晚上11点)后才完成。仍有其他数据库任务需要完成,但是从安德鲁•纽迪盖特(Andrew Newdigate)的帖子来看,性能开始恢复正常。

自21:30 UTC以来,持续集成/持续交付(CI/CD)队列恢复常态。现在管道以平常的速度来加以处理。
这里还附有时间表:https://docs.google.com/document
至少备份奏效了:2017年2月,备份故障让数据复制错误雪上加霜:“所以换句话说,在部署的5种备份/复制方法中,没有一个可靠地运行或一开始就设置好。”
在一台登台服务器(staging server)上发现了丢失的数据;作了深刻的反复之后,营销副总裁蒂姆•安格拉德(Tim Anglade)告诉IT外媒The Register,他深知GitLab的重要性,这是“对许多人的项目和公司来说很重要的网站。”
不得不说,切实有效的备份至少表明已汲取了一些经验教训。
相关文章
- Redis缓存的特殊用法以及与本地缓存一起构建多级缓存的实现
- 振弦采集模块配置工具VMTool通用串口调试模块
- Mysql入门基础,增删改查
- 使用管控平台管理redis集群
- 系统分析师案例必备知识点汇总---2023系列文章四
- 热点综述 | 肿瘤微环境中的细胞间通信推断和分析:数据资源和计算策略
- 故障分析 | 库表名-大小写不规范,运维两行泪
- 空转工具盘点 | 空间转录组细胞类型聚类方法综合比较
- 故障分析 | cassandra 集群数据故障转移
- 技术分享 | MySQL Shell 收集 MySQL 诊断报告(上)
- 超详细 | 生物医学研究和临床应用中scRNA-seq的数据分析指南
- 使用Python+Opencv从摄像头逐帧读取图片保存在本地
- 技术分享 | Redis 持久化之 RDB 与 AOF
- 技术分享 | ClickHouse & StarRocks 使用经验分享
- Redis和MySQL如何保持数据最终一致性
- 01.Java面试都问啥?
- 如何免费系统化入门数据科学?
- 数据仓库(10)数仓拉链表开发实例
- Arcgis中图像裁剪
- ArcGIS如何拼接两张栅格图像