
Github上近万Star!Codis,中国人开源的Redis集群部署解决方案
我们都知道Redis是单机单进程的,在之前的测试中,我们也知道Redis的单机性能是有限的,并且高性能的机器其实非常昂贵。一个好汉三个帮,分布式系统正是利用了多台普通计算器从而被大量互联网公司所使用,今天我们来聊一聊Redis集群的一种解决方案--Codis。
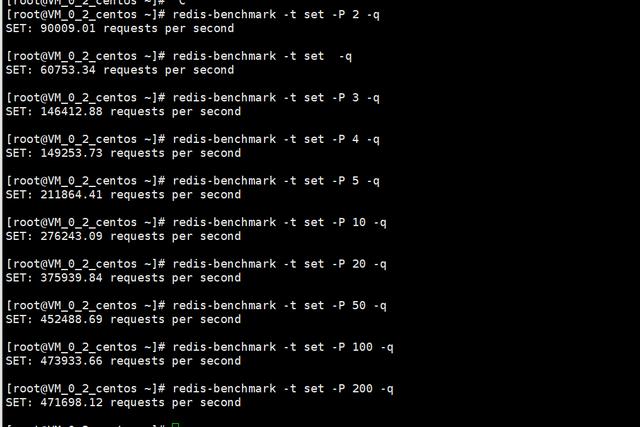
Codis,Github上面近万star,是一款由中国人开源的Redis集群解决方案,由前豌豆夹团队提供。Codis,它是一款Redis的Proxy,主要负责把Redis的请求分发到不同的Redis实例当中。
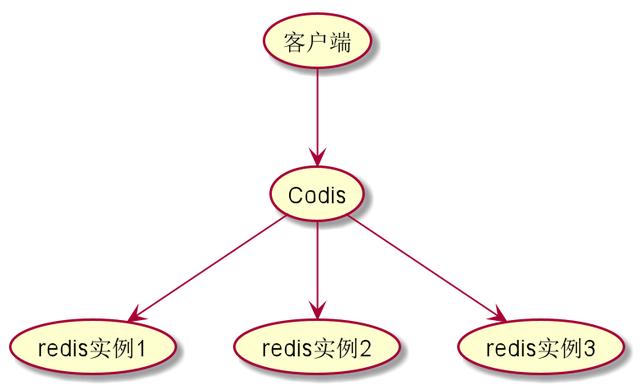
我们从一次get请求来解释一下,Codis是如何工作的。因为Codis代理了Redis服务,所以我们发起请求的时候,并不是请求到Redis-server所在的机器上,而是到Codis机器上,Codis机器再根据一定的路由规则进行分发,最终请求到Redis-Server的机器上,也就是说,如果我们使用一个mget请求,可能会到多台机器上。
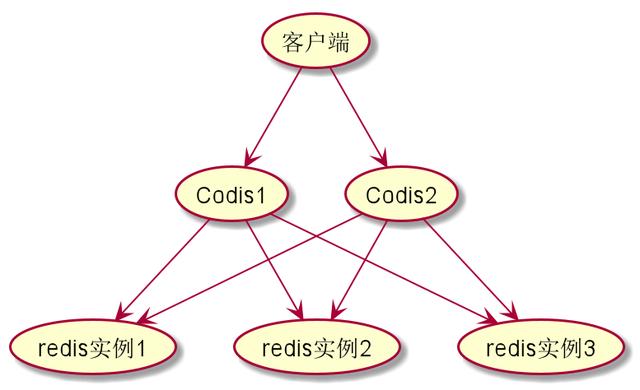
很显然,这样子Codis也会存在单点问题,好在Codis是一个无状态的服务,所以我们可以同时部署多个Codis实例。
Codis是如何把对应的key分配到不同机器的呢?奥秘就在于Codis的Slot,Codis切分出1024(可配置)个Slot,每个Slot会绑定不同的Redis实例,这里为什么要切分到1024个呢?这是一个不错的思考题?可以从扩容缩容方向进行考虑。
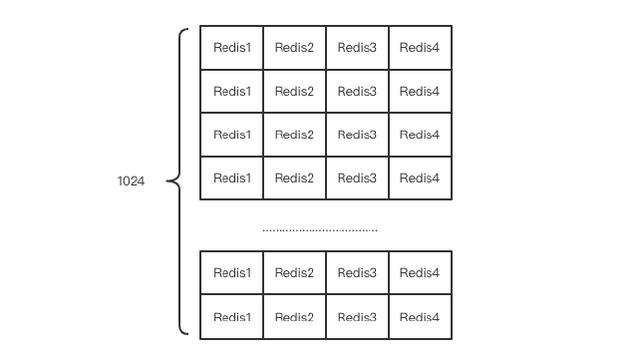
那么不同的Codis实力是如何同步Slot的数据呢?Codis的方法非常简单粗暴,那便是使用ZooKeeper。ZooKeeper不是发现服务么?怎么还能用来存储数据?ZooKeeper其实为每个目录提供了1M的存储空间,通过Quorum的2pc机制来做数据一致性。所以,ZooKeeper可以偷偷用来做数据小,吞吐不是那么大的数据存储。
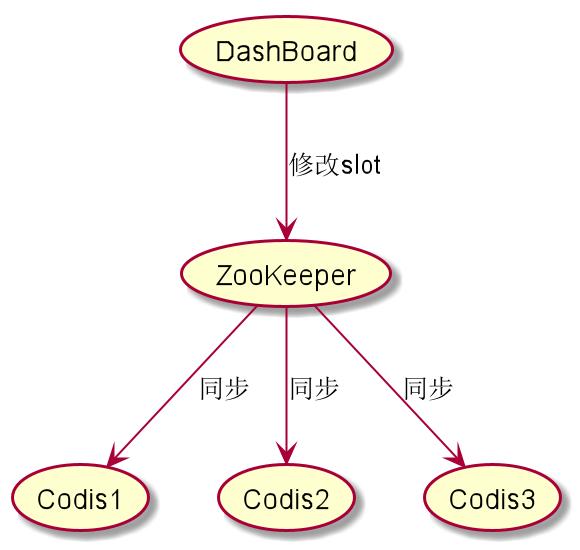
Codis提供一个Dashboard给用户编辑Slot的情况,当用户编辑的时候,会由Zookeeper分发给所有的Codis实例。优点
Codis非常的简单,无论是理解上,问题排查上还是部署上,都非常的简单。他把一些分布式一致性的东西交给了另外的开源方案Zookeeper去解决,自身非常轻量级。
缺点
由于Codis的数据是落在多台机器上的,所以,Redis的事务功能就不能使用了,对于批量查询接口,Codis需要到多台机器上去获取结果,这就不能保证数据的一致性。会存在这样的情况,使用Codis同时获取key1与key2,同时Update两者的值,可能获取到的Value1是新版本,而Value2为旧版本。
Codis会对Slot进行数据迁移,如果key-value的数据太小太大的话,就会影响迁移的效率,所以Codis官方推荐Codis的key-value大小不要超过1M。
由于Codis不是Redis的官方项目,所以每当Redis发布新版本的时候,Codis都会瑟瑟发抖,随着Redis退出自己的亲儿子Redis-Cluster,Codis的竞争力都在减弱。

今天我们对Github上面10kstar的Codis就介绍到这里,如果你有兴趣,欢迎关注我,我们后面再继续分析,谈一谈Codis中是如何做数据迁移的。
相关文章
- 春节大数据:节前返乡客流增长超40%,带火低线城市“微旅游”
- 数据分析八大模型:同期群模型
- littlefs原理分析--存储结构(一)
- 手把手教你使用 Pandas 读取结构化数据
- 微服务架构的数据库为什么喜欢分库分表?
- 一篇学会阿里面试问的 Select、Poll、Epoll 模型
- 函数计算异步任务能力介绍-任务触发去重
- 你知道疯狂的字典吗?
- 2021版的《华尔街之狼》该怎么拍?
- 如何写出一篇好的技术方案?
- 每个系统管理员都应该知道的六个 Linux 网络命令
- SpringBoot 整合 Elasticsearch 实现海量级数据搜索
- 别再说不懂索引了
- 数据分析结果虚有其表?可能是缺少这个思维!
- 你了解搜索引擎吗?
- 再有人问你什么是分库分表,直接把这篇文章发给他
- 你真的理解粘包与半包吗?三分钟搞懂它
- 一日一技:如何从大量商品数据里面找到降价商品?
- 每分钟写入六亿条数据,携程监控系统存储升级实践
- Redis 高可用之 Sentinel