
用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写。首先我们需要了解点ORM方面的知识。
ORM技术
对象关系映射技术,即ORM(Object-Relational Mapping)技术,指的是把关系数据库的表结构映射到对象上,通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
在Python中,最有名的ORM框架是SQLAlchemy。Java中典型的ORM中间件有: Hibernate, ibatis, speedframework。
SQLAlchemy
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
可以使用pip命令安装SQLAlchemy模块:
- pip install sqlalchemy
SQLAlchemy模块提供了create_engine()函数用来初始化数据库连接,SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
Pandas读写MySQL数据库
我们需要以下三个库来实现Pandas读写MySQL数据库:
- pandas
- sqlalchemy
- pymysql
其中,pandas模块提供了read_sql_query()函数实现了对数据库的查询,to_sql()函数实现了对数据库的写入,并不需要实现新建MySQL数据表。sqlalchemy模块实现了与不同数据库的连接,而pymysql模块则使得Python能够操作MySQL数据库。
我们将使用MySQL数据库中的mydb数据库以及employee表,内容如下:
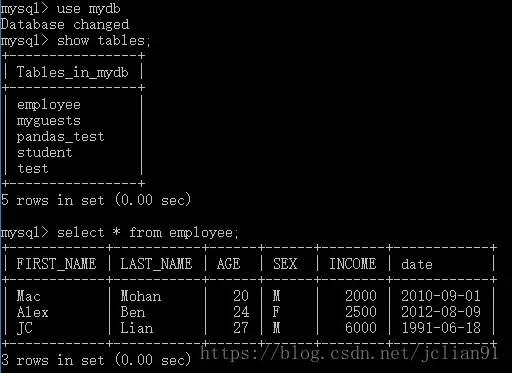
mydb数据库以及employee表
下面将介绍一个简单的例子来展示如何在pandas中实现对MySQL数据库的读写:
- # -*- coding: utf-8 -*-
- # 导入必要模块
- import pandas as pd
- from sqlalchemy import create_engine
- # 初始化数据库连接,使用pymysql模块
- # MySQL的用户:root, 密码:147369, 端口:3306,数据库:mydb
- engine = create_engine('mysql+pymysql://root:147369@localhost:3306/mydb')
- # 查询语句,选出employee表中的所有数据
- sql = '''
- select * from employee;
- '''
- # read_sql_query的两个参数: sql语句, 数据库连接
- df = pd.read_sql_query(sql, engine)
- # 输出employee表的查询结果
- print(df)
- # 新建pandas中的DataFrame, 只有id,num两列
- df = pd.DataFrame({'id':[1,2,3,4],'num':[12,34,56,89]})
- # 将新建的DataFrame储存为MySQL中的数据表,不储存index列
- df.to_sql('mydf', engine, index= False)
- print('Read from and write to Mysql table successfully!')
程序的运行结果如下:
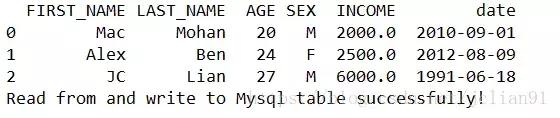
程序的运行结果
在MySQL中查看mydf表格:

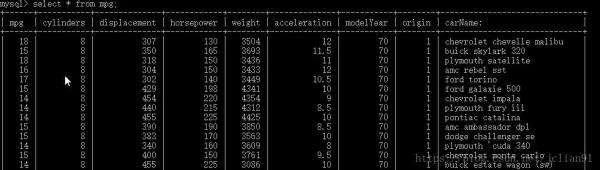
mydf表格
这说明我们确实将pandas中新建的DataFrame写入到了MySQL中!
将CSV文件写入到MySQL中
以上的例子实现了使用Pandas库实现MySQL数据库的读写,我们将再介绍一个实例:将CSV文件写入到MySQL中,示例的mpg.CSV文件前10行如下:
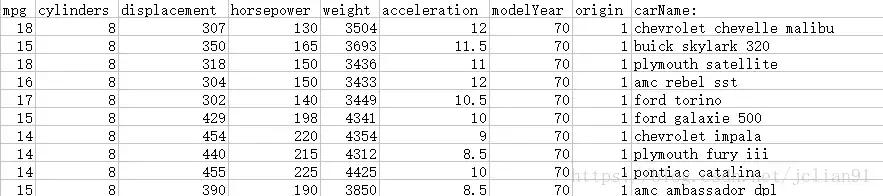
mpg.CSV文件前10行
示例的Python代码如下:
- # -*- coding: utf-8 -*-
- # 导入必要模块
- import pandas as pd
- from sqlalchemy import create_engine
- # 初始化数据库连接,使用pymysql模块
- engine = create_engine('mysql+pymysql://root:147369@localhost:3306/mydb')
- # 读取本地CSV文件
- df = pd.read_csv("E://mpg.csv", sep=',')
- # 将新建的DataFrame储存为MySQL中的数据表,不储存index列
- df.to_sql('mpg', engine, index= False)
- print("Write to MySQL successfully!")
在MySQL中查看mpg表格:
MySQL中的mpg表格
仅仅5句Python代码就实现了将CSV文件写入到MySQL中,这无疑是简单、方便、迅速、高效的!
总结
本文主要介绍了ORM技术以及SQLAlchemy模块,并且展示了两个Python程序的实例,介绍了如何使用Pandas库实现MySQL数据库的读写。程序本身并不难,关键在于多多练习。
相关文章
- 在大数据面前,每个人都是赤裸的
- 我从新冠数据里学到的四个数据科学基础知识
- 数据结构是噩梦?想要通过面试,你应该掌握它
- 大数据时代催生城市变革 ,数字科技助力智慧城市建设
- 大数据除了预测还能干啥?
- 隔离太无聊?每天一个数据科学项目,数据集都准备好了!
- 运用大数据提升疫情防控网络谣言治理能力
- 数据缺失、混乱、重复怎么办?最全数据清洗指南让你所向披靡
- AI 时代,还不了解大数据?
- “大数据”应有大信用
- 由浅到深学习Kafka:生产者消息分区机制原理
- 进阶必备!写给设计师的数据分析基础指南
- 一篇文章说清楚如何提升大数据质量
- 大数据可视化技术面临的挑战及应对措施
- Flink为什么比Spark快?大数据流处理的框架比较
- 大数据可视化技术面临的挑战及应对措施
- 为何Spark在编程界越来越吃香?Spark将成为数据科学家的统一平台
- 一场HBase2.x的写入性能优化之旅
- 被仰望和遗忘过的Cloudera是否能王者归来?
- 大数据分析系统Hadoop的13个开源工具,你知道几个?