
Redis中主从、哨兵、分片集群入门篇
redis的应用场景很多,不管是在数据存储还是分布式锁等方面,本篇文章主要对主从、哨兵、分片集群做一个简单的分析,不会讲的太深。

主从模式
主从模式的应用场景有点类似于数据库的主从集群,主从往往是为了读写分离、backup 等目的才使用的,所谓主从模式简单的说就是有多个节点,里面包含主节点和从节点,结构如下图:
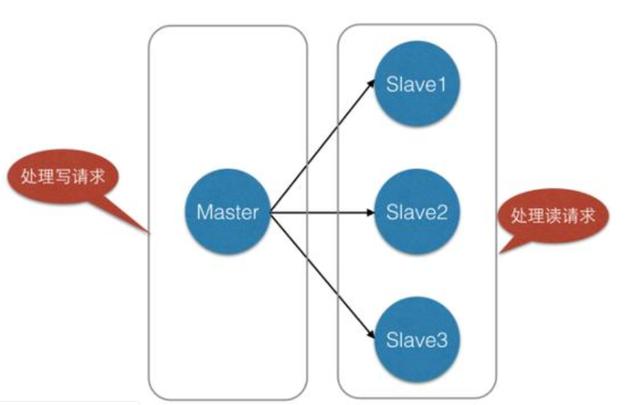
从节点在保持连接后每隔一个时间节点会主动的和主节点通信并发送同步请求,而后进行同步。
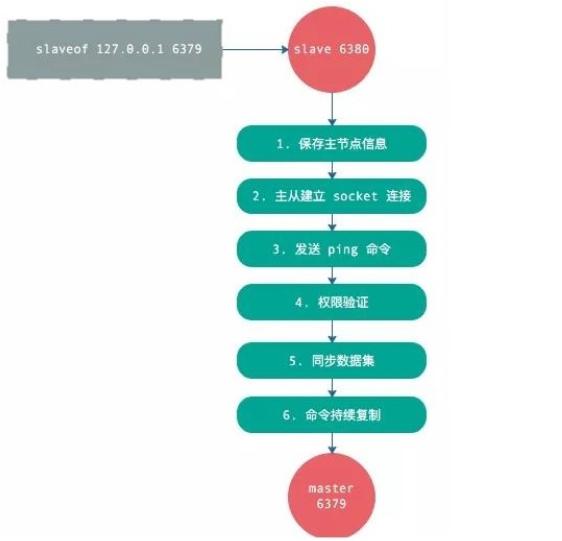
其实在整个流程中,最需要主要的就是数据间的同步,主要的同步方式有两种也就是全量同步和增量同步。
全量同步:全量同步一般使用在从节点刚接入主节点时进行全量复制,当然你也可以根据你的需求进行主动的全量同步
增量同步:Redis增量复制是指从节点初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令,一般使用缓冲区、队列(先进先出)等方式辅助进行增量的同步。
哨兵模式
哨兵模式是为了保证redis的高可用产生的架构,简单地说就是通过构建1个或多个哨兵对节点进行监控,如果master发生故障下线之后,哨兵之间会进行投票,在2.8之后使用的是Raft算法进行master选举,关于这个算法其实这个算法也应用于zookeeper和某些网络拓扑中,简单说就是在选举的过程可通信节点达成共识后那个投票选举master,而后进行故障转移操作。
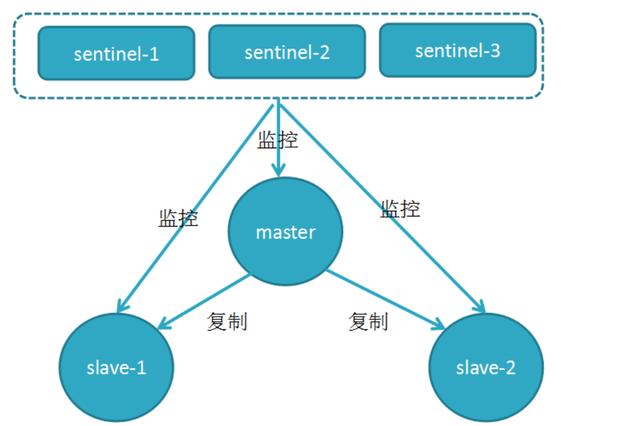
哨兵是作为一个进程单独运行在redis中,哨兵之间也是通过该进程进行通信的,这一点和zookeeper的原理也是类似的,假设一个6节点3个哨兵的集群的结构应该如下图:
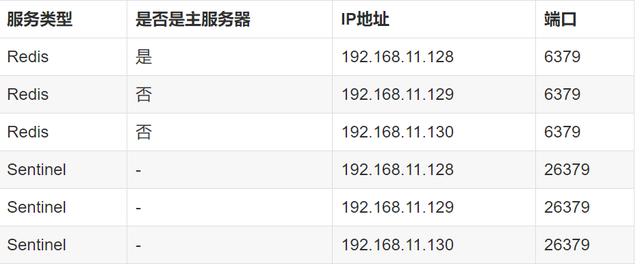
那么哨兵是如何监控master下线的呢?
前面也有看到哨兵之间会进行集群的检测和哨兵之间的互相监测,但是哨兵不用做什么配置,因为哨兵巧妙的利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点,在监测master方面一般分为两种:
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过命令互相交流之后, 得出的服务器下线判断。 一个 Sentinel 可以通过向另一个 Sentinel 发送命令来询问对方是否认为给定的服务器已下线。
分片集群
在上面的部分不管redis主从,还是高可用的 sentinel 哨兵模式。我们所做的这些工作只是保证了数据备份以及高可用,目前为止我们的程序一直都是向1台redis写数据,其他的redis只是备份而已。在实际使用中一般分片集群使用较多,我为什么要特意强调是分片集群呢,其实上面所说的主从和哨兵都是集群但是他们都是备份式的集群,实际数据是由一台进行控制的,所谓分片其实是将不同的数据按照一定的分布规则分布在不同的机器上

在redis中,我们的应用在存取数据的时候需要根据一定的算法(一致性hash)进行计算和存取 ,那么在redis中如何实现数据分片的呢? 首先Redis至少存在三个数据分片,每个分片称为master,假设整个cluster有N个节点,那么每个节点都和其他N-1个节点保持连接和心跳,节点之间相互通信主要确认节点是否存活、节点的数据版本、投票选择新的master等
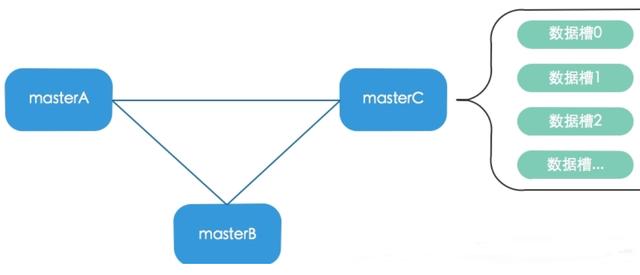
那么我们最终的集群结构大致如下:
相关文章
- Amazon QuickSight 宣布正式发布 ML Insights
- Aurora, Mysql, Redshift 应用场景和成本分析
- 使用 Open Distro for Elasticsearch 运行 Rally
- Amazon SageMaker Ground Truth 不断简化标记工作流
- 开源新闻摘要:2019 年 4 月 22 日
- python enumerate用法总结
- java连接MySQL
- 善始方能善终- Amazon Redshift 表设计探秘
- Java_day4
- 借助 AWS 技术改善临床试验结果 | AWS 大数据博客
- 使用 SIOS Protection Suite 在 AWS 上部署高可用 SAP 系统
- 新的 Amazon S3 存储类 – Glacier Deep Archive
- 各种场景下从MySQL数据库迁移到Amazon Aurora
- Amazon Aurora 冉冉升起:我们是如何设计原生云关系数据库的
- 使用AWS Sagemaker训练因子分解机模型并应用于推荐系统
- PYTHON1.day20
- 如何针对整合工作负载规划和优化兼容 MySQL 的 Amazon Aurora
- Python MySQL数据库交互
- 借助 Lambda,结合使用 DynamoDB 和 Amazon Elasticsearch | AWS 初创公司博客
- 使用 iData 在 AWS 云上实现高性能的 Oracle RAC 集群