
MySQL不为人知的主键与唯一索引约束
2023-03-14 22:23:30 时间
今天和大家简单聊聊MySQL的约束主键与***索引约束:
PRIMARY KEY and UNIQUE Index Constraints
文章不长,保证有收获。

触发约束检测的时机:
- insert
- update
当检测到违反约束时,不同存储引擎的处理动作是不一样的。
如果存储引擎支持事务,SQL会自动回滚。
例子:
- create table t1 (
- id int(10) primary key
- )engine=innodb;
- insert into t1 values(1);
- insert into t1 values(1);
其中第二条insert会因为违反约束,而导致回滚。
通常可以使用:
- show warnings;
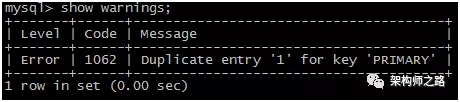
来查看违反约束后的错误提示。
如果存储引擎不支持事务,SQL的执行会中断,此时可能会导致后续有符合条件的行不被操作,出现不符合预期的结果。
例子:
- create table t2 (
- id int(10) unique
- )engine=MyISAM;
- insert into t2 values(1);
- insert into t2 values(5);
- insert into t2 values(6);
- insert into t2 values(10);
- update t2 set idid=id+1;
update执行后,猜猜会得到什么结果集?
- 猜想一:2, 6, 7, 11
- 猜想二:1, 5, 6, 10
- .
- .
- .
都不对,正确答案是:2, 5, 6, 10
- ***行id=1,加1后,没有违反unique约束,执行成功;
- 第二行id=5,加1后,由于id=6的记录存在,违反uinique约束,SQL终止,修改失败;
- 第三行id=6,第四行id=10便不再执行;
画外音:这太操蛋了,一个update语句,部分执行成功,部分执行失败。
为了避免这种情况出现,请使用InnoDB存储引擎,InnoDB在遇到违反约束时,会自动回滚update语句,一行都不会修改成功。
画外音:大家把存储引擎换成InnoDB,把上面的例子再跑一遍,印象更加深刻。
另外,对于insert的约束冲突,可以使用:
- insert … on duplicate key
指出在违反主键或***索引约束时,需要进行的额外操作。
例子:
- create table t3 (
- id int(10) unique,
- flag char(10) default 'true'
- )engine=MyISAM;
- insert into t3(id) values(1);
- insert into t3(id) values(5);
- insert into t3(id) values(6);
- insert into t3(id) values(10);
- insert into t3(id) values(10) on duplicate key update flag='false';
insert执行后,猜猜会发生什么?
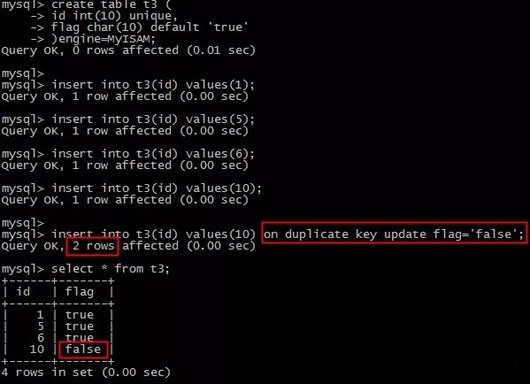
插入id=10的记录,会违反unique约束,此时执行update flag=’false’,于是有一行记录被update了。
这相当于执行:
- update t3 set flag='false' where id=10;
仔细看,insert的结果返回,提示:
Query OK, 2 rows affected
有意思么?
画外音:本文所有实验,基于MySQL5.6。
总结:
对于主键与***索引约束:
- 执行insert和update时,会触发约束检查
- InnoDB违反约束时,会回滚对应SQL
- MyISAM违反约束时,会中断对应的SQL,可能造成不符合预期的结果集
- 可以使用 insert … on duplicate key 来指定触发约束时的动作
- 通常使用 show warnings; 来查看与调试违反约束的ERROR
互联网大数据量高并发量业务,为了大家的身心健康,请使用InnoDB。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】

相关文章
- 通过 AWS Lake Formation FindMatches 转换匹配患者记录
- 利用 AWS Lake Formation 探索元数据:第 1 部分
- EMR 上的 Spark 作业优化实践
- 在生产中结合使用 Amazon Redshift Spectrum、Amazon Athena 和 AWS Glue 与 Node.js
- 使用 API Gateway 监管客户端与 Apache Kafka 之间的交互
- 使用 Amazon Athena 访问跨账户 AWS Glue 数据目录
- 使用 AWS Glue 和 Amazon Redshift 分析您的 Amazon S3 支出
- 使用 Apache Atlas on Amazon EMR 进行元数据分类、沿袭和发现
- 使用 Palo Alto Networks 的 Prisma Cloud 计算版本扫描 AWS 镜像仓库ECR
- 在最大程度上优化 Amazon Redshift 上的数据提取与报告性能
- 使用 Amazon EC2 Spot 实例和 Amazon EMR 运行 Apache Spark 应用程序的最佳实践
- 使用 Amazon Redshift 物化视图,加快查询执行速度
- 现已推出:Amazon ElastiCache Global Datastore for Redis
- AWS Glue 增量数据加载和优化的 Parquet 写入器
- Verizon Media Group 如何将本地的 Apache Hadoop 和 Spark 迁移到 Amazon EMR
- 动态扩展 Amazon EMR 集群上的存储
- 利用 Amazon Redshift Spectrum 使用嵌套数据类型
- Mysql 数据库迁移至 Amazon RDS 最佳实践
- 使用 Apache Airflow、Genie 和 Amazon EMR 编排大数据工作流:第 2 部分
- Python gensim基础实战