
聊一聊如何利用索引提高性能
在关系数据库中,表中数据普遍以无序的状态存储在磁盘上,在没有相应索引时,若要对表中数据进行查询,就只能全表检索,将所有记录挨个读取,然后和查询条件进行比较,显然,这种方式会导致大量的磁盘 I/O 操作和 CPU 计算,消耗大量的系统时间,因此,建立索引就成了一个必须考虑的选项。

使用 CREATE INDEX [索引名] on 表名 (列名,……) 语句可以为表中数据建立最常用的键值索引,而键值索引的实现大都采用 B+ 树数据结构,它有以下一些性质:
1、 是一棵平衡树,即从根节点到叶子节点的深度相差不超过 1;
2、 非叶子节点只保存键值和指向子节点的指针,不保存数据;
3、 叶子节点保存键值、对应记录的地址及叶子节点的链表指针,链表中叶子节点是键值有序的
但这些性质就一定能保证查询性能满足用户的需求吗?下面,我们以对银行账户进行时间段查询为例,探讨索引的性能问题。
为了方便说明问题,我们在这里把 B+ 树简化为 3 叉 B+ 树,以账号和交易日期作为键值,如下图所示:
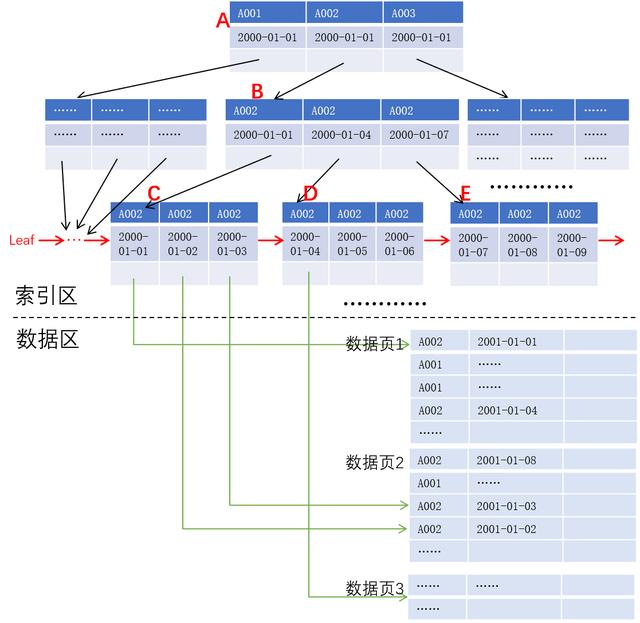
如果我们要查询账号 A002 从 2000-01-01 到 2000-01-07 的交易流水,数据库系统会首先要查找账号为 A002、日期不早于 2000-01-01 的键值所在的叶子节点,结果是依次读取索引块 A、B、C,然后找出索引块 C 中满足条件的键值对应的记录地址并读出记录返回,若索引块 C 中最后一个日期早于或等于 2001-01-07,则可以根据叶子节点的链表直接读取索引列 D,以此类推,直到某个索引块的某个日期比 2001-01-07 大为止。
观察上述过程,我们发现 2000-01-01 对应的记录在数据页 1,2000-01-02 和 2000-01-03 对应的记录在数据页 2,2000-01-04 对应的记录则在数据页 3,4 条记录需要读取 3 个数据页,极端情况下甚至任意一条记录都在不同的数据页,而此时如果数据区中记录已按键值序存储则可以显著减少磁盘 IO。更进一步,如果记录数据直接保存在叶子节点,则可以减少查询过程中索引页与数据页之间的跳读,这对于机械硬盘的性能影响尤甚。
这些问题对于集算器的组表来说,可以非常轻松地得到解决。
我们还是以股票交易数据为例讲解组表的使用。
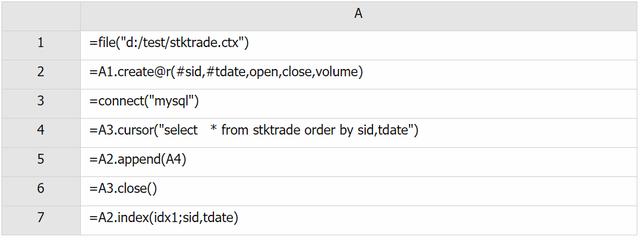
A2: 创建数据结构为 (sid,tdate,open,close,volume) 的组表,且指定 sid 和 tdate 为键,@r 指定数据按行存储
A5: 将按 sid 和 tdate 有序的数据追加到组表中
A6: 以 sid 和 tdate 为键值建立索引 idx1
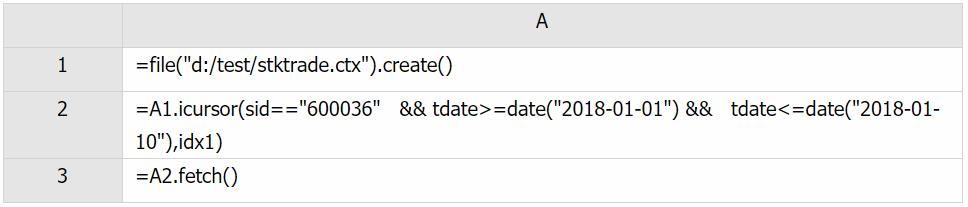
A1: 读取组表
A2: 定义根据索引 idx1 查询数据的游标
A3: 取出游标中的数据
在建立索引 idx1 时,也可以将所需的数据都储存在索引里,譬如要将 open、close、volume 这 3 列也储存在索引 idx1 里,只需将前面表格里的A2.index(idx1;sid,tdate)改为A1.index(idx1; sid,tdate; open,close,volume)即可,这样查询时就可以不读数据文件、只读取索引文件,使查询速度更快。
相关文章
- 数据孤岛是业务效率的无声杀手
- 2023展望:新的一年将给大数据分析领域带来什么?
- 阿里云ADB基于Hudi构建Lakehouse的实践
- 大数据在医疗保健领域的使用案例
- 微软增加说明:KB5021751 更新扫描已经 / 即将过时 Office 过程中不会触碰用户隐私
- 2022 Gartner全球云数据库管理系统魔力象限发布 腾讯云数据库入选
- 场景化、重实操,分享一个实时数仓实践案例
- Arctic的湖仓一体践行之路
- 分布式计算MapReduce究竟是怎么一回事?
- 淘系数据模型治理优秀实践
- 大数据分析对医疗保健的影响
- 当我们说大数据Hadoop,究竟在说什么?
- 2022年及以后大数据的五个发展趋势
- 网易严选离线数仓治理实践
- 2023 年数据治理趋势
- 一份“靠谱”的年度经营计划,你学会了吗?
- 漫谈对大数据的思考
- 测试一下,读懂数据的能力,你有吗?
- 用艺术的眼光探索数据之美
- 聊聊数据分析成果如何落地