
架构秘笈:使用MySQL模拟Redis
这年头,你看到的东西未必就是你认为的东西。一个mysql协议的后面,可能是tidb;一个linux机器后面,可能是一个精简的docker;你觉得xjjdog是个女的,但可能ta自己也不太清楚;而当你大呼php万岁的时候,可能是研发人员和你开个玩笑,重写了后缀,而后端用的却是java。
大家都知道redis速度快,但它的容量和内存容量有关,很容易达到瓶颈。有些互联网公司,直接使用redis作为后端数据库(在下佩服)。当业务量暴增,就面临一个redis容量和价格的权衡问题。改业务代码是来不及了,只好用一些持久化存储 ,来模拟redis的一些数据结构。
redis支持近十种数据类型,最常用的有5种。string、hash、zset、set、list等。本文将针对几种常见的数据结构,探讨一下常用操作的模拟实现。
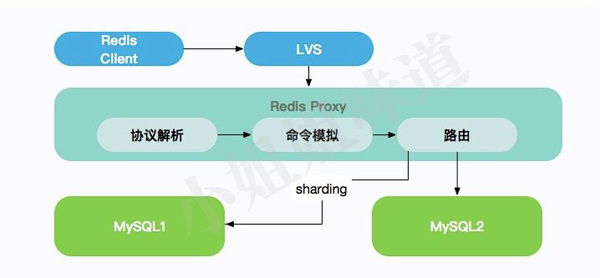
其实,我们所需要开发的,就是一个redis代理proxy。redis的客户端,连接上我们的代理之后,会进行协议解析。解析出来的命令,将会被模拟,然后根据配置的路由,定位到相应的mysql中。
也就是你所使用的redis,其实使用mysql来存储数据的。没有rdb,也没有aof。
Redis是文本协议
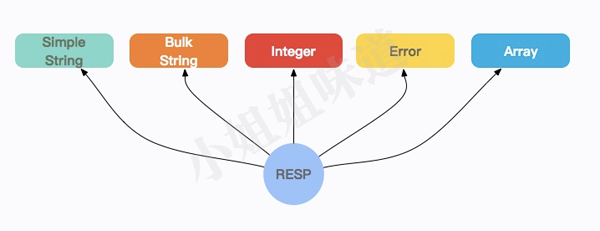
redis是文本协议,协议名称叫做RESP。RESP 是 Redis 序列化协议的简写。它是一种直观的文本协议,优势在于实现异常简单,解析性能极好。
如图,Redis 协议将传输的结构数据,可以总结为 5 种最小单元类型。每个单元结束时,统一加上回车换行符号 。
下面是几个规则:
- 单行字符串 以 + 开头;
- 多行字符串 以 $ 开头,后跟字符串长度;
- 整数值 以 : 开头,后跟整数的字符串形式;
- 错误消息 以 - 符号开头;
- 数组 以 * 号开头,后跟数组的长度;
比如,下面这个就是数组[9,9,6]的报文。
- *3
- :9
- :9
- :6
所以这个协议的解析和拼装,是非常简单的。拿netty来说,就有codec-redis 模块供我们使用。
实现:数据结构设计
在数据表的设计上,我们发现,kv和hash在效率上没有什么差别,因为它能够直接根据key定位到。
反倒是zset,由于有排序的功能,造成了很多操作的执行效率都不尽人意。
另外,由于我们不同的数据结构,是使用不同的表进行存储的。所以删除操作,要在每张表上都执行一遍。
kv设计
kv,即string,是redis里最基本的数据类型。一个key对应一个value,string类型的值最大能存储512MB。
设计专用的数据库表rstore_kv,其中,rkey是主键。
- rkey varchar
- val varchar
- lastTime bigint
set操作
- insert into rstore_kv("rkey","val","lastTime") values($1,$2,$3)
- on duplicate key update set "val"=$2,"lastTime"=$3
get操作
- select val from rstore_kv where "rkey" = $1
del操作
- delete from rstore_kv where "rkey" = $1
exists操作
- select count(*) as n from rstore_kv where "rkey" = $1
ttl操作
- select lastTIme from rstore_kv where "rkey" = $1
hash设计
hash 是一个键值(key=>value)对集合。hash 特别适合用于存储对象。
设计专用的数据库表rstore_hash,其中,rkey和hkey是联合主键。
- rkey varchar
- hkey varchar
- val varchar
- lastTime bigint
hset操作
- insert into rstore_hash("rkey","hkey","val","lastTime") values($1,$2,$3,$4)
- on duplicate key update set "val"=$3,"lastTime"=$4
hget操作
- select val from rstore_hash where "rkey" = $1 and "hkey" = $2
hgetall操作
- select hkey,val from rstore_hash where "rkey" = $1
hdel操作
- delete from rstore_hash where "rkey" = $1 and "hkey" = $2
del操作
- delete from rstore_hash where "rkey" = $1
hlen,hexists操作
- select count(*) as num from rstore_hash where "rkey" = $1
ttl操作
- select max(lastTIme) from rstore_hash where "rkey" = $1
zset设计
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。它的底层结构是跳跃表,效率特别高,但是会占用大量内存。
设计专用的数据库表rstore_zset,其中,rkey和member是联合主键。
- rkey varchar
- member varchar
- score double
- lastTime bigint
zadd操作
- insert into rstore_zset("rkey","member","score","lastTime") values($1,$2,$3,$4) on duplicate key update update set "score"=$3,"lastTime"=$4
zscore操作
- select score from rstore_zset where "rkey" = $1 and "member" = $2
zrem操作
- delete from rstore_zset where "rkey" = $1 and "member" = $2"
zcard,exists操作
- select count(*) as num from rstore_zset where "rkey" = $1
zcount操作
- select count(*) as num from rstore_zset where "rkey" = $1 and score>=$2 and score<=$3
zremrangebyscore操作
- delete from rstore_zset where "rkey" = $1 and score>=$2 and score<=$3
zrangebyscore操作
- select member,score from rstore_zset
- where "rkey" = $1 and score>=$2 and score<=$3 order by score asc,member asc
zrange操作
- select member,score from rstore_zset
- where "rkey" = $1 order by score asc offset $2 limit $3
zrank操作
- select rank from (select member,rank() over (order by "score" asc, "lastTime" asc) as rank from rstore_zset where "rkey" = $1 ) m where m."member"= $2;
ttl操作
- select max(lastTIme) from rstore_zset where "rkey" = $1
del操作
- delete from rstore_zset where "rkey" = $1
set设计
Redis的Set是string类型的无序集合。
设计专用的数据库表rstore_set,其中,rkey和member是联合主键。
- rkey varchar
- member varchar
- lastTime bigint
sadd操作
- insert into rstore_set("rkey","member","lastTime") values($1,$2,$3)
- on duplicate key update update set "lastTime"=$3
scard操作
- select count(*) as num from rstore_set where "rkey" = $1
sismember操作
- select member from rstore_set where "rkey" = $1 and "member" = $2
smembers操作
- select member from rstore_set where "rkey" = $1
srem操作
- delete from rstore_set where "rkey" = $1 and "member" = $2
del操作
- delete from rstore_set where "rkey" = $1
ttl操作
- select max(lastTIme) from rstore_set where "rkey" = $1
End
本篇文章仅仅模拟了最常用数据结构的最常用功能,有很多很多功能是不支持的,比较明显的就是分布式锁setnx等。所以这个proxy层的开发,要想做到ok,并不是那么简单。
同时,我们以一种模拟的视角,来看一下redis的数据结构,在关系型数据库中的表现形式。这样,更能够加深我们对redis的认识,明白它存在的价值。
相关文章
- CTO训练营耿志峰:大数据驱动网络反欺诈
- 为什么在大数据处理中Cassandra与Spark如此受欢迎?
- 三要点|解构小白入手数据分析的思维模式
- 数据分析应该要避免的6个错误
- MATLAB 数据分析方法(第2版)导读
- 小白学数据 | 28张小抄表大放送:Python,R,大数据,机器学习
- 关于集成建模,这有40个给数据科学家的技能测试题及解答
- 解密 Airbnb 的数据科学部门如何构建知识仓库
- 双11数据大屏背后:大规模流式增量计算及应用(附资料)
- 蹩脚数据科学家的10种现象
- Spark Streaming 数据清理机制
- AWS云数据仓库Redshift,让您的数据飞起来
- 灾难|有多少创业公司正依据虚荣数据分析
- 浅谈数据分析和数据建模
- 关于啤酒和尿布故事的真相
- 谈谈样本量选择背后的科学道理
- 从MySQL到Hive,数据迁移就这么简单
- 利用 MapReduce分析明星微博数据实战
- 奇云诺德CEO罗奇斌:解读测序密码与基因大数据
- 为什么云计算如此重要:是从移动第一演进到AI第一的第一步